什么是前端框架?首先我们需要划定边界:
- React 或者 Vue 究竟是库(library)还是框架(framework)?
实际上,无论是 React 也好,还是 Vue 也好,他们的核心是“构建 UI 的库”,提供了如下的功能:
- 基于状态的声明式渲染
- 提供组件化开发
当应用进一步的扩展,从简单的页面升级为了 SPA,此时意味着需要前端要有前端路由方案,React 阵营有 React-router,Vue 阵营有了 Vue-router,有了这些前端路由库。
随着应用复杂度的进一步提升,组件的数量越来越多,状态管理越来越复杂,因此就需要状态管理的库,React 阵营有 redux、react-redux,vue 阵营有 vuex、pinia。
我们发现,除了上面提到这些功能以外,还有很多其他的功能(构建支持、数据流方案、文档工具)React 和 Vue 本身其实是不支持的,所以说 React 和 Vue 本身只是专注于 UI 的渲染(构建 UI),因此我们可以将“包含库本身以及其他附加功能”的解决方案称之为框架(技术栈、全家桶),例如:
- UmiJS 这个就是一款框架,基于 React、内置路由、构建、部署等功能
- Next.JS 是一款框架,基于 React、支持 SSR、SSG 两大功能的服务端框架
在平时我们经常能够听到“React框架、Vue 框架”这样的说法,这个时候所指的 React 或者 Vue 往往指的是整个 React、Vue 本身以及它们周边的生态产品,因此这个可以算是一种约定俗成的说法。
在早期使用 jQuery 时代,那时的开发人员需要手动的去操作 DOM 节点,那个时候流行的还是 MPA 的模式,各个页面的 JS 代码量还在能够接受的范围。
但是随着单页应用的流行,客户端的 JS 代码量出现井喷,此时如果还是采用传统的手动操作 DOM 的方式,对于开发人员来讲有非常大的心智负担。
此时就出现了能够基于状态声明式渲染以及提供组件化开发模式的库,例如 Vue 和 React。这两者本质上仅仅是构建 UI 的库,但是随着应用的复杂度的提升,还需要前端路由方案、状态管理方案,所以有了 vue-router、react-router、vuex、redux 等周边生态产品。
Vue 或 React 和这些周边生态产品共同构成了一个技术栈,现在我们会将 React 或者 Vue 称之为框架,这可以算是一种约定俗成的说法。
一款现代前端框架,在它本身以及它的周边生态中,至少要包含以下几个方面:
- 基于状态的声明式渲染
- 支持组件化开发
- 客户端路由方案
- 状态管理方案
JSX 最早起源于 React 团队在 React 中所提供的一种类似于 XML 的 ES 语法糖:
const element = <h1>Hello</h1>经过 Babel 编译之后,就会变成:
// React v17 之前
var element = React.createElement("h1", null, "Hello");
// React v17 之后
var jsxRuntime = require("react/jsx-runtime");
var element = jsxRuntime.jsx("h1", {children: "Hello"});无论是 17 之前还是 17 之后,执行了代码后会得到一个对象:
{
"type": "h1",
"key": null,
"ref": null,
"props": {
"children": "Hello"
},
"_owner": null,
"_store": {}
}这个其实就是大名鼎鼎的虚拟 DOM。
React 团队认为,UI 本质上和逻辑是有耦合部分的:
- 在 UI 上面绑定事件
- 数据变化后通过 JS 去改变 UI 的样式或者结构
作为一个前端工程师,JS 是用得最多,所以 React 团队思考屏蔽 HTML,整个都用 JS 来描述 UI,因为这样做的话,可以让 UI 和逻辑配合得更加紧密,所以最终设计出来了类 XML 形式的 JS 语法糖
由于 JSX 是 JS 的语法糖(本质上就是 JS),因此可以非常灵活的和 JS 语法组合使用,例如:
- 可以在 if 或者 for 当中使用 jsx
- 可以将 jsx 赋值给变量
- 可以将 jsx 当作参数来传递,当然也可以在一个函数中返回一段 jsx
function App({isLoading}){
if(isLoading){
return <h1>loading...</h1>
}
return <h1>Hello World</h1>;
}这种灵活性就使得 jsx 可以轻松的描述复杂的 UI,如果和逻辑配合,还可以描述出复杂 UI 的变化。
使得 React 社区的早期用户可以快速实现各种复杂的基础库,丰富社区生态。又由于生态的丰富,慢慢吸引了更多的人来参与社区的建设,从而源源不断的形成了一个正反馈。
模板的历史就要从后端说起。
在早期前后端未分离的时候,最流行的方案就是使用模板引擎,模板引擎可以看作是在正常的 HTML 上面进行挖坑(不同的模板引擎语法不一样),挖了坑之后,服务器端会将数据填充到挖了坑的模板里面,生成对应的 html 页面返回给客户端。

所以在那个时期前端人员的工作,主要是 html、css 和一些简单的 js 特效(轮播图、百叶窗...),写好的 html 是不能直接用的,需要和后端确定用的是哪一个模板引擎,接下来将自己写好的 html 按照对应模板引擎的语法进行挖坑

不同的后端技术对应的有不同的模板引擎,甚至同一种后端技术,也会对应很多种模板引擎,例如:
- Java(JSP、Thymeleaf、Velocity、Freemarker)
- PHP(Smarty、Twig、HAML、Liquid、Mustache、Plates)
- Python(pyTenjin、Tornado.template、PyJade、Mako、Jinja2)
- node.js(Jade、Ejs、art-template、handlebars、mustache、swig、doT)
下面列举几个模板引擎代码片段
twig 模板引擎
基本语法
{% for user in users %}
* {{ user.name }}
{% else %}
No users have been found.
{% endfor %}
指定布局文件
{% extends "layout.html" %}
定义展示块
{% block content %}
Content of the page...
{% endblock %}blade 模板引擎
<html>
<head>
<title>应用程序名称 - @yield('title')</title>
</head>
<body>
@section('sidebar')
这是 master 的侧边栏。
@show
<div class="container">
@yield('content')
</div>
</body>
</html>EJS 模板引擎
<h1>
<%=title %>
</h1>
<ul>
<% for (var i=0; i<supplies.length; i++) { %>
<li>
<a href='supplies/<%=supplies[i] %>'>
<%= supplies[i] %>
</a>
</li>
<% } %>
</ul>这些模板引擎对应的模板语法就和 Vue 里面的模板非常的相似。
现在随着前后端分离开发的流行,已经没有再用模板引擎的模式了,后端开发人员只需要书写数据接口即可。但是如果让一个后端人员来开前端的代码,那么 Vue 的模板语法很明显对于后端开发人员来讲要更加亲切一些。
最后我们做一个总结,虽然现在前端存在两种方式:JSX 和模板的形式都可以描述 UI,但是出发点是不同
模板语法的出发点是,既然前端框架使用 HTML 来描述 UI,那么我们就扩展 HTML,让 HTML 种能够描述一定程度的逻辑,也就是“从 UI 出发,扩展 UI,在 UI 中能够描述逻辑”。
JSX 的出发点,既然前端使用 JS 来描述逻辑,那么就扩展 JS,让 JS 也能描述 UI,也就是“从逻辑出发,扩展逻辑,描述 UI”。
这两者虽然都可以描述 UI,但是思路或者说方向是完全不同的,从而造成了整体框架架构上面也是不一样的。
在 React 中,使用 JSX 来描述 UI。因为 React 团队认为UI 本质上与逻辑存在耦合的部分,作为前端工程师,JS 是用的最多的,如果同样使用 JS 来描述 UI,就可以让 UI 和逻辑配合的更密切。
使用 JS 来描述页面,可以更加灵活,主要体现在:
- 可以在 if 语句和 for 循环中使用 JSX
- 可以将 JSX 赋值给变量
- 可以把 JSX 当作参数传入,以及在函数中返回 JSX
而模板语言的历史则需要从后端说起。早期在前后端未分离时代,后端有各种各样的模板引擎,其本质是扩展了 HTML,在 HTML 中加入逻辑相关的语法,之后在动态的填充数据进去。如果单看 Vue 中的模板语法,实际上和后端语言中的各种模板引擎是非常相似的。
总结起来就是:
模板语法的出发点是,既然前端框架使用 HTML 来描述 UI,那么就扩展 HTML 语法,使它能够描述逻辑,也就是“从 UI 出发,扩展 UI,在 UI 中能够描述逻辑”。
而 JSX 的出发点是,既然前端使用 JS 来描述逻辑,那么就扩展 JS 语法,让它能够描述 UI,也就是“从逻辑出发,扩展逻辑,描述 UI”。
虽然这两者都达到了同样的目的,但是对框架的实现产生了不同的影响。
现代前端框架不仅仅是 React、Vue,还出现了像 Svelte、Solid.js 之类的框架,这些新框架相比 React、Vue 有什么样的区别呢?
现代前端框架,有一个非常重要的特点,那就是基于状态的声明式渲染。如果要概括的话,可以使用一个公式:
UI = f(state)
- state:当前视图的一个状态
- f:框架内部的一个运行机制
- UI:宿主环境的视图描述
这里和初中的一个数学代数知识非常相似:
2x + 1 = yx 的变化会导致 y 的变化,x 就被称之为自变量,y 就被称之为因变量。类比上面 UI 的公式,state 就是自变量,state 的变化会导致最终计算出来的 UI 发生变化,UI 在这里就是因变量。
目前在 React 中有很多 Hook,例如:
const [x, setX] = useState(0);比如上面的代码,我们就是定义了一个自变量
function App(){
const [x, setX] = useState(0);
return <div onClick={()=>setX(x+1)}>{x}</div>
}上面的 useState 这个 hook 可以看作是定义了一个自变量,自变量一变化,就会到导致依赖它的因变量发生变化,在上面的例子中,返回的 jsx 所描述的 UI 就是因变量。
因变量又可以分为两类:
- 没有副作用的因变量
- 有副作用的因变量
没有副作用的因变量
在 React 中,useMemo 就是定义一个没有副作用的因变量
const y = useMemo(() => x * 2 + 1, [x]);在上面的代码中,我们使用 useMemo 定义了一个没有副作用的因变量 y,y 的值取决于 x 的值,x 的值一变化,y 的值也会跟着变化
有副作用的因变量
在 React 中,可以使用 useEffect 来定义一个有副作用的因变量
useEffect(() => document.title = x, [x]);上面的代码依赖于自变量 x 的变化,当 x 发生变化的时候,会修改页面的标题,这就是一个副作用操作。
那么接下来,我们来总结一下:自变量的变化,会导致三种情况的因变量发生改变:
- 自变量的变化,导致 UI 因变量变化
function Counter(){
const [num, setNum] = useState(0);
return (
<div onClick={()=>setNum(num+1)}>{num}</div>
);
}- 自变量的变化,导致无副作用的因变量发生变化
function Counter(){
const [num, setNum] = useState(0);
const fiexedNum = useMemo(()=>num.toFiexed(2), [num]);
return (
<div onClick={()=>setNum(num+1)}>{fiexedNum}</div>
);
}- 自变量的变化,导致有副作用的因变量发生变化
function Counter(){
const [num, setNum] = useState(0);
useEffect(()=>document.title=num, [num]);
return (
<div onClick={()=>setNum(num+1)}>{num}</div>
);
}上面我们介绍了自变量和因变量,state 实际上就是自变量,自变量的变化直接或者间接的改变了 UI,上面的公式实际上还可以分为两个步骤:
- 根据自变量 state 计算出 UI 的变化
- 根据 UI 的变化执行具体的宿主环境的 API
以前端工程师最熟悉的浏览器为例,那么第二个步骤就是执行 DOM 相关 API,对于这个步骤来讲,不同的框架实际上实现基本是相同的,这个步骤不能作为框架分类的依据,差别主要体现在步骤一上面,这个(步骤一)也是针对目前各大框架的一个分类的依据。
接下来我们来看一个应用的示例:
该应用由三个组件组成
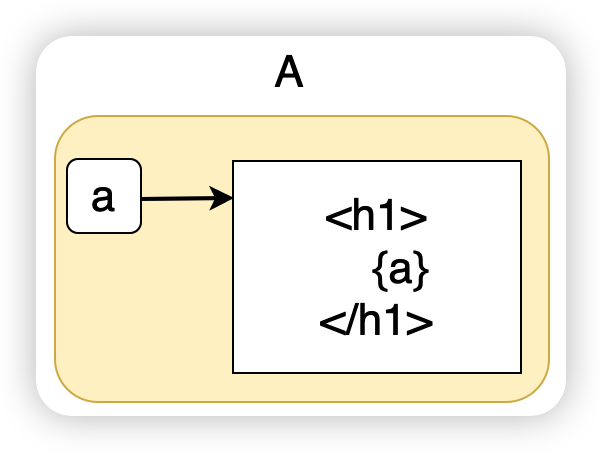
A 组件是整个应用的根组件,在这个根组件中,有一个自变量 a,a 的变化会导致 UI 的重新渲染。

上图表示在 A 组件中引入了一个因变量 b,A 组件中的自变量 a 的改变会导致因变量 b 的改变,而这个因变量 b 又作为 props 传递到了子组件 B 当中。
B 组件中也有一个自变量 c,在该组件中还接收从父组件 A 传递过来的 props b,最终在 UI 中渲染 b + c
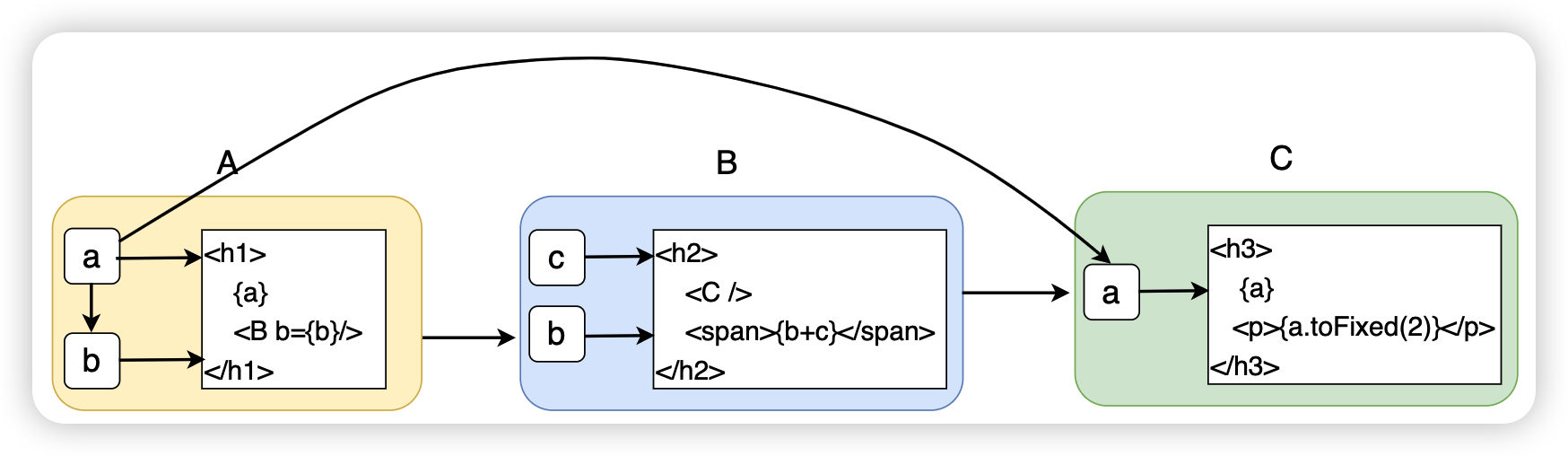
在组件 C 中,接收从根组件 A 传递过来的数据 a,从而 a 变成 C 组件的一个自变量。
接下来我们来总结一下,各个组件中所包含的自变量:
- A 组件
- 自变量 a
- a 的因变量 b
- B 组件
- 从 A 组件传递过来的自变量 b
- 自变量 c
- C 组件
- 从 A 组件传递过来的自变量 a
理清楚自变量之后,我们就可以从三个维度去整理自变量和不同维度之间的关系。
自变量与 UI 的对应关系
从 UI 层面去考虑的话,自变量的变化会导致哪些 UI 发生变化?
- a 变化导致 A 的 UI 中的 {a} 变化
- a 变化导致因变量 b 变化,导致 B 的 UI 中的 {b+c} 变化
- a 变换导致 C 的 UI 中的 {a} 变化
- a 变化导致 C 的 UI 中的 {a.toFixed(2)} 变化
- c 变化导致 B 的 UI 中的 {b+c} 变化
总共我们梳理出来的 UI 变化路径有 5 条,接下来我们要做的事情就是根据梳理出来的变化路径执行具体的 DOM 操作即可。
自变量与组件的对应关系
从组件的层面去考虑的话,自变量的变化会导致哪些组件发生变化呢?
- a 变化导致 A 组件 UI 变化
- a 变化导致 b 变化,从而导致 B 组件的UI 变化
- a 变化导致组件 C 的UI 变化
- c 变化导致组件 B 的 UI 变化
相较于上面的自变量与 UI 的对应关系,当我们考虑自变量与组件之间的关系时,梳理出来的路径从 5 条变成了 4 条。虽然路径减少了,但是在运行的时候,需要进行额外的操作,就是确定某一个组件发生变化时,组件内部的 UI 需要发生变化的部分。例如,通过路径 4 只能明确 B 组件发生了变化,但是具体发生了什么变化,还需要组件内部进行进一步的确定。
自变量与应用的对应关系
最后我们考虑自变量和应用之间的关系,那么路径就变成了:
- a 变化导致应用中发生 UI 变化
- c 变化导致应用中发生 UI 变化
整体路径从 4 条减少为了 2 条,虽然路径减少了,但是要做的额外的工作更多了。比如 a 的变化会导致应用中的 UI 发生变化,那么究竟是哪一部分的 UI ?这些需要额外的进行确定。
最后我们可以总结一下,前端框架需要关注自变量和 x(UI、组件、应用) 的对应关系,随着 x 的抽象层级不断下降,自变量到 UI 变化的路径条数就会增多。路径越多,则意味着前端框架在运行时消耗在“寻找自变量与 UI 对应关系”上面的时间越少。
根据上面的特点,我们就可以针对现代前端框架分为三大类:
- 元素级框架
- 组件级框架
- 应用级框架
以常见的前端框架为例,React 属于应用级框架,Vue 属于组件级的框架,而新的 Svelte、Solid.js 属于元素级框架。
所有的现代前端框架,都有一个非常重要的特点,那就是“基于状态的声明式渲染”。概括成一个公式的话,那就是 UI = f(state)
这里有一点类似于初中数学中自变量与因变量之间的关系。例如在上面的公式中,state 就是一个自变量,state 的变化会导致 UI 这个因变量发生变化。
不同的框架,在根据自变量(state)的变化计算出 UI 的变化这一步骤有所区别,自变量和 x(应用、组件、UI)的对应关系,随着 x 抽象的层级不断下降,“自变量到 UI 变化”的路径则不断增多。路径越多,则意味着前端框架在运行时消耗在寻找“自变量与 UI 的对应关系”上的时间越少。
以“与自变量建立对应关系的抽象层级”可以作为其分类的依据,按照这个标准,前端框架可以分为以下三类:
- 元素级框架
- 组件级框架
- 应用级框架
以常见的前端框架为例,React 属于应用级框架,Vue 属于组件级框架,Svelte、Solid.js 属于元素级框架。
虚拟 DOM 最早是由 React 团队提出来的,因此 React 团队在对虚拟 DOM 的定义上面有绝对的话语权。
**Virtual DOM 是一种编程概念。**在这个概念里, UI 以一种理想化的,或者说“虚拟的”表现形式被保存于内存中。
也就是说,只要我们有一种方式,能够将真实 DOM 的层次结构描述出来,那么这就是一个虚拟 DOM。
在 React 中,React 团队使用的是 JS 对象来对 DOM 结构进行一个描述。但是很多人会直接把 JS 对象和虚拟 DOM 划等号,这种理解是不太准确的,比较片面的。
虚拟 DOM 和 JS 对象之间的关系:前者是一种思想,后者是一种思想的具体实现。
使用虚拟 DOM 主要有两个方面的优势:
- 相较于 DOM 的体积优势和速度优势
- 多平台的渲染抽象能力
相较于 DOM 的体积优势和速度优势
首先我们需要明确一个点,JS 层面的计算速度要比 DOM 层面的计算要快:
- DOM 对象最终要被浏览器渲染出来之前,浏览器会有很多工作要做(浏览器的渲染原理)
- DOM 对象上面的属性也非常非常多
const div = document.createElement("div");
for(let i in div){console.log(i + " ")}操作 JS 对象的时间和操作 DOM 对象的时间是完全不一样的。
JS 层面的计算速度要高于 DOM 层面的计算速度。
此时有一个问题:虽然使用了 JS 对象来描述 UI,但是最终不还是要用原生 DOM API 去操作 DOM 么?
虚拟 DOM 在第一次渲染页面的时候,并没有什么优势,速度肯定比直接操作原生 DOM API 要慢一些,虚拟 DOM 真正体现优势是在更新阶段。
根据 React 团队的研究,在渲染页面时,相比使用原生 DOM API,开发人员更加倾向于使用 innerHTML
let newP = document.createElement("p");
let newContent = document.createTextNode("this is a test");
newP.appendChild(newContent);
document.body.appendChild(newP);document.body.innerHTML = `
<p>
this is a test
</p>
`;因此在使用 innerHTML 的时候,就涉及到了两个层面的计算:
- JS 层面:解析字符串
- DOM 层面:创建对应的 DOM 节点
接下来我们加入虚拟 DOM 来进行对比:
| innerHTML | 虚拟 DOM | |
|---|---|---|
| JS 层面计算 | 解析字符串 | 创建 JS 对象 |
| DOM 层面计算 | 创建对应的 DOM 节点 | 创建对应的 DOM 节点 |
虚拟 DOM 真正发挥威力的时候,是在更新阶段
innerHTML 进行更新的时候,要全部重新赋值,这意味着之前创建的 DOM 节点需要全部销毁掉,然后重新进行创建
但是虚拟 DOM 只需要更新必要的 DOM 节点即可
| innerHTML | 虚拟 DOM | |
|---|---|---|
| JS 层面计算 | 解析字符串 | 创建 JS 对象 |
| DOM 层面计算 | 销毁原来所有的 DOM 节点 | 修改必要的 DOM 节点 |
| DOM 层面计算 | 创建对应的 DOM 节点 |
多平台的渲染抽象能力
UI = f(state)这个公式进一步进行拆分可以拆分成两步:
- 根据自变量的变化计算出 UI
- 根据 UI 变化执行具体的宿主环境的 API
虚拟 DOM 只是多真实 UI 的一个描述,回头根据不同的宿主环境,可以执行不同的渲染代码:
- 浏览器、Node.js 宿主环境使用 ReactDOM 包
- Native 宿主环境使用 ReactNative 包
- Canvas、SVG 或者 VML(IE8)宿主环境使用 ReactArt 包
- ReactTest 包用于渲染出 JS 对象,可以很方便地测试“不隶属于任何宿主环境的通用功能”
在 React 中通过 JSX 来描述 UI,JSX 最终会被转为一个叫做 createElement 方法的调用,调用该方法后就会得到虚拟 DOM 对象。
经过 Babel 编译后结果如下:
在源码中 createElement 方法如下:
/**
*
* @param {*} type 元素类型 h1
* @param {*} config 属性对象 {id : "aa"}
* @param {*} children 子元素 hello
* @returns
* <h1 id="aa">hello</h1>
*/
export function createElement(type, config, children) {
let propName;
const props = {};
let key = null;
let ref = null;
let self = null;
let source = null;
// 说明有属性
if (config != null) {
// ...
for (propName in config) {
if (
hasOwnProperty.call(config, propName) &&
!RESERVED_PROPS.hasOwnProperty(propName)
) {
props[propName] = config[propName];
}
}
}
// 经历了上面的 if 之后,所有的属性都放到了 props 对象上面
// props ==> {id : "aa"}
// children 可以有多个参数,这些参数被转移到新分配的 props 对象上
// 如果是多个子元素,对应的是一个数组
const childrenLength = arguments.length - 2;
if (childrenLength === 1) {
props.children = children;
} else if (childrenLength > 1) {
const childArray = Array(childrenLength);
for (let i = 0; i < childrenLength; i++) {
childArray[i] = arguments[i + 2];
}
// ...
props.children = childArray;
}
// 添加默认的 props
if (type && type.defaultProps) {
const defaultProps = type.defaultProps;
for (propName in defaultProps) {
if (props[propName] === undefined) {
props[propName] = defaultProps[propName];
}
}
}
// ...
return ReactElement(
type,
key,
ref,
self,
source,
ReactCurrentOwner.current,
props
);
}
const ReactElement = function (type, key, ref, self, source, owner, props) {
// 该对象就是最终向外部返回的 vdom(也就是用来描述 DOM 层次结构的 JS 对象)
const element = {
// 让我们能够唯一地将其标识为 React 元素
$$typeof: REACT_ELEMENT_TYPE,
// 元素的内置属性
type: type,
key: key,
ref: ref,
props: props,
// 记录负责创建此元素的组件。
_owner: owner,
};
// ...
return element;
};在上面的代码中,最终返回的 element 对象就是我们所说的虚拟 DOM 对象。在官方文档中,官方更倾向于将这个对象称之为 React 元素。
虚拟 DOM 最初是由 React 团队所提出的概念,这是一种编程的思想,指的是针对真实 UI DOM 的一种描述能力。
在 React 中,使用了 JS 对象来描述真实的 DOM 结构。虚拟DOM和 JS 对象之间的关系:前者是一种思想,后者是这种思想的具体实现。
使用虚拟 DOM 有如下的优点:
- 相较于 DOM 的体积和速度优势
- 多平台渲染的抽象能力
相较于 DOM 的体积和速度优势
- JS 层面的计算的速度,要比 DOM 层面的计算快得多
- DOM 对象最终要被浏览器显示出来之前,浏览器会有很多工作要做(浏览器渲染原理)
- DOM 上面的属性也是非常多的
- 虚拟 DOM 发挥优势的时机主要体现在更新的时候,相比较 innerHTML 要将已有的 DOM 节点全部销毁,虚拟 DOM 能够做到针对 DOM 节点做最小程度的修改
多平台渲染的抽象能力
- 浏览器、Node.js 宿主环境使用 ReactDOM 包
- Native 宿主环境使用 ReactNative 包
- Canvas、SVG 或者 VML(IE8)宿主环境使用 ReactArt 包
- ReactTest 包用于渲染出 JS 对象,可以很方便地测试“不隶属于任何宿主环境的通用功能”
在 React 中,通过 JSX 来描述 UI,JSX 仅仅是一个语法糖,会被 Babel 编译为 createElement 方法的调用。该方法调用之后会返回一个 JS 对象,该对象就是虚拟 DOM 对象,官方更倾向于称之为一个 React 元素。
React 的架构?新的 Fiber 架构相较于之前的 Stack 架构有什么优势?
React 是用 JavaScript 构建快速响应的大型 Web 应用程序的首选方式
有哪些情况会导致我们的 Web 应用无法快速响应?
总结起来,实际上有两大类场景会限制快速响应:
- 当你需要执行大量计算或者设备本身的性能不足的时候,页面就会出现掉帧、卡顿的现象,这个本质上是来自于 CPU 的瓶颈
- 进行 I/O 的时候,需要等待数据返回后再进行后续操作,等待的过程中无法快速响应,这种情况实际上是来自于 I/O 的瓶颈
平时我们在浏览网页的时候,这张网页实际上是由浏览器绘制出来的,就像一个画家画画一样

平时我们所浏览的网页,里面往往会有一些动起来的东西,比如轮播图、百叶窗之类的,本质其实就是浏览器不停的在进行绘制。
目前,大多数设备的刷新频率为 60 FPS,意味着 1秒钟需要绘制 60 次,1000ms / 60 = 16.66ms,也就是说浏览器每隔 16.66ms 就需要绘制一帧。
浏览器在绘制一帧画面的时候,实际上还有很多的事情要做:
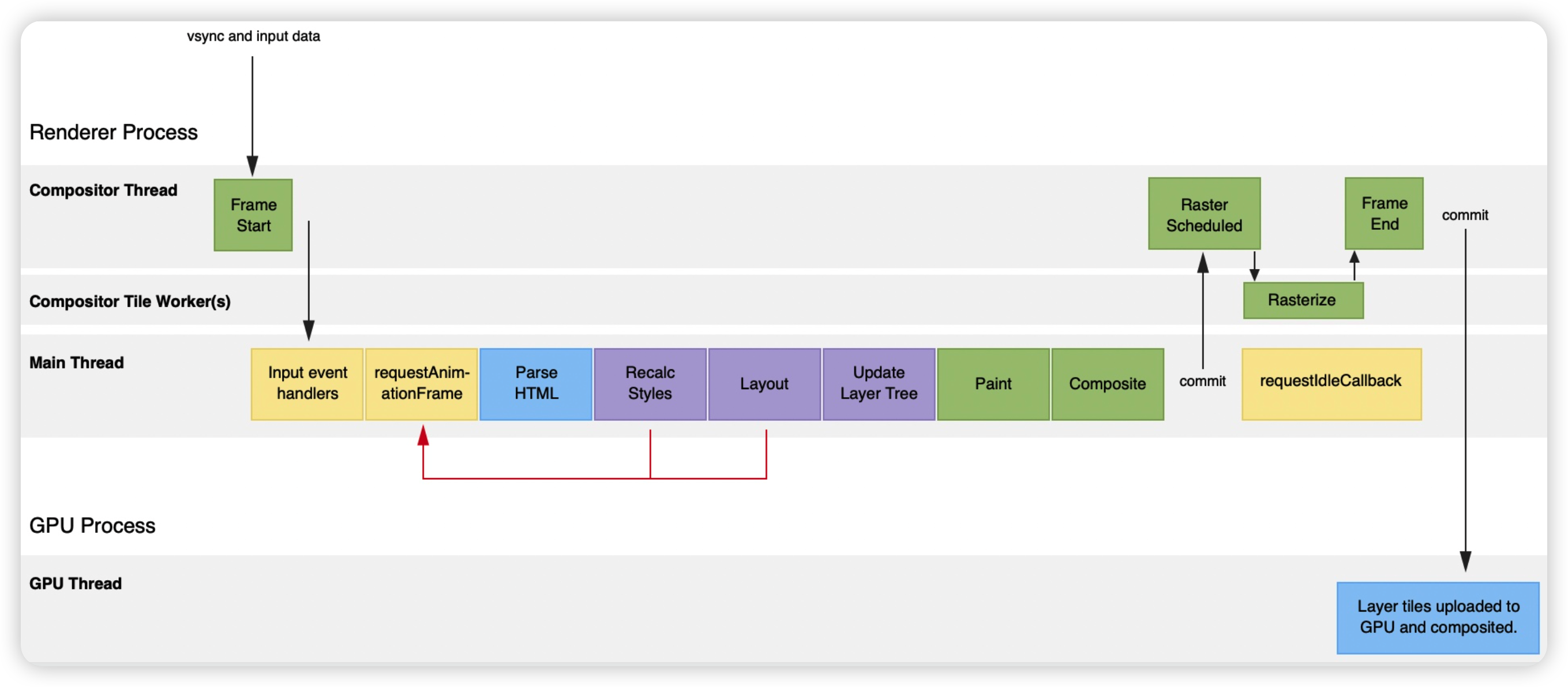
上图中的任务被称之为“渲染流水线”,每次执行流水线的时候,大致是需要如上的一些步骤,但是并不是说每一次所有的任务都需要全部执行:
- 当通过 JS 或者 CSS 修改 DOM 元素的几何属性(比如长度、宽度)时,会触发完整的渲染流水线,这种情况称之为重排(回流)
- 当修改的属性不涉及几何属性(比如字体、颜色)时,会省略掉流水线中的 Layout、Layer 过程,这种情况称之为重绘
- 当修改“不涉及重排、重绘的属性(比如 transform 属性)”时,会省略流水线中 Layout、Layer、Print 过程,仅执行合成线程的绘制工作,这种情况称之为合成
按照性能高低进行排序的话:合成 > 重绘 > 重排
前面说过,浏览器绘制的频率是 16.66ms 一帧,但是执行 JS 与渲染流水线实际上是在同一个线程上面执行,也就意味着如果 JS 执行的时间过长,不能够及时的渲染下一帧,也就意味着页面掉帧,表现出来的现象就是页面卡顿。
在 Reactv16 之前就存在这个问题,JS 代码执行的时间过长。在 React 中,需要去计算整颗虚拟 DOM 树,虽然说是 JS 层面的计算,相比直接操作 DOM,节省了很多时间,但是每次重新去计算整颗虚拟 DOM 树,会造成每一帧的 JS 代码的执行时间过长,从而导致动画、还有一些实时更新得不到及时的响应,造成卡顿的视觉效果。
假设有如下的 DOM 层次结构:
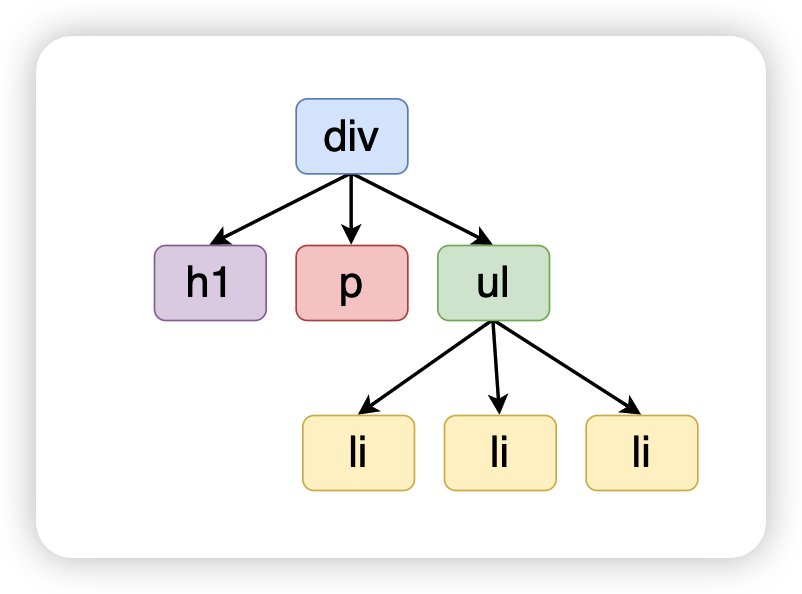
那么转换成虚拟 DOM 对象结构大致如下:
{
type : "div",
props : {
id : "test",
children : [
{
type : "h1",
props : {
children : "This is a title"
}
}
{
type : "p",
props : {
children : "This is a paragraph"
}
},{
type : "ul",
props : {
children : [{
type : "li",
props : {
children : "apple"
}
},{
type : "li",
props : {
children : "banana"
}
},{
type : "li",
props : {
children : "pear"
}
}]
}
}
]
}
}在 React v16 版本之前,进行两颗虚拟 DOM 树的对比的时候,需要涉及到遍历上面的结构,这个时候只能使用递归,而且这种递归是不能够打断的,一条路走到黑,从而造成了 JS 执行时间过长。
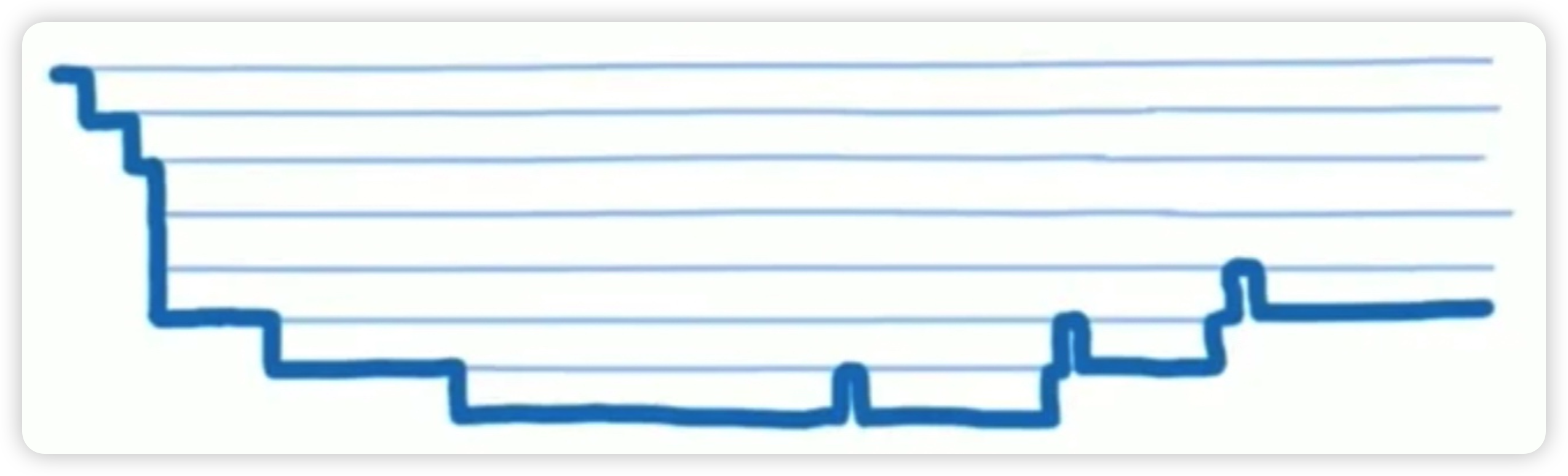
这样的架构模式,官方就称之为 Stack 架构模式,因为采用的是递归,会不停的开启新的函数栈。
对于前端开发来讲,最主要的 I/O 瓶颈就是网络延迟。
网络延迟是一种客观存在的现象,那么如何减少这种现象对用户的影响呢?React 团队给出的答案是:将人机交互的研究成果整合到 UI 中。
用户对卡顿的感知是不一样的,输入框哪怕只有轻微的延迟,用户也会认为很卡,假设是加载一个列表,哪怕 loading 好几秒,用户也不会觉得卡顿。
对于 React 来讲,所有的操作都是来自于自变量的变化导致的重新渲染,我们只需要针对不同的操作赋予不同的优先级即可。
具体来说,主要包含以下三个点:
- 为不同操作造成的“自变量变化”赋予不同的优先级
- 所有优先级统一调度,优先处理“最高优先级的更新”
- 如果更新正在进行(进入虚拟 DOM 相关工作),此时有“更高优先级的更新”产生的话,中段当前的更新,优先处理高优先级更新
要实现上面的这三个点,就需要 React 底层能实现:
- 用于调度优先级的调度器
- 调度器对应的调度算法
- 支持可中断的虚拟 DOM 的实现
所以不管是解决 CPU 的瓶颈还是 I/O 的瓶颈,底层的诉求都是需要实现 time slice
执行一段耗时的 JS 代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
.ball {
width: 100px;
height: 100px;
border-radius: 50%;
background-color: #f00;
position: absolute;
left: 0;
top: 50px;
animation: move 10s infinite alternate;
}
@keyframes move {
0% {
left: 0px;
}
100% {
left: 500px;
}
}
</style>
</head>
<body>
<button id="btn">执行一段耗时的 JS 代码</button>
<div class="ball"></div>
<script>
function delay(duration) {
var start = Date.now();
while (Date.now() - start < duration) { }
}
btn.onclick = function () {
delay(5000);
};
</script>
</body>
</html>从 React v16 开始,官方团队正式引用了 Fiber 的概念,这是一种通过链表来描述 UI 的方式,本质上你也可以看作是一种虚拟 DOM 的实现。
与其将 “Virtual DOM” 视为一种技术,不如说它是一种模式,人们提到它时经常是要表达不同的东西。在 React 的世界里,术语 “Virtual DOM” 通常与 React 元素 关联在一起,因为它们都是代表了用户界面的对象。而 React 也使用一个名为 “fibers” 的内部对象来存放组件树的附加信息。上述二者也被认为是 React 中 “Virtual DOM” 实现的一部分。
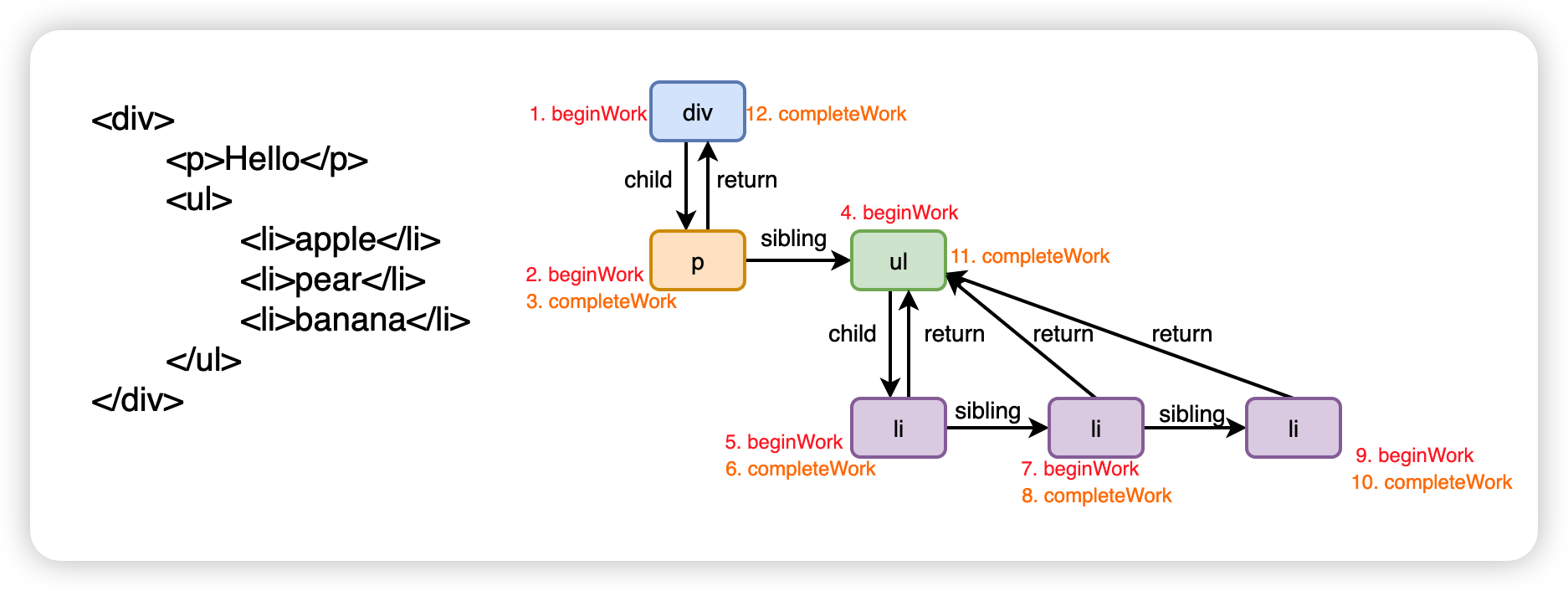
Fiber 本质上也是一个对象,但是和之前 React 元素不同的地方在于对象之间使用链表的结构串联起来,child 指向子元素,sibling 指向兄弟元素,return 指向父元素。
如下图:
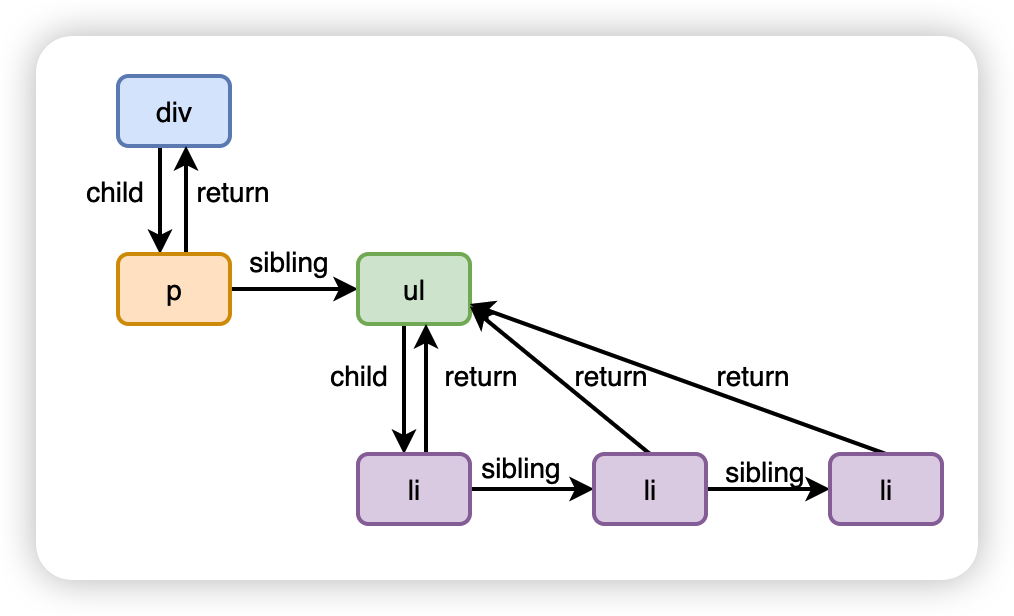
使用链表这种结构,有一个最大的好处就是在进行整颗树的对比(reconcile)计算时,这个过程是可以被打断。
在发现一帧时间已经不够,不能够再继续执行 JS,需要渲染下一帧的时候,这个时候就会打断 JS 的执行,优先渲染下一帧。渲染完成后再接着回来完成上一次没有执行完的 JS 计算。
官方还提供了一个 Stack 架构和 Fiber 架构的对比示例:https://claudiopro.github.io/react-fiber-vs-stack-demo/
下面是 React 源码中创建 Fiber 对象的相关代码:
const createFiber = function (tag, pendingProps, key, mode) {
// 创建 fiber 节点的实例对象
return new FiberNode(tag, pendingProps, key, mode);
};
function FiberNode(tag, pendingProps, key, mode) {
// Instance
this.tag = tag;
this.key = key;
this.elementType = null;
this.type = null;
this.stateNode = null; // 映射真实 DOM
// Fiber
// 上下、前后 fiber 通过链表的形式进行关联
this.return = null;
this.child = null;
this.sibling = null;
this.index = 0;
this.ref = null;
this.refCleanup = null;
// 和 hook 相关
this.pendingProps = pendingProps;
this.memoizedProps = null;
this.updateQueue = null;
this.memoizedState = null;
this.dependencies = null;
this.mode = mode;
// Effects
this.flags = NoFlags;
this.subtreeFlags = NoFlags;
this.deletions = null;
this.lanes = NoLanes;
this.childLanes = NoLanes;
this.alternate = null;
// ...
}从 React v16 开始引入了 Scheduler(调度器),用来调度任务的优先级。
UI = f(state):
- 根据自变量的变化计算出 UI
- 根据 UI 变化执行具体的宿主环境的 API
React v16之前:
- Reconciler(协调器):vdom 的实现,根据自变量的变化计算出 UI 的变化
- Renderer(渲染器):负责将 UI 的变化渲染到宿主环境
从 React v16 开始,多了一个组件:
- Scheduler(调度器):调度任务的优先级,高优先级的任务会优先进入到 Reconciler
- Reconciler(协调器):vdom 的实现,根据自变量的变化计算出 UI 的变化
- Renderer(渲染器):负责将 UI 的变化渲染到宿主环境
新架构中,Reconciler 的更新流程也从之前的递归变成了“可中断的循环过程”。
function workLoopConcurrent{
// 如果还有任务,并且时间切片还有剩余的时间
while(workInProgress !== null && !shouldYield()){
performUnitOfWork(workInProgress);
}
}
function shouldYield(){
// 当前时间是否大于过期时间
// 其中 deadline = getCurrentTime() + yieldInterval
// yieldInterval 为调度器预设的时间间隔,默认为 5ms
return getCurrentTime() >= deadline;
}每次循环都会调用 shouldYield 判断当前的时间切片是否有足够的剩余时间,如果没有足够的剩余时间,就暂停 reconciler 的执行,将主线程还给渲染流水线,进行下一帧的渲染操作,渲染工作完成后,再等待下一个宏任务进行后续代码的执行。
React v15及其之前的架构:
- Reconciler(协调器):VDOM 的实现,负责根据自变量变化计算出 UI 变化
- Renderer(渲染器):负责将 UI 变化渲染到宿主环境中
这种架构称之为 Stack 架构,在 Reconciler 中,mount 的组件会调用 mountComponent,update 的组件会调用 updateComponent,这两个方法都会递归更新子组件,更新流程一旦开始,中途无法中断。
但是随着应用规模的逐渐增大,之前的架构模式无法再满足“快速响应”这一需求,主要受限于如下两个方面:
- CPU 瓶颈:由于 VDOM 在进行差异比较时,采用的是递归的方式,JS 计算会消耗大量的时间,从而导致动画、还有一些需要实时更新的内容产生视觉上的卡顿。
- I/O 瓶颈:由于各种基于“自变量”变化而产生的更新任务没有优先级的概念,因此在某些更新任务(例如文本框的输入)有稍微的延迟,对于用户来讲也是非常敏感的,会让用户产生卡顿的感觉。
新的架构称之为 Fiber 架构:
- Scheduler(调度器):调度任务的优先级,高优先级任务会优先进入到 Reconciler
- Reconciler(协调器):VDOM 的实现,负责根据自变量变化计算出 UI 变化
- Renderer(渲染器):负责将 UI 变化渲染到宿主环境中
首先引入了 Fiber 的概念,通过一个对象来描述一个 DOM 节点,但是和之前方案不同的地方在于,每个 Fiber 对象之间通过链表的方式来进行串联。通过 child 来指向子元素,通过 sibling 指向兄弟元素,通过 return 来指向父元素。
在新架构中,Reconciler 中的更新流程从递归变为了“可中断的循环过程”。每次循环都会调用 shouldYield 判断当前的 TimeSlice 是否有剩余时间,没有剩余时间则暂停更新流程,将主线程还给渲染流水线,等待下一个宏任务再继续执行。这样就解决了 CPU 的瓶颈问题。
另外在新架构中还引入了 Scheduler 调度器,用来调度任务的优先级,从而解决了 I/O 的瓶颈问题。
现代前端框架都可以总结为一个公式:
UI = f(state)
上面的公式还可以进行一个拆分:
- 根据自变量(state)的变化计算出 UI 的变化
- 根据 UI 变化执行具体的宿主环境的 API
对应的公式:
const state = reconcile(update); // 通过 reconciler 计算出最新的状态
const UI = commit(state); // 根据上一步计算出来的 state 渲染出 UI对应到 React 里面就两大阶段:
- render 阶段:调合虚拟 DOM,计算出最终要渲染出来的虚拟 DOM
- commit 阶段:根据上一步计算出来的虚拟 DOM,渲染具体的 UI
每个阶段对应不同的组件:

- 调度器(Scheduer):调度任务,为任务排序优先级,让优先级高的任务先进入到 Reconciler
- 协调器(Reconciler):生成 Fiber 对象,收集副作用,找出哪些节点发生了变化,打上不同的 flags,著名的 diff 算法也是在这个组件中执行的。
- 渲染器(Renderer):根据协调器计算出来的虚拟 DOM 同步的渲染节点到视图上。
接下来我们来看一个例子:
export default () => {
const [count, updateCount] = useState(0);
return (
<ul>
<button onClick={() => updateCount(count + 1)}>乘以{count}</button>
<li>{1 * count}</li>
<li>{2 * count}</li>
<li>{3 * count}</li>
</ul>
);
};当用户点击按钮时,首先是由 Scheduler 进行任务的协调,render 阶段(虚线框内)的工作流程是可以随时被以下原因中断:
- 有其他更高优先级的任务需要执行
- 当前的 time slice 没有剩余的时间
- 发生了其他错误
注意上面 render 阶段的工作是在内存里面进行的,不会更新宿主环境 UI,因此这个阶段即使工作流程反复被中断,用户也不会看到“更新不完整的 UI”。
当 Scheduler 调度完成后,将任务交给 Reconciler,Reconciler 就需要计算出新的 UI,最后就由 Renderer 同步进行渲染更新操作。
如下图所示:

在 React v16 版本之前,采用的是 Stack 架构,所有任务只能同步进行,无法被打断,这就导致浏览器可能会出现丢帧的现象,表现出卡顿。React 为了解决这个问题,从 v16 版本开始从架构上面进行了两大更新:
- 引入 Fiber
- 新增了 Scheduler
Scheduler 在浏览器的原生 API 中实际上是有类似的实现的,这个 API 就是 requestIdleCallback
MDN:https://developer.mozilla.org/zh-CN/docs/Web/API/Window/requestIdleCallback
虽然每一帧绘制的时间约为 16.66ms,但是如果屏幕没有刷新,那么浏览器会安排长度为 50ms 左右的空闲时间。
为什么是 50ms?
根据研究报告表明,用户操作之后,100ms 以内的响应给用户的感觉都是瞬间发生,也就是说不会感受到延迟感,因此将空闲时间设置为 50,浏览器依然还剩下 50ms 可以处理用户的操作响应,不会让用户感到延迟。
function callback(IdleDeadline) {
console.log("当前帧绘制完毕后所剩余的时间:", IdleDeadline.timeRemaining());
window.requestIdleCallback(callback);
}
window.requestIdleCallback(callback);虽然浏览器有类似的 API,但是 React 团队并没有使用该 API,因为该 API 存在兼容性问题。因此 React 团队自己实现了一套这样的机制,这个就是调度器 Scheduler。
后期 React 团队打算单独发行这个 Scheduler,这意味着调度器不仅仅只能在 React 中使用,凡是有涉及到任务调度需求的项目都可以使用 Scheduler。
协调器是 render 阶段的第二阶段工作,类组件或者函数组件本身就是在这个阶段被调用的。
根据 Scheduler 调度结果的不同,协调器起点可能是不同的
- performSyncWorkOnRoot(同步更新流程)
- performConcurrentWorkOnRoot(并发更新流程)
// performSyncWorkOnRoot 会执行该方法
function workLoopSync() {
while (workInProgress !== null) {
performUnitOfWork(workInProgress);
}
}// performConcurrentWorkOnRoot 会执行该方法
function workLoopConcurrent() {
while (workInProgress !== null && !shouldYield()) {
performUnitOfWork(workInProgress);
}
}新的架构使用 Fiber(对象)来描述 DOM 结构,最终需要形成一颗 Fiber tree,这不过这棵树是通过链表的形式串联在一起的。
workInProgress 代表的是当前的 FiberNode。
performUnitOfWork 方法会创建下一个 FiberNode,并且还会将已创建的 FiberNode 连接起来(child、return、sibling),从而形成一个链表结构的 Fiber tree。
如果 workInProgress 为 null,说明已经没有下一个 FiberNode,也就是说明整颗 Fiber tree 树已经构建完毕。
上面两个方法唯一的区别就是是否调用了 shouldYield 方法,该方法表明了是否可以中断。
performUnitOfWork 在创建下一个 FiberNode 的时候,整体上的工作流程可以分为两大块:
- 递阶段
- 归阶段
递阶段
递阶段会从 HostRootFiber 开始向下以深度优先的原则进行遍历,遍历到的每一个 FiberNode 执行 beginWork 方法。该方法会根据传入的 FiberNode 创建下一级的 FiberNode,此时可能存在两种情况:
- 下一级只有一个元素,beginWork 方法会创建对应的 FiberNode,并于 workInProgress 连接
<ul>
<li></li>
</ul>这里就会创建 li 对应的 FiberNode,做出如下的连接:
LiFiber.return = UlFiber;- 下一级有多个元素,这是 beginWork 方法会依次创建所有的子 FiberNode 并且通过 sibling 连接到一起,每个子 FiberNode 也会和 workInProgress 连接
<ul>
<li></li>
<li></li>
<li></li>
</ul>此时会创建 3 个 li 对应的 FiberNode,连接情况如下:
// 所有的子 Fiber 依次连接
Li0Fiber.sibling = Li1Fiber;
Li1Fiber.sibling = Li2Fiber;
// 子 Fiber 还需要和父 Fiber 连接
Li0Fiber.return = UlFiber;
Li1Fiber.return = UlFiber;
Li2Fiber.return = UlFiber;由于采用的是深度优先的原则,因此无法再往下走的时候,会进入到归阶段。
归阶段
归阶段会调用 completeWork 方法来处理 FiberNode,做一些副作用的收集。
当某个 FiberNode 执行完了 completeWork 方法后,如果存在兄弟元素,就会进入到兄弟元素的递阶段,如果不存在兄弟元素,就会进入父 FiberNode 的归阶段。
function performUnitOfWork(fiberNode) {
// 省略 beginWork
if (fiberNode.child) {
performUnitOfWork(fiberNode.child);
}
// 省略 CompleteWork
if (fiberNode.sibling) {
performUnitOfWork(fiberNode.sibling);
}
}最后我们来看一张图:

Renderer 工作的阶段被称之为 commit 阶段。该阶段会将各种副作用 commit 到宿主环境的 UI 中。
相较于之前的 render 阶段可以被打断,commit 阶段一旦开始就会同步执行直到完成渲染工作。
整个渲染器渲染过程中可以分为三个子阶段:
- BeforeMutation 阶段
- Mutation 阶段
- Layout 阶段

题目:是否了解过 React 的整体渲染流程?里面主要有哪些阶段?
参考答案:
React 整体的渲染流程可以分为两大阶段,分别是 render 阶段和 commit 阶段。
render 阶段里面会经由调度器和协调器处理,此过程是在内存中运行,是异步可中断的。
commit 阶段会由渲染器进行处理,根据副作用进行 UI 的更新,此过程是同步不可中断的,否则会造成 UI 和数据显示不一致。
调度器
调度器的主要工作就是调度任务,让所有的任务有优先级的概念,这样的话紧急的任务可以优先执行。Scheduler 实际上在浏览器的 API 中是有原生实现的,这个 API 叫做 requestIdleCallback,但是由于兼容性问题,React 放弃了使用这个 API,而是自己实现了一套这样的机制,并且后期会把 Scheduler 这个包单独的进行发布,变成一个独立的包。这就意味 Scheduler 不仅仅是只能在 React 中使用,后面如果有其他的项目涉及到了任务调度的需求,都可以使用这个 Scheduler。
协调器
协调器是 Render 的第二阶段工作。该阶段会采用深度优先的原则遍历并且创建一个一个的 FiberNode,并将其串联在一起,在遍历时分为了“递”与“归”两个阶段,其中在“递”阶段会执行 beginWork 方法,该方法会根据传入的 FiberNode 创建下一级 FiberNode。而“归”阶段则会执行 CompleteWork 方法,做一些副作用的收集
渲染器
渲染器的工作主要就是将各种副作用(flags 表示)commit 到宿主环境的 UI 中。整个阶段可以分为三个子阶段,分别是 BeforeMutation 阶段、Mutation 阶段和 Layout 阶段。
实际上,我们可以从三个维度来理解 Fiber:
- 是一种架构,称之为 Fiber 架构
- 是一种数据类型
- 动态的工作单元
是一种架构,称之为 Fiber 架构
在 React v16之前,使用的是 Stack Reconciler,因此那个时候的 React 架构被称之为 Stack 架构。从 React v16 开始,重构了整个架构,引入了 Fiber,因此新的架构也被称之为 Fiber 架构,Stack Reconciler 也变成了 Fiber Reconciler。各个FiberNode之间通过链表的形式串联起来:
function FiberNode(tag, pendingProps, key, mode) {
// ...
// 周围的 Fiber Node 通过链表的形式进行关联
this.return = null;
this.child = null;
this.sibling = null;
this.index = 0;
// ...
}是一种数据类型
Fiber 本质上也是一个对象,是在之前 React 元素基础上的一种升级版本。每个 FiberNode 对象里面会包含 React 元素的类型、周围链接的FiberNode以及 DOM 相关信息:
function FiberNode(tag, pendingProps, key, mode) {
// 类型
this.tag = tag;
this.key = key;
this.elementType = null;
this.type = null;
this.stateNode = null; // 映射真实 DOM
// ...
}动态的工作单元
在每个 FiberNode 中,保存了本次更新中该 React 元素变化的数据,还有就是要执行的工作(增、删、更新)以及副作用的信息:
function FiberNode(tag, pendingProps, key, mode) {
// ...
// 副作用相关
this.flags = NoFlags;
this.subtreeFlags = NoFlags;
this.deletions = null;
// 与调度优先级有关
this.lanes = NoLanes;
this.childLanes = NoLanes;
// ...
}为什么指向父 FiberNode 的字段叫做 return 而非 parent?
因为作为一个动态的工作单元,return 指代的是 FiberNode 执行完 completeWork 后返回的下一个 FiberNode,这里会有一个返回的动作,因此通过 return 来指代父 FiberNode
Fiber 架构中的双缓冲工作原理类似于显卡的工作原理。
显卡分为前缓冲区和后缓冲区。首先,前缓冲区会显示图像,之后,合成的新的图像会被写入到后缓冲区,一旦后缓冲区写入图像完毕,就会前后缓冲区进行一个互换,这种将数据保存在缓冲区再进行互换的技术,就被称之为双缓冲技术。
Fiber 架构同样用到了这个技术,在 Fiber 架构中,同时存在两颗 Fiber Tree,一颗是真实 UI 对应的 Fiber Tree,可以类比为显卡的前缓冲区,另外一颗是在内存中构建的 FiberTree,可以类比为显卡的后缓冲区。
在 React 源码中,很多方法都需要接收两颗 FiberTree:
function cloneChildFibers(current, workInProgress){
// ...
}current 指的就是前缓冲区的 FiberNode,workInProgress 指的就是后缓冲区的 FiberNode。
两个 FiberNode 会通过 alternate 属性相互指向:
current.alternate = workInProgress;
workInProgress.alternate = current;接下来我们从首次渲染(mount)和更新(update)这两个阶段来看一下 FiberTree 的形成以及双缓存机制:
mount 阶段
首先最顶层有一个 FiberNode,称之为 FiberRootNode,该 FiberNode 会有一些自己的任务:
- Current Fiber Tree 与 Wip Fiber Tree 之间的切换
- 应用中的过期时间
- 应用的任务调度信息
现在假设有这么一个结构:
<body>
<div id="root"></div>
</body>function App(){
const [num, add] = useState(0);
return (
<p onClick={() => add(num + 1)}>{num}</p>
);
}
const rootElement = document.getElementById("root");
ReactDOM.createRoot(rootElement).render(<App />);当执行 ReactDOM.createRoot 的时候,会创建如下的结构:

此时会有一个 HostRootFiber,FiberRootNode 通过 current 来指向 HostRootFiber。
接下来进入到 mount 流程,该流程会基于每个 React 元素以深度优先的原则依次生成 wip FiberNode,并且每一个 wipFiberNode 会连接起来,如下图所示:

生成的 wip FiberTree 里面的每一个 FiberNode 会和 current FiberTree 里面的 FiberNode进行关联,关联的方式就是通过 alternate。但是目前 currentFiberTree里面只有一个 HostRootFiber,因此就只有这个 HostRootFiber 进行了 alternate 的关联。
当 wip FiberTree生成完毕后,也就意味着 render 阶段完毕了,此时 FiberRootNode就会被传递给 Renderer(渲染器),接下来就是进行渲染工作。渲染工作完毕后,浏览器中就显示了对应的 UI,此时 FiberRootNode.current 就会指向这颗 wip Fiber Tree,曾经的 wip Fiber Tree 它就会变成 current FiberTree,完成了双缓存的工作:

update 阶段
点击 p 元素,会触发更新,这一操作就会开启 update 流程,此时就会生成一颗新的 wip Fiber Tree,流程和之前是一样的

新的 wip Fiber Tree 里面的每一个 FiberNode 和 current Fiber Tree 的每一个 FiberNode 通过 alternate 属性进行关联。
当 wip Fiber Tree 生成完毕后,就会经历和之前一样的流程,FiberRootNode 会被传递给 Renderer 进行渲染,此时宿主环境所渲染出来的真实 UI 对应的就是左边 wip Fiber Tree 所对应的 DOM 结构,FiberRootNode.current 就会指向左边这棵树,右边的树就再次成为了新的 wip Fiber Tree

这个就是 Fiber双缓存的工作原理。
另外值得一提的是,开发者是可以在一个页面创建多个应用的,比如:
ReactDOM.createRoot(rootElement1).render(<App1 />);
ReactDOM.createRoot(rootElement2).render(<App2 />); ReactDOM.createRoot(rootElement3).render(<App3 />);在上面的代码中,我们创建了 3 个应用,此时就会存在 3 个 FiberRootNode,以及对应最多 6 棵 Fiber Tree 树。
题目:谈一谈你对 React 中 Fiber 的理解以及什么是 Fiber 双缓冲?
参考答案:
Fiber 可以从三个方面去理解:
- FiberNode 作为一种架构:在 React v15 以及之前的版本中,Reconceiler 采用的是递归的方式,因此被称之为 Stack Reconciler,到了 React v16 版本之后,引入了 Fiber,Reconceiler 也从 Stack Reconciler 变为了 Fiber Reconceiler,各个 FiberNode 之间通过链表的形式串联了起来。
- FiberNode 作为一种数据类型:Fiber 本质上也是一个对象,是之前虚拟 DOM 对象(React 元素,createElement 的返回值)的一种升级版本,每个 Fiber 对象里面会包含 React 元素的类型,周围链接的 FiberNode,DOM 相关信息。
- FiberNode 作为动态的工作单元:在每个 FiberNode 中,保存了“本次更新中该 React 元素变化的数据、要执行的工作(增、删、改、更新Ref、副作用等)”等信息。
所谓 Fiber 双缓冲树,指的是在内存中构建两颗树,并直接在内存中进行替换的技术。在 React 中使用 Wip Fiber Tree 和 Current Fiber Tree 这两颗树来实现更新的逻辑。Wip Fiber Tree 在内存中完成更新,而 Current Fiber Tree 是最终要渲染的树,两颗树通过 alternate 指针相互指向,这样在下一次渲染的时候,直接复用 Wip Fiber Tree 作为下一次的渲染树,而上一次的渲染树又作为新的 Wip Fiber Tree,这样可以加快 DOM 节点的替换与更新。
在 React 中,有许多触发状态更新的方法,比如:
- ReactDOM.createRoot
- this.setState
- this.forceUpdate
- useState dispatcher
- useReducer dispatcher
虽然这些方法执行的场景会有所不同,但是都可以接入同样的更新流程,原因是因为它们使用同一种数据结构来表示更新,这种数据结构就是 Update。
在 React 中,更新实际上是存在优先级的,其心智模型有一些类似于“代码版本管理工具”。
举个例子,假设现在我们在开发一个软件,当前软件处于正常的迭代中,拥有 A、B、C 三个正常需求,此时突然来了一个紧急的线上 Bug,整体流程如下:

为了修复线上 Bug D,你需要先完成需求 A、B、C,之后才能进行 D 的修复,这样的设计实际上是不合理的。
有了代码版本管理工具之后,有紧急线上 Bug 需要修复时,可以先暂存当前分支的修改,在 master 分支修复 Bug D 并紧急上线:

当 Bug 修复完毕后,再正常的来迭代 A、B、C 需求,之后的迭代会基于 D 这个版本:

并发更新的 React 也拥有相似的能力,不同的 update 是有不同的优先级,高优先级的 update 能够中断低优先级的 update,当高优先级的 update 完成更新之后,后续的低优先级更新会在高优先级 update 更新后的 state 的基础上再来进行更新。
接下来我们来看一下 Update 的一个数据结构。
在前面我们说了在 React 中,有不同的触发更新的方法,不同的方法实际上对应了不同的组件:
- ReactDOM.createRoot 对应 HostRoot
- this.setState 对应 ClassComponent
- this.forceUpdate 对应 ClassComponent
- useState dispatcher 对应 FunctionComponent
- useReducer dispatcher 对应 FunctionComponent
不同的组件类型,所对应的 Update 的数据结构是不同的。
HostRoot 和 ClassComponent 这一类组件所对应的 Update 数据结构如下:
function createUpdate(eventTime, lane){
const update = {
eventTime,
lane,
// 区分触发更新的场景
tag: UpdateState,
payload: null,
// UI 渲染后触发的回调函数
callback: null,
next: null,
};
return update;
}在上面的 Update 数据结构中,tag 字段是用于区分触发更新的场景的,选项包括:
- ReplaceState:代表在 ClassComponent 生命周期函数中直接改变 this.state
- UpdateState:默认情况,通过 ReactDOM.createRoot 或者 this.setState 触发更新
- CaptureUpdate:代表发生错误的情况下在 ClassComponent 或 HostRoot 中触发更新(比如通过 getDerivedStateFormError 方法)
- ForceUpdate:代表通过 this.forceUpdate 触发更新
接下来来看一下 FunctionComponent 所对应的 Update 数据结构:
const update = {
lane,
action,
// 优化策略相关字段
hasEagerState: false,
eagerState: null,
next: null
}在上面的数据结构中,有 hasEagerState 和 eagerState 这两个字段,它们和后面要介绍的 React 内部的性能优化策略(eagerState 策略)相关。
在 Update 数据结构中,有三个问题是需要考虑:
- 更新所承载的更新内容是什么
对于HostRoot以及类组件来讲,承载更新内容的字段为 payload 字段
// HostRoot
ReactDOM.createRoot(rootEle).render(<App/>);
// 对应 update
{
payload : {
// HostRoot 对应的 jsx,也就是 <App/> 对应的 jsx
element
},
// 省略其他字段
}
// ClassComponent 情况1
this.setState({num : 1})
// 对应 update
{
payload : {
num: 1
},
// 省略其他字段
}
// ClassComponent 情况2
this.setState({num : num => num + 1})
// 对应 update
{
payload : {
num: num => num + 1
},
// 省略其他字段
}对于函数组件来讲,承载更新内容的字段为 action 字段
// FC 使用 useState 情况1
updateNum(1);
// 对应 update
{
action : 1,
// 省略其他字段
}
// FC 使用 useState 情况2
updateNum(num => num + 1);
// 对应 update
{
action : num => num + 1,
// 省略其他字段
}- 更新的紧急程度:紧急程度是由 lane 字段来表示的
- 更新之间的顺序:通过 next 字段来指向下一个 update,从而形成一个链表。
上面所介绍的 update 是计算 state 的最小单位,updateQueue 是由 update 组成的一个链表,updateQueue 的数据结构如下:
const updateQueue = {
baseState: null,
firstBaseUpdate: null,
lastBaseUpdate: null,
shared: {
pending: null
}
}- baseState:参与计算的初始 state,update 基于该 state 计算新的 state,可以类比为心智模型中的 master 分支。
- firstBaseUpdate 与 lastBaseUpdate:表示更新前该 FiberNode 中已保存的 update,以链表的形式串联起来。链表头部为 firstBaseUpdate,链表尾部为 lastBaseUpdate。
- shared.pending:触发更新后,产生的 update 会保存在 shared.pending 中形成单向环状链表。计算 state 时,该环状链表会被拆分并拼接在 lastBaseUpdate 后面。
举例说明,例如当前有一个 FiberNode 刚经历完 commit 阶段的渲染,该 FiberNode 上面有两个“由于优先级低,导致在上一轮 render 阶段并没有被处理的 update”,假设这两个 update 分别名为 u0 和 u1
fiber.updateQueue.firstBaseUpdate = u0;
fiber.updateQueue.lastBaseUpdate = u1;
u0.next = u1;那么假设在当前的 FiberNode 上面我们又触发了两次更新,分别产生了两个 update(u2 和 u3),新产生的 update 就会形成一个环状链表,shared.pending 就会指向这个环状链表,如下图所示:

之后进入新的一轮 render,在该 FiberNode 的 beginWork 中,shared.pending 所指向的环状链表就会被拆分,拆分之后接入到 baseUpdate 链表后面:

接下来就会遍历 updateQueue.baseUpdate,基于 updateQueue.baseState 来计算每个符合优先级条件的 update(这个过程有点类似于 Array.prototype.reduce),最终计算出最新的 state,该 state 被称之为 memoizedState。
因此我们总结一下,整个 state 的计算流程可以分为两步:
- 将 shared.pending 所指向的环状链表进行拆分并且和 baseUpdate 进行拼接,形成新的链表
- 遍历连接后的链表,根据 wipRootRenderLanes 来选定优先级,基于符合优先级条件的 update 来计算 state
update 是计算 state 的最小单位,一条 updateQueue 代表由 update 所组成的链表,其中几个重要的属性列举如下:
- baseState:参与计算的初始 state,update 基于该 state 计算新的 state,可以类比为心智模型中的 master 分支。
- firstBaseUpdate 与 lastBaseUpdate:表示更新前该 FiberNode 中已保存的 update,以链表的形式串联起来。链表头部为 firstBaseUpdate,链表尾部为 lastBaseUpdate。
- shared.pending:触发更新后,产生的 update 会保存在 shared.pending 中形成单向环状链表。计算 state 时,该环状链表会被拆分并拼接在 lastBaseUpdate 后面。
整个 state 的计算流程可以分为两步:
- 将 shared.pending 所指向的环状链表进行拆分并且和 baseUpdate 进行拼接,形成新的链表
- 遍历连接后的链表,根据 wipRootRenderLanes 来选定优先级,基于符合优先级条件的 update 来计算 state
Reconciler(协调器) 是 Render 阶段的第二阶段工作,整个工作的过程可以分为“递”和“归”:
- 递:beginWork
- 归:completeWork
beginWork 方法主要是根据传入的 FiberNode 创建下一级的 FiberNode。
整个 beginWork 方法的流程如下图所示:
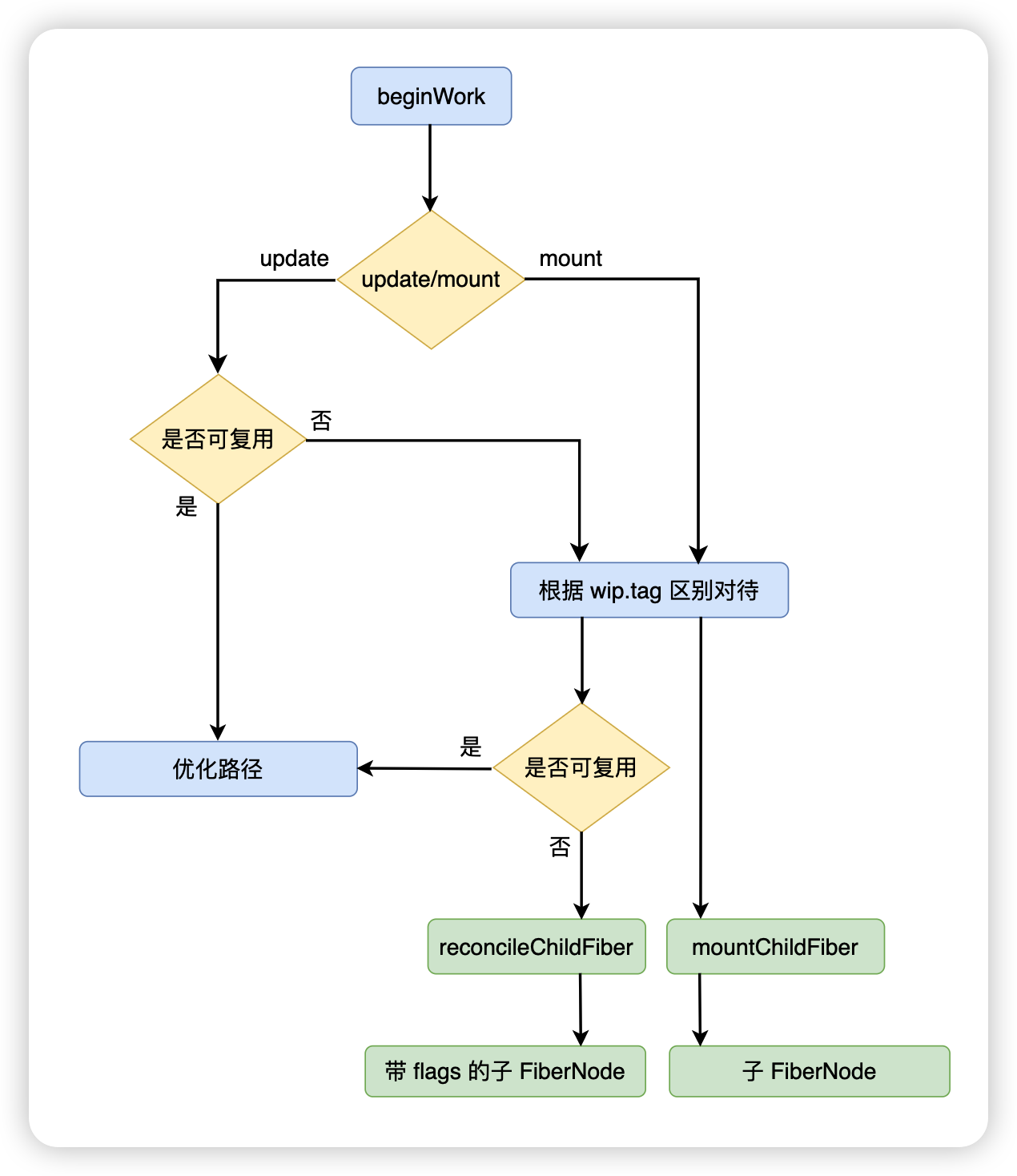
首先在 beginWork 中,会判断当前的流程是 mount(初次渲染)还是update(更新),判断的依据就是 currentFiberNode 是否存在
if(current !== null){
// 说明 CurrentFiberNode 存在,应该是 update
} else {
// 应该是 mount
}如果是 update,接下来会判断 wipFiberNode 是否能够复用,如果不能够复用,那么 update 和 mount 的流程大体上一致:
- 根据 wip.tag 进行不同的分支处理
- 根据 reconcile 算法生成下一级的 FiberNode(diff 算法)
无法复用的 update 流程和 mount 流程大体一致,主要区别在于是否会生成带副作用标记 flags 的 FiberNode
beginWork 方法的代码结构如下:
// current 代表的是 currentFiberNode
// workInProgress 代表的是 workInProgressFiberNode,后面我会简称为 wip FiberNode
function beginWork(current, workInProgress, renderLanes) {
// ...
if(current !== null) {
// 进入此分支,说明是更新
} else {
// 说明是首次渲染
}
// ...
// 根据不同的 tag,进入不同的处理逻辑
switch (workInProgress.tag) {
case IndeterminateComponent: {
// ...
}
case FunctionComponent : {
// ...
}
case ClassComponent : {
// ...
}
}
}关于 tag,在 React 源码中定义了 28 种 tag:
export const FunctionComponent = 0;
export const ClassComponent = 1;
export const IndeterminateComponent = 2; // Before we know whether it is function or class
export const HostRoot = 3; // Root of a host tree. Could be nested inside another node.
export const HostPortal = 4; // A subtree. Could be an entry point to a different renderer.
export const HostComponent = 5;
export const HostText = 6;
export const Fragment = 7;
// ...不同的 FiberNode,会有不同的 tag
- HostComponent 代表的就是原生组件(div、span、p)
- FC 在 mount 的时候,对应的 tag 为 IndeterminateComponent,在 update 的时候就会进入 FunctionComponent
- HostText 表示的是文本元素
根据不同的 tag 处理完 FiberNode 之后,根据是mount 还是 update 会进入不同的方法:
- mount:mountChildFibers
- update:reconcileChildFibers
这两个方法实际上都是一个叫 ChildReconciler 方法的返回值:
var reconcileChildFibers = ChildReconciler(true);
var mountChildFibers = ChildReconciler(false);
function ChildReconciler(shouldTrackSideEffects) {}也就是说,在 ChildReconciler 方法内容,shouldTrackSideEffects 是一个布尔值
- false:不追踪副作用,不做 flags 标记,因为你是 mount 阶段
- true:要追踪副作用,做 flags 标记,因为是 update 阶段
在 ChildReconciler 方法内部,就会根据 shouldTrackSideEffects 做一些不同的处理:
function placeChild(newFiber, lastPlacedIndex, newIndex){
newFiber.index = newIndex;
if(!shouldTrackSideEffects){
// 说明是初始化
// 说明不需要标记 Placement
newFiber.flags |= Forked;
return lastPlacedIndex
}
// ...
// 说明是更新
// 标记为 Placement
newFiber.flags |= Placement;
}可以看到,在 beginWork 方法内部,也会做一些 flags 标记(主要是在 update 阶段),这些 flags 标记主要和元素的位置有关系:
- 标记 ChildDeletion,这个是代表删除操作
- 标记 Placement,这是代表插入或者移动操作
题目:beginWork 中主要做一些什么工作?整体的流程是怎样的?
参考答案:
在 beginWork 会根据是 mount 还是 update 有着不一样的流程。
如果当前的流程是 update,则 WorkInProgressFiberNode 存在对应的 CurrentFiberNode,接下来就判断是否能够复用。
如果无法复用 CurrentFiberNode,那么 mount 和 update 的流程大体上是一致的:
- 根据 wip.tag 进入“不同类型元素的处理分支”
- 使用 reconcile 算法生成下一级 FiberNode(diff 算法)
两个流程的区别在于“最终是否会为生成的子 FiberNode 标记副作用 flags”
在 beginWork 中,如果标记了副作用的 flags,那么主要与元素的位置相关,包括:
- 标记 ChildDeletion,代表删除操作
- 标记 Placement,代表插入或移动操作
前面所介绍的 beginWork,是属于“递”的阶段,该阶段的工作处理完成后,就会进入到 completeWork,这个是属于“归”的阶段。
与 beginWork 类似,completeWork 也会根据 wip.tag 区分对待,流程上面主要包括两个步骤:
- 创建元素或者标记元素的更新
- flags 冒泡
整体流程图如下:

在 mount 流程中,首先会通过 createInstance 创建 FiberNode 所对应的 DOM 元素:
function createInstance(type, props, rootContainerInstance, hostContext, internalInstanceHandle){
//...
if(typeof props.children === 'string' || typeof props.chidlren === 'number'){
// children 为 string 或者 number 时做一些特殊处理
}
// 创建 DOM 元素
const domElement = createElement(type, props, rootContainerInstance, parentNamespace);
//...
return domElement;
}接下来会执行 appendAllChildren,该方法的作用是将下一层 DOM 元素插入到通过 createInstance 方法所创建的 DOM 元素中,具体的逻辑如下:
- 从当前的 FiberNode 向下遍历,将遍历到的第一层 DOM 元素类型(HostComponent、HostText)通过 appendChild 方法插入到 parent 末尾
- 对兄弟 FiberNode 执行步骤 1
- 如果没有兄弟 FiberNode,则对父 FiberNode 的兄弟执行步骤 1
- 当遍历流程回到最初执行步骤 1 所在层或者 parent 所在层时终止
相关的代码如下:
appendAllChildren = function(parent, workInProgress, ...){
let node = workInProgress.child;
while(node !== null){
// 步骤 1,向下遍历,对第一层 DOM 元素执行 appendChild
if(node.tag === HostComponent || node.tag === HostText){
// 对 HostComponent、HostText 执行 appendChild
appendInitialChild(parent, node.stateNode);
} else if(node.child !== null) {
// 继续向下遍历,直到找到第一层 DOM 元素类型
node.child.return = node;
node = node.child;
continue;
}
// 终止情况 1: 遍历到 parent 对应的 FiberNode
if(node === workInProgress) {
return;
}
// 如果没有兄弟 FiberNode,则向父 FiberNode 遍历
while(node.sibling === null){
// 终止情况 2: 回到最初执行步骤 1 所在层
if(node.return === null || node.return === workInProgress) {
return;
}
node = node.return
}
// 对兄弟 FiberNode 执行步骤 1
node.sibling.return = node.return;
node = node.sibling;
}
}appendAllChildren 方法实际上就是在处理下一级的 DOM 元素,而且在 appendAllChildren 里面的遍历过程会更复杂一些,会多一些判断,因为 FiberNode 最终形成的 FiberTree 的层次和最终 DOMTree 的层次可能是有区别:
function World(){
return <span>World</span>
}
<div>
Hello
<World/>
</div>在上面的代码中,如果从 FiberNode 的角度来看,Hello 和 World 是同级的,但是如果从 DOM 元素的角度来看,Hello 就和 span 是同级别的。因此从 FiberNode 中查找同级的 DOM 元素的时候,经常会涉及到跨 FiberNode 层级进行查找。
接下来 completeWork 会执行 finalizeInitialChildren 方法完成属性的初始化,主要包含以下几类属性:
- styles,对应的方法为 setValueForStyles 方法
- innerHTML,对应 setInnerHTML 方法
- 文本类型 children,对应 setTextContent 方法
- 不会再在 DOM 中冒泡的事件,包括 cancel、close、invalid、load、scroll、toggle,对应的是 listenToNonDelegatedEvent 方法
- 其他属性,对应 setValueForProperty 方法
该方法执行完毕后,最后进行 flags 的冒泡。
总结一下,completeWork 在 mount 阶段执行的工作流程如下:
- 根据 wip.tag 进入不同的处理分支
- 根据 current !== null 区分是 mount 还是 update
- 对应 HostComponent,首先执行 createInstance 方法来创建对应的 DOM 元素
- 执行 appendChildren 将下一级 DOM 元素挂载在上一步所创建的 DOM 元素下
- 执行 finalizeInitialChildren 完成属性初始化
- 执行 bubbleProperties 完成 flags 冒泡
上面的 mount 流程,完成的是属性的初始化,那么这个 update 流程,完成的就是属性更新的标记
updateHostComponent 的主要逻辑是在 diffProperties 方法里面,这个方法会包含两次遍历:
- 第一次遍历,主要是标记更新前有,更新没有的属性,实际上也就是标记删除了的属性
- 第二次遍历,主要是标记更新前后有变化的属性,实际上也就是标记更新了的属性
相关代码如下:
function diffProperties(domElement, tag, lastRawProps, nextRawProps, rootContainer){
// 保存变化属性的 key、value
let updatePayload = null;
// 更新前的属性
let lastProps;
// 更新后的属性
let nextProps;
//...
// 标记删除“更新前有,更新后没有”的属性
for(propKey in lastProps){
if(nextProps.hasOwnProperty(propKey) || !lastProps.hasOwnProperty(propKey) || lastProps[propKey] == null){
continue;
}
if(propKey === STYLE){
// 处理 style
} else {
//其他属性
(updatePayload = updatePayload || []).push(propKey, null);
}
}
// 标记更新“update流程前后发生改变”的属性
for(propKey in lastProps){
let nextProp = nextProps[propKey];
let lastProp = lastProps != null ? lastProps[propKey] : undefined;
if(!nextProps.hasOwnProperty(propKey) || nextProp === lastProp || nextProp == null && lastProp == null){
continue;
}
if(propKey === STYLE) {
// 处理 stlye
} else if(propKey === DANGEROUSLY_SET_INNER_HTML){
// 处理 innerHTML
} else if(propKey === CHILDREN){
// 处理单一文本类型的 children
} else if(registrationNameDependencies.hasOwnProperty(propKey)) {
if(nextProp != null) {
// 处理 onScroll 事件
} else {
// 处理其他属性
}
}
}
//...
return updatePayload;
}所有更新了的属性的 key 和 value 会保存在当前 FiberNode.updateQueue 里面,数据是以 key、value 作为数组相邻的两项的形式进行保存的
export default ()=>{
const [num, updateNum] = useState(0);
return (
<div
onClick = {()=>updateNum(num + 1)}
style={{color : `#${num}${num}${num}`}}
title={num + ''}
></div>
);
}点击 div 元素触发更新,那么这个时候 style、title 属性会发生变化,变化的数据会以下面的形式保存在 FiberNode.updateQueue 里面:
["title", "1", "style", {"color": "#111"}]并且,当前的 FiberNode 会标记 Update:
workInProgress.flags |= Update;我们知道,当整个 Reconciler 完成工作后,会得到一颗完整的 wipFiberTree,这颗 wipFiberTree 是由一颗一颗 FiberNode 组成的,这些 FiberNode 中有一些标记了 flags,有一些没有标记,现在就存在一个问题,我们如何高效的找到散落在这颗 wipFiberTree 中有 flag 标记的 FiberNode,那么此时就可以通过 flags 冒泡。
我们知道,completeWork 是属于归的阶段,整体流程是自下往上,就非常适合用来收集副作用,收集的相关的代码如下:
let subtreeFlags = NoFlags;
// 收集子 FiberNode 的子孙 FiberNode 中标记的 flags
subtreeFlags |= child.subtreeFlags;
// 收集子 FiberNode 中标记的 flags
subtreeFlags |= child.flags;
// 将收集到的所有 flags 附加到当前 FiberNode 的 subtreeFlags 上面
completeWork.subtreeFlags |= subtreeFlags;这样的收集方式,有一个好处,在渲染阶段,通过任意一级的 FiberNode.subtreeFlags 都可以快速确定该 FiberNode 以及子树是否存在副作用从而判断是否需要执行和副作用相关的操作。
早期的时候,React 中实际上并没有使用 subtreeFlags 来通过 flags 冒泡收集副作用,而是使用的 effect list(链表)来收集的副作用,使用 subtreeFlags 有一个好处,就是能确定某一个 FiberNode 它的子树的副作用。
题目:completeWork 中主要做一些什么工作?整体的流程是怎样的?
参考答案:
completeWork 会根据 wip.tag 区分对待,流程大体上包括如下的两个步骤:
- 创建元素(mount)或者标记元素更新(update)
- flags 冒泡
completeWork 在 mount 时的流程如下:
- 根据 wip.tag 进入不同的处理分支
- 根据 current !== null 区分是 mount 还是 update
- 对应 HostComponent,首先执行 createInstance 方法来创建对应的 DOM 元素
- 执行 appendChildren 将下一级 DOM 元素挂载在上一步所创建的 DOM 元素下
- 执行 finalizeInitialChildren 完成属性初始化
- 执行 bubbleProperties 完成 flags 冒泡
completeWork 在 update 时的主要是标记属性的更新。
updateHostComponent 的主要逻辑是在 diffProperties 方法中,该方法包括两次遍历:
- 第一次遍历,标记删除“更新前有,更新后没有”的属性
- 第二次遍历,标记更新“update流程前后发生改变”的属性
无论是 mount 还是 update,最终都会进行 flags 的冒泡。
flags 冒泡的目的是为了找到散落在 WorkInProgressFiberTree 各处的被标记了的 FiberNode,对“被标记的 FiberNode 所对应的 DOM 元素”执行 flags 对应的 DOM 操作。
FiberNode.subtreeFlags 记录了该 FiberNode 的所有子孙 FiberNode 上被标记的 flags。而每个 FiberNode 经由如下操作,便可以将子孙 FiberNode 中标记的 flags 向上冒泡一层。
Fiber 架构的早期版本并没有使用 subtreeFlags,而是使用一种被称之为 Effect list 的链表结构来保存“被标记副作用的 FiberNode”。
但在 React v18 版本中使用了 subtreeFlags 替换了 Effect list,原因是因为 v18 中的 Suspense 的行为恰恰需要遍历子树。
整个 React 的工作流程可以分为两大阶段:
- Render 阶段
- Schedule
- Reconcile
- Commit 阶段
注意,Render 阶段的行为是在内存中运行的,这意味着可能被打断,也可以被打断,而 commit 阶段则是一旦开始就会同步执行直到完成。
commit 阶段整体可以分为 3 个子阶段:
- BeforeMutation 阶段
- Mutation 阶段
- Layout 阶段
整体流程图如下:

每个阶段,又分为三个子阶段:
- commitXXXEffects
- commitXXXEffects_begin
- commitXXXEffects_complete
所分成的这三个子阶段,是有一些共同的事情要做的
commitXXXEffects
该函数是每个子阶段的入口函数,finishedWork 会作为 firstChild 参数传入进去,相关代码如下:
function commitXXXEffects(root, firstChild){
nextEffect = firstChild;
// 省略标记全局变量
commitXXXEffects_begin();
// 省略重置全局变量
}因此在该函数中,主要的工作就是将 firstChild 赋值给全局变量 nextEffect,然后执行 commitXXXEffects_begin
commitXXXEffects_begin
向下遍历 FiberNode。遍历的时候会遍历直到第一个满足如下条件之一的 FiberNode:
- 当前的 FiberNode 的子 FiberNode 不包含该子阶段对应的 flags
- 当前的 FiberNode 不存在子 FiberNode
接下来会对目标 FiberNode 执行 commitXXXEffects_complete 方法,commitXXXEffects_begin 相关代码如下:
function commitXXXEffects_begin(){
while(nextEffect !== null) {
let fiber = nextEffect;
let child = fiber.child;
// 省略该子阶段的一些特有操作
if(fiber.subtreeFlags !== NoFlags && child !== null){
// 继续向下遍历
nextEffect = child;
} else {
commitXXXEffects_complete();
}
}
}commitXXXEffects_complete
该方法主要就是针对 flags 做具体的操作了,主要包含以下三个步骤:
- 对当前 FiberNode 执行 flags 对应的操作,也就是执行 commitXXXEffectsOnFiber
- 如果当前 FiberNode 存在兄弟 FiberNode,则对兄弟 FiberNode 执行 commitXXXEffects_begin
- 如果不存在兄弟 FiberNode,则对父 FiberNode 执行 commitXXXEffects_complete
相关代码如下:
function commitXXXEffects_complete(root){
while(nextEffect !== null){
let fiber = nextEffect;
try{
commitXXXEffectsOnFiber(fiber, root);
} catch(error){
// 错误处理
}
let sibling = fiber.sibling;
if(sibling !== null){
// ...
nextEffect = sibling;
return
}
nextEffect = fiber.return;
}
}总结一下,每个子阶段都会以 DFS 的原则来进行遍历,最终会在 commitXXXEffectsOnFiber 中针对不同的 flags 做出不同的处理。
BeforeMutation 阶段的主要工作发生在 commitBeforeMutationEffects_complete 中的 commitBeforeMutationEffectsOnFiber 方法,相关代码如下:
function commitBeforeMutationEffectsOnFiber(finishedWork){
const current = finishedWork.alternate;
const flags = finishedWork.falgs;
//...
// Snapshot 表示 ClassComponent 存在更新,且定义了 getSnapsshotBeforeUpdate 方法
if(flags & Snapshot !== NoFlags) {
switch(finishedWork.tag){
case ClassComponent: {
if(current !== null){
const prevProps = current.memoizedProps;
const prevState = current.memoizedState;
const instance = finishedWork.stateNode;
// 执行 getSnapsshotBeforeUpdate
const snapshot = instance.getSnapsshotBeforeUpdate(
finishedWork.elementType === finishedWork.type ?
prevProps : resolveDefaultProps(finishedWork.type, prevProps),
prevState
)
}
break;
}
case HostRoot: {
// 清空 HostRoot 挂载的内容,方便 Mutation 阶段渲染
if(supportsMutation){
const root = finishedWork.stateNode;
clearCOntainer(root.containerInfo);
}
break;
}
}
}
}上面代码的整个过程中,主要是处理如下两种类型的 FiberNode:
- ClassComponent:执行 getSnapsshotBeforeUpdate 方法
- HostRoot:清空 HostRoot 挂载的内容,方便 Mutation 阶段进行渲染
对于 HostComponent,Mutation 阶段的主要工作就是对 DOM 元素及进行增、删、改
删除 DOM 元素相关代码如下:
function commitMutationEffects_begin(root){
while(nextEffect !== null){
const fiber = nextEffect;
// 删除 DOM 元素
const deletions = fiber.deletions;
if(deletions !== null){
for(let i=0;i<deletions.length;i++){
const childToDelete = deletions[i];
try{
commitDeletion(root, childToDelete, fiber);
} catch(error){
// 省略错误处理
}
}
}
const child = fiber.child;
if((fiber.subtreeFlags & MutationMask) !== NoFlags && child !== null){
nextEffect = child;
} else {
commitMutationEffects_complete(root);
}
}
}删除 DOM 元素的操作发生在 commitMutationEffects_begin 方法中,首先会拿到 deletions 数组,之后遍历该数组进行删除操作,对应删除 DOM 元素的方法为 commitDeletion。
commitDeletion 方法内部的完整逻辑实际上是比较复杂的,原因是因为在删除一个 DOM 元素的时候,不是说删除就直接删除,还需要考虑以下的一些因素:
- 其子树中所有组件的 unmount 逻辑
- 其子树中所有 ref 属性的卸载操作
- 其子树中所有 Effect 相关 Hook 的 destory 回调的执行
假设有如下的代码:
<div>
<SomeClassComponent/>
<div ref={divRef}>
<SomeFunctionComponent/>
</div>
</div>当你删除最外层的 div 这个 DOM 元素时,需要考虑:
- 执行 SomeClassComponent 类组件对应的 componentWillUnmount 方法
- 执行 SomeFunctionComponent 函数组件中的 useEffect、useLayoutEffect 这些 hook 中的 destory 方法
- divRef 的卸载操作
整个删除操作是以 DFS 的顺序,遍历子树的每个 FiberNode,执行对应的操作。
上面的删除操作是在 commitMutationEffects_begin 方法里面执行的,而插入和移动 DOM 元素则是在 commitMutationEffects_complete 方法里面的 commitMutationEffectsOnFiber 方法里面执行的,相关代码如下:
function commitMutationEffectsOnFiber(finishedWork, root){
const flags = finishedWork.flags;
// ...
const primaryFlags = flags & (Placement | Update | Hydrating);
outer: switch(primaryFlags){
case Placement:{
// 执行 Placement 对应操作
commitPlacement(finishedWork);
// 执行完 Placement 对应操作后,移除 Placement flag
finishedWork.falgs &= ~Placement;
break;
}
case PlacementAndUpdate:{
// 执行 Placement 对应操作
commitPlacement(finishedWork);
// 执行完 Placement 对应操作后,移除 Placement flag
finishedWork.falgs &= ~Placement;
// 执行 Update 对应操作
const current = finishedWork.alternate;
commitWork(current, finishedWork);
break;
}
// ...
}
}可以看出, Placement flag 对应的操作方法为 commitPlacement,代码如下:
function commitPlacement(finishedWork){
// 获取 Host 类型的祖先 FiberNode
const parentFiber = getHostParentFiber(finishedWork);
// 省略根据 parentFiber 获取对应 DOM 元素的逻辑
let parent;
// 目标 DOM 元素会插入至 before 左边
const before = getHostSibling(finishedWork);
// 省略分支逻辑
// 执行插入或移动操作
insertOrAppendPlacementNode(finishedWork, before, parent);
}整个 commitPlacement 方法的执行流程可以分为三个步骤:
- 从当前 FiberNode 向上遍历,获取第一个类型为 HostComponent、HostRoot、HostPortal 三者之一的祖先 FiberNode,其对应的 DOM 元素是执行 DOM 操作的目标元素的父级 DOM 元素
- 获取用于执行 parentNode.insertBefore(child, before) 方法的 “before 对应的 DOM 元素”
- 执行 parentNode.insertBefore 方法(存在 before)或者 parentNode.appendChild 方法(不存在 before)
对于“还没有插入的DOM元素”(对应的就是 mount 场景),insertBefore 会将目标 DOM 元素插入到 before 之前,appendChild 会将目标DOM元素作为父DOM元素的最后一个子元素插入
对于“UI中已经存在的 DOM 元素”(对应 update 场景),insertBefore 会将目标 DOM 元素移动到 before 之前,appendChild 会将目标 DOM 元素移动到同级最后。
因此这也是为什么在 React 中,插入和移动所对应的 flag 都是 Placement flag 的原因。(可能面试的时候会被问到)
更新 DOM 元素,一个最主要的工作就是更新对应的属性,执行的方法为 commitWork,相关代码如下:
function commitWork(current, finishedWork){
switch(finishedWork.tag){
// 省略其他类型处理逻辑
case HostComponent:{
const instance = finishedWork.stateNode;
if(instance != null){
const newProps = finishedWork.memoizedProps;
const oldProps = current !== null ? current.memoizedProps : newProps;
const type = finishedWork.type;
const updatePayload = finishedWork.updateQueue;
finishedWork.updateQueue = null;
if(updatePayload !== null){
// 存在变化的属性
commitUpdate(instance, updatePayload, type, oldProps, newProps, finishedWork);
}
}
return;
}
}
}之前有讲过,变化的属性会以 key、value 相邻的形式保存在 FiberNode.updateQueue ,最终在 FiberNode.updateQueue 里面所保存的要变化的属性就会在一个名为 updateDOMProperties 方法被遍历然后进行处理,这里的处理主要是处理如下的四种数据:
- style 属性变化
- innerHTML
- 直接文本节点变化
- 其他元素属性
相关代码如下:
function updateDOMProperties(domElement, updatePayload, wasCustomComponentTag, isCustomComponentTag){
for(let i=0;i< updatePayload.length; i+=2){
const propKey = updatePayload[i];
const propValue = updatePayload[i+1];
if(propKey === STYLE){
// 处理 style
setValueForStyle(domElement, propValue);
} else if(propKey === DANGEROUSLY_SET_INNER_HTML){
// 处理 innerHTML
setInnerHTML(domElement, propValue);
} else if(propsKey === CHILDREN){
// 处理直接的文本节点
setTextContent(domElement, propValue);
} else {
// 处理其他元素
setValueForProperty(domElement, propKey, propValue, isCustomComponentTag);
}
}
}当 Mutation 阶段的主要工作完成后,在进入 Layout 阶段之前,会执行如下的代码来完成 FiberTree 的切换:
root.current = finishedWork;有关 DOM 元素的操作,在 Mutation 阶段已经结束了。
在 Layout 阶段,主要的工作集中在 commitLayoutEffectsOnFiber 方法中,在该方法内部,会针对不同类型的 FiberNode 执行不同的操作:
- 对于 ClassComponent:该阶段会执行 componentDidMount/Update 方法
- 对于 FunctionComponent:该阶段会执行 useLayoutEffect 的回调函数
题目:commit 阶段的工作流程是怎样的?此阶段可以分为哪些模块?每个模块在做什么?
参考答案:
整个 commit 可以分为三个子阶段
- BeforeMutation 阶段
- Mutation 阶段
- Layout 阶段
每个子阶段又可以分为 commitXXXEffects、commitXXXEffects_beigin 和 commitXXXEffects_complete
其中 commitXXXEffects_beigin 主要是在做遍历节点的操作,commitXXXEffects_complete 主要是在处理副作用
BeforeMutation 阶段整个过程主要处理如下两种类型的 FiberNode:
- ClassComponent,执行 getSnapsshotBeforeUpdate 方法
- HostRoot,清空 HostRoot 挂载的内容,方便 Mutation 阶段渲染
对于 HostComponent,Mutation 阶段的工作主要是进行 DOM 元素的增、删、改。当 Mutation 阶段的主要工作完成后,在进入 Layout 阶段之前,会执行如下的代码完成 Fiber Tree 的切换。
Layout 阶段会对遍历到的每个 FiberNode 执行 commitLayoutEffectOnFiber,根据 FiberNode 的不同,执行不同的操作,例如:
- 对于 ClassComponent,该阶段执行 componentDidMount/Update 方法
- 对于 FunctionComponent,该阶段执行 useLayoutEffect callback 方法
思考:Hook是如何保存函数组件状态的?为什么不能在循环,条件或嵌套函数中调用 Hook ?
在 React 中,针对 Hook 有三种策略,或者说三种类型的 dispatcher:
- HooksDispatcherOnMount:负责初始化工作,让函数组件的一些初始化信息挂载到 Fiber 上面
/* 函数组件初始化用的 hooks */
const HooksDispatcherOnMount: Dispatcher = {
readContext,
...
useCallback: mountCallback,
useEffect: mountEffect,
useMemo: mountMemo,
useReducer: mountReducer,
useRef: mountRef,
useState: mountState,
...
};- HoosDispatcherOnUpdate:函数组件进行更新的时候,会执行该对象所对应的方法。此时 Fiber 上面已经存储了函数组件的相关信息,这些 Hook 需要做的就是去获取或者更新维护这些 FIber 的信息
/* 函数组件更新用的 hooks */
const HooksDispatcherOnUpdate: Dispatcher = {
readContext,
...
useCallback: updateCallback,
useContext: readContext,
useEffect: updateEffect,
useMemo: updateMemo,
useReducer: updateReducer,
useRef: updateRef,
useState: updateState,
...
};- ContextOnlyDispatcher:这个是和报错相关,防止开发者在函数组件外部调用 Hook
/* 当hooks不是函数组件内部调用的时候,调用这个hooks对象下的hooks,所以报错。 */
export const ContextOnlyDispatcher: Dispatcher = {
readContext,
...
useCallback: throwInvalidHookError,
useContext: throwInvalidHookError,
useEffect: throwInvalidHookError,
useMemo: throwInvalidHookError,
useReducer: throwInvalidHookError,
useRef: throwInvalidHookError,
useState: throwInvalidHookError,
...
};总结一下:
- mount 阶段:函数组件是进行初始化,那么此时调用的就是 mountXXX 对应的函数
- update 阶段:函数组件进行状态的更新,调用的就是 updateXXX 对应的函数
- 其他场景下(报错):此时调用的就是 throwInvaildError
当 FC 进入到 render 流程的时候,首先会判断是初次渲染还是更新:
if(current !== null && current.memoizedState !== null) {
// 说明是 update
ReactCurrentDispatcher.current = HooksDispatcherOnUpdate;
} else {
// 说明是 mount
ReactCurrentDispatcher.current = HooksDispatcherOnMount;
}判断了是mount还是update之后,会给 ReactCurrentDispatcher.current 赋值对应的 dispatcher,因为赋值了不同的上下文对象,因此就可以根据不同上下文对象调用不同的方法。
假设有嵌套的 hook:
useEffect(()=>{
useState(0);
})那么此时的上下文对象指向 ContextOnlyDispatcher,最终执行的就是 throwInvalidHookError,抛出错误。
接下来我们来看一下 hook 的一个数据结构
const hook = {
memoizedState: null,
baseState: null,
baseQueue: null,
queue: null,
next: null
}这里需要注意 memoizedState 字段,因为在 FiberNode 上面也有这么一个字段,与 Hook 对象上面的 memoizedState 存储的东西是不一样的:
- FiberNode.memoizedState:保存的是 Hook 链表里面的第一个链表
- hook.memoizedState:某个 hook 自身的数据
不同类型的 hook,hook.memoizedState 所存储的内容也是不同的:
- useState:对于 const [state, updateState] = useState(initialState),memoizedState 保存的是 state 的值
- useReducer:对于 const [state, dispatch] = useReducer(reducer, { } ),memoizedState 保存的是 state 的值
- useEffect:对于 useEffect( callback, [...deps] ),memoizedState 保存的是 callback、[...deps] 等数据
- useRef:对于 useRef(initialValue),memoizedState 保存的是 { current: initialValue}
- useMemo:对于 useMemo( callback, [...deps] ),memoizedState 保存的是 [callback( )、[...deps]] 数据
- useCallback:对于 useCallback( callback, [...deps] ),memoizedState 保存的是 [callback、[...deps]] 数据
有些 Hook 不需要 memoizedState 保存自身数据,比如 useContext。
当 FC 进入到 render 阶段时,会被 renderWithHooks 函数处理执行:
export function renderWithHooks(current, workInProgress, Component, props, secondArg, nextRenderLanes) {
renderLanes = nextRenderLanes;
currentlyRenderingFiber = workInProgress;
// 每一次执行函数组件之前,先清空状态 (用于存放hooks列表)
workInProgress.memoizedState = null;
// 清空状态(用于存放effect list)
workInProgress.updateQueue = null;
// ...
// 判断组件是初始化流程还是更新流程
// 如果初始化用 HooksDispatcherOnMount 对象
// 如果更新用 HooksDispatcherOnUpdate 对象
// 初始化对应的上下文对象,不同的上下文对象对应了一组不同的方法
ReactCurrentDispatcher.current =
current === null || current.memoizedState === null
? HooksDispatcherOnMount
: HooksDispatcherOnUpdate;
// 执行我们真正函数组件,所有的 hooks 将依次执行。
let children = Component(props, secondArg);
// ...
// 判断环境
finishRenderingHooks(current, workInProgress);
return children;
}
function finishRenderingHooks(current, workInProgress) {
// 防止 hooks 在函数组件外部调用,如果调用直接报错
ReactCurrentDispatcher.current = ContextOnlyDispatcher;
// ...
}renderWithHooks 会被每次函数组件触发时(mount、update),该方法就会清空 workInProgress 的 memoizedState 以及 updateQueue,接下来判断该组件究竟是初始化还是更新,为 ReactCurrentDispatcher.current 赋值不同的上下文对象,之后调用
Component 方法来执行函数组件,组件里面所书写的 hook 就会依次执行。
接下来我们来以 useState 为例看一下整个 hook 的执行流程:
function App(){
const [count, setCount] = useState(0);
return <div onClick={()=>setCount(count+1)}>{count}</div>
}接下来就会根据你是 mount 还是 update 调用不同上下文里面所对应的方法。
mount 阶段调用的是 mountState,相关代码如下:
function mountState(initialState) {
// 1. 拿到 hook 对象链表
const hook = mountWorkInProgressHook();
if (typeof initialState === "function") {
initialState = initialState();
}
// 2. 初始化hook的属性
// 2.1 设置 hook.memoizedState/hook.baseState
hook.memoizedState = hook.baseState = initialState;
const queue = {
pending: null,
lanes: NoLanes,
dispatch: null,
lastRenderedReducer: basicStateReducer,
lastRenderedState: initialState,
};
// 2.2 设置 hook.queue
hook.queue = queue;
// 2.3 设置 hook.dispatch
const dispatch = (queue.dispatch = dispatchSetState.bind(
null,
currentlyRenderingFiber,
queue
));
// 3. 返回[当前状态, dispatch函数]
return [hook.memoizedState, dispatch];
}上面在执行 mountState 的时候,首先调用了 mountWorkInProgressHook,该方法的作用就是创建一个 hook 对象,相关代码如下:
function mountWorkInProgressHook() {
const hook = {
memoizedState: null, // Hook 自身维护的状态
baseState: null,
baseQueue: null,
queue: null, // Hook 自身维护的更新队列
next: null, // next 指向下一个 Hook
};
// 最终 hook 对象是要以链表形式串联起来,因此需要判断当前的 hook 是否是链表的第一个
if (workInProgressHook === null) {
// 如果当前组件的 Hook 链表为空,那么就将刚刚新建的 Hook 作为 Hook 链表的第一个节点(头结点)
// This is the first hook in the list
currentlyRenderingFiber.memoizedState = workInProgressHook = hook;
} else {
// 如果当前组件的 Hook 链表不为空,那么就将刚刚新建的 Hook 添加到 Hook 链表的末尾(作为尾结点)
// Append to the end of the list
workInProgressHook = workInProgressHook.next = hook;
}
return workInProgressHook;
}假设现在我们有如下的一个组件:
function App() {
const [number, setNumber] = React.useState(0); // 第一个hook
const [num, setNum] = React.useState(1); // 第二个hook
const dom = React.useRef(null); // 第三个hook
React.useEffect(() => {
// 第四个hook
console.log(dom.current);
}, []);
return (
<div ref={dom}>
<div onClick={() => setNumber(number + 1)}> {number} </div>
<div onClick={() => setNum(num + 1)}> {num}</div>
</div>
);
}当上面的函数组件第一次进行初始化后,就会形成一个 hook 的链表:

接下来我们来看一下更新,更新的时候会执行 updateXXX 对应的方法,相关的代码如下:
function updateWorkInProgressHook() {
let nextCurrentHook;
if (currentHook === null) {
// 从 alternate 上获取到 fiber 对象
const current = currentlyRenderingFiber.alternate;
if (current !== null) {
// 拿到第一个 hook 对象
nextCurrentHook = current.memoizedState;
} else {
nextCurrentHook = null;
}
} else {
// 拿到下一个 hook
nextCurrentHook = currentHook.next;
}
// 更新 workInProgressHook 的指向
// 让 workInProgressHook 指向最新的 hook
let nextWorkInProgressHook; // 下一个要进行工作的 hook
if (workInProgressHook === null) {
// 当前是第一个,直接从 fiber 上获取第一个 hook
nextWorkInProgressHook = currentlyRenderingFiber.memoizedState;
} else {
// 取链表的下一个 hook
nextWorkInProgressHook = workInProgressHook.next;
}
// nextWorkInProgressHook 指向的是当前要工作的 hook
if (nextWorkInProgressHook !== null) {
// There's already a work-in-progress. Reuse it.
// 进行复用
workInProgressHook = nextWorkInProgressHook;
nextWorkInProgressHook = workInProgressHook.next;
currentHook = nextCurrentHook;
} else {
// Clone from the current hook.
// 进行克隆
if (nextCurrentHook === null) {
const currentFiber = currentlyRenderingFiber.alternate;
if (currentFiber === null) {
// This is the initial render. This branch is reached when the component
// suspends, resumes, then renders an additional hook.
const newHook = {
memoizedState: null,
baseState: null,
baseQueue: null,
queue: null,
next: null,
};
nextCurrentHook = newHook;
} else {
// This is an update. We should always have a current hook.
throw new Error("Rendered more hooks than during the previous render.");
}
}
currentHook = nextCurrentHook;
const newHook = {
memoizedState: currentHook.memoizedState,
baseState: currentHook.baseState,
baseQueue: currentHook.baseQueue,
queue: currentHook.queue,
next: null,
};
// 之后的操作和 mount 时候一样
if (workInProgressHook === null) {
// This is the first hook in the list.
currentlyRenderingFiber.memoizedState = workInProgressHook = newHook;
} else {
// Append to the end of the list.
workInProgressHook = workInProgressHook.next = newHook;
}
}
return workInProgressHook;
}在上面的源码中,有一个非常关键的信息:
// ...
if (nextWorkInProgressHook !== null) {
// There's already a work-in-progress. Reuse it.
// 进行复用
workInProgressHook = nextWorkInProgressHook;
nextWorkInProgressHook = workInProgressHook.next;
currentHook = nextCurrentHook;
}
// ...这里如果 nextWorkInProgressHook 不为 null,那么就会复用之前的 hook,这里其实也就解释了为什么 hook 不能放在条件或者循环语句里面
面试题:hook 为什么通常放在顶部,而且不能写在条件或者循环语句里面?
因为更新的过程中,如果通过 if 条件增加或者删除了 hook,那么在复用的时候,就会产生当前hook 的顺序和之前 hook 的顺序不一致的问题。
例如,我们将上面的代码进行修改:
function App({ showNumber }) {
let number, setNumber
showNumber && ([ number,setNumber ] = React.useState(0)) // 第一个hooks
const [num, setNum] = React.useState(1); // 第二个hook
const dom = React.useRef(null); // 第三个hook
React.useEffect(() => {
// 第四个hook
console.log(dom.current);
}, []);
return (
<div ref={dom}>
<div onClick={() => setNumber(number + 1)}> {number} </div>
<div onClick={() => setNum(num + 1)}> {num}</div>
</div>
);
}假设第一次父组件传递过来的 showNumber 为 true,此时就会渲染第一个 hook,第二次渲染的时候,假设父组件传递过来的是 false,那么第一个 hook 就不会执行,那么逻辑就会变得如下表所示:
| hook 链表顺序 | 第一次 | 第二次 |
|---|---|---|
| 第一个 hook | useState | useState |
| 第二个 hook | useState | useRef |
那么此时在进行复用的时候就会报错:

第二次复用的时候,发现 hook 的类型不同, useState !==useRef,那么就会直接报错。因此开发的时候一定要注意 hook 顺序的一致性。

题目:Hook是如何保存函数组件状态的?为什么不能在循环,条件或嵌套函数中调用 Hook ?
首先 Hook 是一个对象,大致有如下的结构:
const hook = { memoizedState: null, baseState: null, baseQueue: null, queue: null, next: null }不同类型的 hook,hook 的 memoizedState 中保存了不同的值,例如:
- useState:对于 const [state, updateState] = useState(initialState),memoizedState 保存的是 state 的值
- useEffect:对于 useEffect( callback, [...deps] ),memoizedState 保存的是 callback、[...deps] 等数据
一个组件中的 hook 会以链表的形式串起来,FiberNode 的 memoizedState 中保存了 Hooks 链表中的第一个 Hook
在更新时,会复用之前的 Hook,如果通过 if 条件语句,增加或者删除 hooks,在复用 hooks 过程中,会产生复用 hooks 状态和当前 hooks 不一致的问题。
useState 我们已经非常熟悉了,如下:
function App(){
const [num, setNum] = useState(0);
return <div onClick={()=>setNum(num + 1)}>{num}</div>;
}接下来我们来看一下 useReducer。如果你会 redux,那么 useReducer 对你来讲是非常熟悉的。
const [state, dispatch] = useReducer(
reducer,
initialArg,
init
);接下来我们来看一个计数器的例子:
import { useReducer, useRef } from "react";
// 定义一个初始化的状态
const initialState = { count: 0 };
/**
* reducer
* @param {*} state 状态
* @param {*} action 数据变化的描述对象
*/
function counter(state, action) {
switch (action.type) {
case "INCREMENT":
return { count: state.count + action.payload };
case "DECREMENT":
return { count: state.count - action.payload };
default:
return state;
}
}
function App() {
// const [num, setNum] = useState(0);
// 后期要修改值的时候,都是通过 dispatch 来进行修改
const [state, dispatch] = useReducer(counter, initialState);
const selRef = useRef();
const increment = () => {
// 做自增操作
// 1. 你要增加多少?
const num = selRef.current.value * 1;
// setNum(num);
dispatch({
type: "INCREMENT",
payload: num,
});
};
const decrement = () => {
const num = selRef.current.value * 1;
dispatch({ type: "INCREMENT", payload: num });
};
const incrementIfOdd = () => {
const num = selRef.current.value * 1;
if (state.count % 2 !== 0) {
dispatch({ type: "INCREMENT", payload: num });
}
};
const incrementAsync = () => {
const num = selRef.current.value * 1;
setTimeout(() => {
dispatch({ type: "INCREMENT", payload: num });
}, 1000);
};
return (
<div>
<p>click {state.count} times</p>
<select ref={selRef}>
<option value="1">1</option>
<option value="2">2</option>
<option value="3">3</option>
</select>
<button onClick={increment}>+</button>
<button onClick={decrement}>-</button>
<button onClick={incrementIfOdd}>increment if odd</button>
<button onClick={incrementAsync}>increment async</button>
</div>
);
}
export default App;useReducer 还接收第三个参数,第三个参数,是一个惰性初始化函数,简单理解就是可以做额外的初始化工作
// 惰性初始化函数
function init(initialState){
// 有些时候我们需要基于之前的初始化状态做一些操作,返回新的处理后的初始化值
// 重新返回新的初始化状态
return {
count : initialState.count * 10
}
}
// 接下来在使用 useReducer 的时候,这个函数就可以作为第三个参数传入
const [state, dispatch] = useReducer(counter, initialState, init);useState 的 mount 阶段
function mountState(initialState) {
// 拿到 hook 对象
const hook = mountWorkInProgressHook();
// 如果传入的值是函数,则执行函数获取到初始值
if (typeof initialState === "function") {
initialState = initialState();
}
// 将初始化保存到 hook 对象的 memoizedState 和 baseState 上面
hook.memoizedState = hook.baseState = initialState;
const queue = {
pending: null,
lanes: NoLanes,
dispatch: null,
lastRenderedReducer: basicStateReducer,
lastRenderedState: initialState,
};
hook.queue = queue;
// dispatch 就是用来修改状态的方法
const dispatch = (queue.dispatch = dispatchSetState.bind(
null,
currentlyRenderingFiber,
queue
));
return [hook.memoizedState, dispatch];
}useReducer 的mount阶段
function mountReducer(reducer, initialArg, init) {
// 创建 hook 对象
const hook = mountWorkInProgressHook();
let initialState;
// 如果有 init 初始化函数,就执行该函数
// 将执行的结果给 initialState
if (init !== undefined) {
initialState = init(initialArg);
} else {
initialState = initialArg;
}
// 将 initialState 初始值存储 hook 对象的 memoizedState 以及 baseState 上面
hook.memoizedState = hook.baseState = initialState;
// 创建 queue 对象
const queue = {
pending: null,
lanes: NoLanes,
dispatch: null,
lastRenderedReducer: reducer,
lastRenderedState: initialState,
};
hook.queue = queue;
const dispatch = (queue.dispatch = dispatchReducerAction.bind(
null,
currentlyRenderingFiber,
queue
));
// 向外部返回初始值和 dispatch 修改方法
return [hook.memoizedState, dispatch];
}总结一下,mountState 和 mountReducer 的大体流程是一样的,但是有一个区别,mountState 的 queue 里面的 lastRenderedReducer 对应的是 basicStateReducer,而 mountReducer 的 queue 里面的 lastRenderedReducer 对应的是开发者自己传入的 reducer,这里说明了一个问题,useState 的本质就是 useReducer 的一个简化版,只不过在 useState 内部,会有一个内置的 reducer
basicStateReducer 对应的代码如下:
function basicStateReducer(state, action) {
return typeof action === "function" ? action(state) : action;
}useState 的 update 阶段
function updateState(initialState) {
return updateReducer(basicStateReducer, initialState);
}useReducer 的 update 阶段
function updateReducer(reducer, initialArg, init){
// 获取对应的 hook
const hook = updateWorkInProgressHook();
// 拿到对应的更新队列
const queue = hook.queue;
queue.lastRenderedReducer = reducer;
// 省略根据 update 链表计算新的 state 的逻辑
// 这里有一套完整的关于 update 的计算流程
const dispatch = queue.dispatch;
return [hook.memoizedState, dispatch];
}题目:useState 和 useReducer 有什么样的区别?
参考答案:
useState 本质上就是一个简易版的 useReducer。
在 mount 阶段,两者之间的区别在于:
- useState 的 lastRenderedReducer 为 basicStateReducer
- useReducer 的 lastRenderedReducer 为传入的 reducer 参数
所以,useState 可以视为 reducer 参数为 basicStateReducer 的 useReducer
在 update 阶段,updateState 内部直接调用的就是 updateReducer,传入的 reducer 仍然是 basicStateReducer。
在 React 中,用于定义有副作用的因变量的 hook 有三个:
- useEffect:回调函数会在 commit 阶段完成后异步执行,所以它不会阻塞视图渲染
- useLayoutEffect:回调函数会在 commit 阶段的 Layout 子阶段同步执行,一般用于执行 DOM 相关的操作
- useInsertionEffect:回调函数会在 commit 阶段的 Mutation 子阶段同步执行,与 useLayoutEffect 的区别在于执行的时候无法访问对 DOM 的引用。这个 Hook 是专门为 CSS-in-JS 库插入全局的 style 元素而设计。
对于这三个 effect 相关的 hook,hook.memoizedState 共同使用同一套数据结构:
const effect = {
// 用于区分 effect 类型 Passive | Layout | Insertion
tag,
// effect 回调函数
create,
// effect 销毁函数
destory,
// 依赖项
deps,
// 与当前 FC 的其他 effect 形成环状链表
next: null
}tag 用来区分 effect 的类型:
- Passive: useEffect
- Layout:useLayoutEffect
- Insertion:useInsertionEffect
create 和 destory 分别指代 effect 的回调函数以及 effect 销毁函数:
useEffect(()=>{
// create
return ()=>{
// destory
}
})next 字段会与当前的函数组件的其他 effect 形成环状链表,连接的方式是一个单向环状链表。
function App(){
useEffect(()=>{
console.log(1);
});
const [num1, setNum1] = useState(0);
const [num2, setNum2] = useState(0);
useEffect(()=>{
console.log(2);
});
useEffect(()=>{
console.log(3);
});
return <div>Hello</div>
}结构如下图所示:
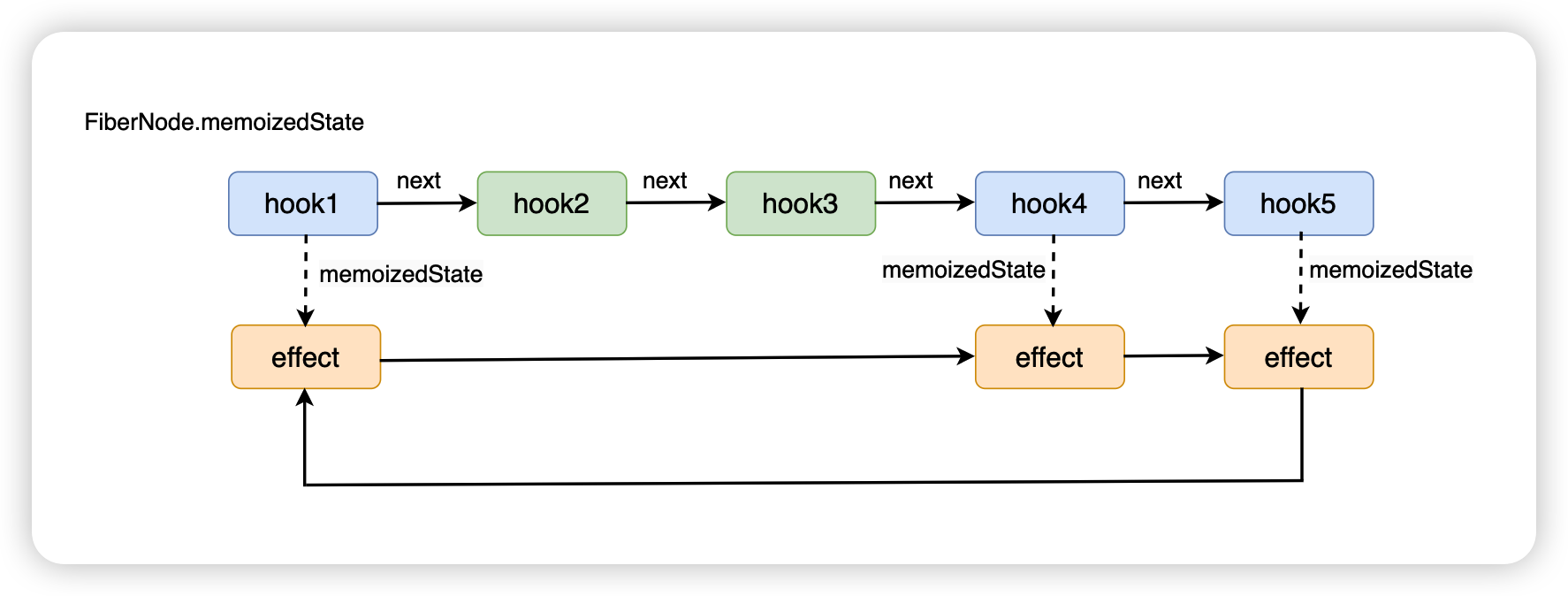
整个工作流程可以分为三个阶段:
- 声明阶段
- 调度阶段(useEffect 独有的)
- 执行阶段
声明阶段又可以分为 mount 和 update。
mount 的时候执行的是 mountEffectImpl,相关代码如下:
function mountEffectImpl(fiberFlags, hookFlags, create, deps) {
// 生成 hook 对象
const hook = mountWorkInProgressHook();
// 保存依赖的数组
const nextDeps = deps === undefined ? null : deps;
// 修改当前 fiber 的 flag
currentlyRenderingFiber.flags |= fiberFlags;
// 将 pushEffect 返回的环形链表存储到 hook 对象的 memoizedState 中
hook.memoizedState = pushEffect(
HookHasEffect | hookFlags,
create,
undefined,
nextDeps
);
}在上面的代码中,首先生成 hook 对象,拿到依赖,修改 fiber 的 flag,之后将当前的 effect 推入到环状列表,hook.memoizedState 指向该环状列表。
update 的时候执行的是 updateEffectImpl,相关代码如下:
function updateEffectImpl(fiberFlags, hookFlags, create, deps) {
// 先拿到之前的 hook 对象
const hook = updateWorkInProgressHook();
// 拿到依赖项
const nextDeps = deps === undefined ? null : deps;
// 初始化清除 effect 函数
let destroy = undefined;
if (currentHook !== null) {
// 从 hook 对象上面的 memoizedState 上面拿到副作用的环形链表
const prevEffect = currentHook.memoizedState;
// 拿到销毁函数,也就是说副作用函数执行后返回的函数
destroy = prevEffect.destroy;
// 如果新的依赖项不为空
if (nextDeps !== null) {
const prevDeps = prevEffect.deps;
// 两个依赖项进行比较
if (areHookInputsEqual(nextDeps, prevDeps)) {
// 如果依赖的值相同,即依赖没有变化,那么只会给这个 effect 打上一个 HookPassive 一个 tag
// 然后在组件渲染完以后会跳过这个 effect 的执行
hook.memoizedState = pushEffect(hookFlags, create, destroy, nextDeps);
return;
}
}
}
// 如果deps依赖项发生改变,赋予 effectTag ,在commit节点,就会再次执行我们的effect
currentlyRenderingFiber.flags |= fiberFlags;
// pushEffect 的作用是将当前 effect 添加到 FiberNode 的 updateQueue 中,然后返回这个当前 effcet
// 然后是把返回的当前 effect 保存到 Hook 节点的 memoizedState 属性中
hook.memoizedState = pushEffect(
HookHasEffect | hookFlags,
create,
destroy,
nextDeps
);
}在上面的代码中,首先从 updateWorkInProgressHook 方法中拿到 hook 对象,之后会从 hook.memoizedState 拿到所存储的 effect 对象,之后会利用 areHookInputsEqual 方法进行前后依赖项的比较,如果依赖相同,那就会在 effect 上面打一个 tag,在组件渲染完以后会跳过这个 effect 的执行。
如果依赖发生了变化,那么当前的 fiberNode 就会有一个 flags,回头在 commit 阶段统一执行该 effect,之后会推入新的 effect 到环状链表上面。
areHookInputsEqual 的作用是比较两个依赖项数组是否相同,采用的是浅比较,相关代码如下:
function areHookInputsEqual(nextDeps, prevDeps){
// 省略代码
for(let i=0; i<prevDeps.length && i< nextDeps.length; i++){
// 使用 Object.is 进行比较
if (is(nextDeps[i], prevDeps[i])) {
continue;
}
return false;
}
return true;
}pushEffect 方法的作用是生成一个 effect 对象,然后推入到当前的单向环状链表里面,相关代码如下:
function pushEffect(tag, create, destroy, deps) {
// 创建副作用对象
const effect = {
tag,
create, // callback
destroy,
deps, // 依赖
// Circular
next: null,
};
let componentUpdateQueue = currentlyRenderingFiber.updateQueue;
// 创建单向环状链表
if (componentUpdateQueue === null) {
// 进入此 if,说明是第一个 effect
// createFunctionComponentUpdateQueue 调用后会返回一个对象
// { lastEffect, events, stores, memoCache}
componentUpdateQueue = createFunctionComponentUpdateQueue();
// fiber 的 updateQueue 上面保存了该对象(componentUpdateQueue)
currentlyRenderingFiber.updateQueue = componentUpdateQueue;
// 该对象(componentUpdateQueue)上面 lastEffect 存储了副作用对象
componentUpdateQueue.lastEffect = effect.next = effect;
} else {
// 存在多个 effect
// 拿到之前的副作用
const lastEffect = componentUpdateQueue.lastEffect;
if (lastEffect === null) {
// 如果没有,那就和上面的 if 处理一样
componentUpdateQueue.lastEffect = effect.next = effect;
} else {
// 如果之前有副作用,先存储到 firstEffect
const firstEffect = lastEffect.next;
// lastEffect 指向新的副作用对象
lastEffect.next = effect;
// 新的副作用对象的 next 指向之前的副作用对象
// 最终形成一个环形链表
effect.next = firstEffect;
componentUpdateQueue.lastEffect = effect;
}
}
return effect;
}update 的时候,即使 effect deps 没有变化,也会创建对应的 effect。因为这样才能后保证 effect 数量以及顺序是稳定的:
// update 时 deps 没有变化情况
hook.memoizedState = pushEffect(hookFlags, create, destroy, nextDeps);
// update 时 deps 有变化的情况
hook.memoizedState = pushEffect(
HookHasEffect | hookFlags,
create,
destroy,
nextDeps
);调度阶段是 useEffect 独有的,因为 useEffect 的回调函数会在 commit 阶段完成后异步执行,因此需要调度阶段。
在 commit 阶段的三个子阶段开始之前,会执行如下的代码:
if (
(finishedWork.subtreeFlags & PassiveMask) !== NoFlags ||
(finishedWork.flags & PassiveMask) !== NoFlags
) {
if (!rootDoesHavePassiveEffects) {
rootDoesHavePassiveEffects = true;
pendingPassiveEffectsRemainingLanes = remainingLanes;
// ...
// scheduleCallback 来自于 Scheduler,用于以某一优先级调度回调函数
scheduleCallback(NormalSchedulerPriority, () => {
// 执行 effect 回调函数的具体方法
flushPassiveEffects();
return null;
});
}
}flushPassiveEffects 会去执行对应的 effects:
function flushPassiveEffects(){
if (rootWithPendingPassiveEffects !== null) {
// 执行 effects
}
return false;
}另外,由于调度阶段的存在,为了保证下一次的 commit 阶段执行前,上一次 commit 所调度的 useEffect 都已经执行过了,因此会在 commit 阶段的入口处,也会执行 flushPassiveEffects,而且是一个循环执行:
function commitRootImpl(root, renderPriorityLevel){
do {
flushPassiveEffects();
} while (rootWithPendingPassiveEffects !== null);
}之所以使用 do...while 循环,就是为了保证上一轮调度的 effect 都执行过了。
这三个 effect 相关的 hook 执行阶段,有两个相关的方法
- commitHookEffectListUnmount :用于遍历 effect 链表依次执行 effect.destory 方法
function commitHookEffectListUnmount(
flags: HookFlags,
finishedWork: Fiber,
nearestMountedAncestor: Fiber | null,
) {
const updateQueue: FunctionComponentUpdateQueue | null = (finishedWork.updateQueue: any);
const lastEffect = updateQueue !== null ? updateQueue.lastEffect : null;
if (lastEffect !== null) {
const firstEffect = lastEffect.next;
let effect = firstEffect;
do {
if ((effect.tag & flags) === flags) {
// Unmount
// 从 effect 对象上面拿到 destory 函数
const destroy = effect.destroy;
effect.destroy = undefined;
// ...
}
effect = effect.next;
} while (effect !== firstEffect);
}
}- commitHookEffectListMount:遍历 effect 链表依次执行 create 方法,在声明阶段中,update 时会根据 deps 是否变化打上不同的 tag,之后在执行阶段就会根据是否有 tag 来决定是否要执行该 effect
// 类型为 useInsertionEffect 并且存在 HasEffect tag 的 effect 会执行回调
commitHookEffectListMount(Insertion | HasEffect, fiber);
// 类型为 useEffect 并且存在 HasEffect tag 的 effect 会执行回调
commitHookEffectListMount(Passive | HasEffect, fiber);
// 类型为 useLayoutEffect 并且存在 HasEffect tag 的 effect 会执行回调
commitHookEffectListMount(Layout | HasEffect, fiber);由于 commitHookEffectListUnmount 方法的执行时机会先于 commitHookEffectListMount 方法执行,因此每次都是先执行 effect.destory 后才会执行 effect.create。
useCallback 用法如下:
const memoizedCallback = useCallback(
() => {
doSomething(a, b);
},
[a, b],
);使用 useCallback 最终会得到一个缓存的函数,该缓存函数会在 a 或者 b 依赖项发生变化时再更新。
mount 阶段
在 mount 阶段执行的就是 mountCallback,相关代码如下:
function mountCallback(callback, deps) {
// 首先还是创建一个 hook 对象
const hook = mountWorkInProgressHook();
// 依赖项
const nextDeps = deps === undefined ? null : deps;
// 把要缓存的函数和依赖数组存储到 hook 对象上
hook.memoizedState = [callback, nextDeps];
// 向外部返回缓存函数
return callback;
}在上面的代码中,首先会调用 mountWorkInProgressHook 得到一个 hook 对象,在 hook 对象的 memoizedState 上面保存 callback 以及依赖项目,最后向外部返回 callback
update阶段
update 调用的是 updateCallback,相关代码如下:
function updateCallback(callback, deps) {
// 拿到之前的 hook 对象
const hook = updateWorkInProgressHook();
// 新的依赖项
const nextDeps = deps === undefined ? null : deps;
// 之前的值,也就是 [callback, nextDeps]
const prevState = hook.memoizedState;
if (prevState !== null) {
if (nextDeps !== null) {
const prevDeps = prevState[1]; // 拿到之前的依赖项
// 对比依赖项是否相同
if (areHookInputsEqual(nextDeps, prevDeps)) {
// 相同返回 callback
return prevState[0];
}
}
}
// 否则重新缓存
hook.memoizedState = [callback, nextDeps];
return callback;
}在组件更新阶段,首先拿到之前的 hook 对象,从之前的 hook 对象的 memoizedState 上面拿到之前的依赖项,和新传入的依赖项做一个对比,如果相同,则返回之前缓存的 callback,否则就重新缓存,返回新的 callback
用法如下:
const memoizedValue = useMemo(() => computeExpensiveValue(a, b), [a, b]);使用 useMemo 缓存的是一个值,这个值会在 a 或者 b 发生变化的时候重新进行计算并缓存。
mount 阶段
mount 阶段调用的是 mountMemo,代码如下:
function mountMemo(nextCreate, deps) {
// 创建 hook 对象
const hook = mountWorkInProgressHook();
// 存储依赖项
const nextDeps = deps === undefined ? null : deps;
// ...
// 执行传入的函数,拿到返回值
const nextValue = nextCreate();
// 将函数返回值和依赖存储到 memoizedState 上面
hook.memoizedState = [nextValue, nextDeps];
// 返回函数计算得到的值
return nextValue;
}在 mount 阶段首先会调用 mountWorkInProgressHook 方法得到一个 hook 对象,之后执行传入的函数(第一个参数)得到计算值,将计算值和依赖项目存储到 hook 对象的 memoizedState 上面,最后向外部返回计算得到的值。
update 阶段
update 阶段调用的是 updateMemo,相关代码如下:
function updateMemo(nextCreate, deps) {
// 获取之前的 hook 对象
const hook = updateWorkInProgressHook();
// 新的依赖项
const nextDeps = deps === undefined ? null : deps;
// 获取之前的 memoizedState,也就是 [nextValue, nextDeps]
const prevState = hook.memoizedState;
if (prevState !== null) {
// Assume these are defined. If they're not, areHookInputsEqual will warn.
if (nextDeps !== null) {
// 拿到之前的依赖项
const prevDeps = prevState[1];
// 比较和现在的依赖项是否相同
if (areHookInputsEqual(nextDeps, prevDeps)) {
// 如果相同,则返回之前的值
return prevState[0];
}
}
}
// ...
// 否则重新计算
const nextValue = nextCreate();
hook.memoizedState = [nextValue, nextDeps];
return nextValue;
}首先,仍然是从 updateWorkInProgressHook 上面拿到之前的 hook 对象,从而获取到之前的依赖项目,然后和新传入的依赖项目就行一个对比,如果依赖项目没有变化,则返回之前的计算值,否则就执行传入的函数重新进行计算,最后向外部返回新的计算值。
题目:useCallback 和 useMemo 的区别是什么?
参考答案:
在 useCallback 内部,会将函数和依赖项一起缓存到 hook 对象的 memoizedState 属性上,在组件更新阶段,首先会拿到之前的 hook 对象,从之前的 hook 对象的 memoizedState 属性上获取到之前的依赖项目,对比依赖项目是否相同,如果相同返回之前的 callback,否则就重新缓存,然后返回新的 callback。
在 useMemo 内部,会将传入的函数执行并得到计算值,将计算值和依赖项目存储到 hook 对象的 memoizedState 上面,最后向外部返回计算得到的值。更新的时候首先是从 updateWorkInProgressHook 上拿到之前的 hook 对象,从而获取到之前的依赖值,和新传入的依赖进行一个对比,如果相同,就返回上一次的计算值,否则就重新调用传入的函数得到新的计算值并缓存,最后向外部返回新的计算值。
ref 是英语 reference(引用)的缩写,在 React 中,开发者可以通过 ref 保存一个对 DOM 的引用。事实上,任何需要被引用的数据,都可以保存在 ref 上。在 React 中,出现过 3 种 ref 引用模式:
- String 类型(已不推荐使用)
- 函数类型
- { current : T }
目前关于创建 ref,类组件推荐使用 createRef 方法,函数组件推荐使用 useRef
用法如下:
const refContainer = useRef(initialValue);mount 阶段
mount 阶段调用的是 mountRef,对应的代码如下:
function mountRef(initialValue) {
// 创建 hook 对象
const hook = mountWorkInProgressHook();
const ref = { current: initialValue };
// hook 对象的 memoizedState 值为 { current: initialValue }
hook.memoizedState = ref;
return ref;
}在 mount 阶段,首先调用 mountWorkInProgressHook 方法得到一个 hook 对象,该 hook 对象的 memoizedState 上面会缓存一个键为 current 的对象 { current: initialValue },之后向外部返回该对象。
update 阶段
update 阶段调用的是 updateRef,相关代码如下:
function updateRef(initialValue) {
// 拿到当前的 hook 对象
const hook = updateWorkInProgressHook();
return hook.memoizedState;
}除了 useRef 以外,createRef 也会创建相同数据结构的 ref:
function createRef(){
const refObject = {
current: null
}
return refObject;
}ref 创建之后,会挂在 HostComponent 或者 ClassComponent 上面,形成 ref props,例如:
// HostComponent
<div ref={domRef}></div>
// ClassComponent
<App ref={comRef}/>整个 ref 的工作流程分为两个阶段:
- render 阶段:标记 ref flag
- commit 阶段:根据所标记的 ref flag,执行 ref 相关的操作

上图中,markRef 表示的就是标记 ref,相关代码如下:
function markRef(current, workInProgress){
const ref = workInProgress.ref;
if((current === null && ref !== null) || (current !== null && current.ref !== ref)){
// 标记 Reg tag
workInProgress.flags != Ref;
}
}有两种情况会标记 ref:
- mount 阶段并且 ref props 不为空
- update 阶段并且 ref props 发生了变化
标记完 ref 之后,来到了 commit 阶段,会在 mutation 子阶段执行 ref 的删除操作,删除旧的 ref:
function commitMutationOnEffectOnFiber(finishedWork, root){
// ...
if(flags & Ref){
const current = finishedWork.alternate;
if(current !== null){
// 移除旧的 ref
commitDetachRef(current);
}
}
// ...
}上面的代码中,commitDetachRef 方法要做的事情就是移除旧的 ref,相关代码如下:
function commitDetachRef(current){
const currentRef = current.ref;
if(currentRef !== null){
if(typeof currentRef === 'function'){
// 函数类型 ref,执行并传入 null 作为参数
currentRef(null);
} else {
// { current: T } 类型的 ref,重置 current 指向
currentRef.current = null;
}
}
}删除完成后,会在 Layout 子阶段重新赋值新的 ref,相关代码如下:
function commitLayoutEffectOnFiber(finishedRoot, current, finishedWork, committedLanes){
// 省略代码
if(finishedWork.flags & Ref){
commitAttachRef(finishedWork);
}
}对应的方法 commitAttachRef 就是用来重新赋值新 ref 的,相关代码如下:
function commitAttachRef(finishedWork){
const ref = finishedWork.ref;
if(ref !== null){
const instance = finishedWork.stateNode;
let instanceToUse;
switch(finishedWork.tag){
case HostComponent:
// HostComponent 需要获取对应的 DOM 元素
instanceToUse = getPublicInstance(instance);
break;
default:
// ClassComponent 使用 FiberNode.stateNode 保存实例
instanceToUse = instance;
}
if(typeof ref === 'function'){
// 函数类型,执行函数并将实例传入
let retVal;
retVal = ref(instanceToUse);
} else {
// { current: T } 类型则更新 current 指向
ref.current = instanceToUse;
}
}
}当我们使用 ref 保存对 DOM 的引用时,那么就有可能会造成 ref 的失控。
所谓 ref 的失控,开发者通过 ref 操作了 DOM,但是这一行为本来应该是由 React 接管的,两者产生了冲突,这种冲突我们就称之为 ref 的失控。
考虑下面这一段代码:
function App(){
const inputRef = useRef(null);
useEffect(()=>{
// 操作1
inputRef.current.focus();
// 操作2
inputRef.current.getBoundingClientRect();
// 操作3
inputRef.current.style.width = '500px';
}, []);
return <input ref={inputRef}/>;
}在上面的三个操作中,第三个操作是不推荐的。
React 作为一个视图层框架,接管了大部分和视图相关的操作,这样开发者可以专注于业务上面的开发逻辑。
上面的三个操作中,前面两个并没有被 React 接管,所以当产生这样的操作时,可以百分百确定是来自于开发者的操作。但是在操作三中,并不能确定该操作究竟是 React 的行为还是开发者的行为,甚至两者会产生冲突。
例如我们再聚一个例子:
function App(){
const [isShow, setShow] = useState(true);
const ref = useRef(null);
return (
<div>
<button onClick={() => setShow(!isShow)}>React操作DOM</button>
<button onClick={() => ref.current.remove()}>开发者DOM</button>
{isShow && <p ref={ref}>Hello</p>}
</div>
);
}上面的代码就是一个典型的 ref 失控的案例。第一个按钮通过 isShow 来控制 p 是否显示,这是 React 的行为,第二个按钮通过 ref 直接拿到了 p 的 DOM 对象,然后进行显隐操作,两者会产生冲突,上面的两个按钮,先点击任意一个,然后再点击另外一个就会报错。
ref 失控的本质:由于开发者通过 ref 操作了 DOM,而这一行为本来应该是由 React 来进行接管的,两者之间发生了冲突而导致的。
因此我们可以从下面两个方面来进行防治:
- 防:控制 ref 失控的影响范围,使 ref 的失控更加容易被定位
- 治:从 ref 引用的数据结构入手,尽力避免可能引起的失控操作
防
在上一章我们介绍过高阶组件,在高阶组件内部是无法将 ref 直接指向 DOM 的,我们需要进行 ref 的转发。可以通过 forwardRef API 进行一个 ref 的转发,将 ref 转发的这个操作,实际上就将 ref 失控的范围控制在了单个组件内,不会出现跨越组件的 ref 失控。
因为是手动的进行 ref 的转发,所以发生 ref 失控的时候,能够更加容易的进行错误的定位
治
之前我们介绍过 useImperativeHandle 这个 Hook,它可以在使用 ref 时向父组件传递自定义的引用值:
const MyInput = forwardRef((props, ref) => {
const realInputRef = useRef(null);
useImperativeHandle(ref, () => ({
focus(){
realInputRef.current.focus();
}
}));
return <input {...props} ref={realInputRef} />
});在上面的代码中,我们通过 useImperativeHandle 来定制 ref 所引用的内容,那么在外部开发者通过 ref 只能拿到:
{
focus(){
realInputRef.current.focus();
}
}题目:useRef 是干什么的?ref 的工作流程是怎样的?什么叫做 ref 的失控?
参考答案:
useRef 的主要作用就是用来创建 ref 保存对 DOM 元素的引用。在 React 发展过程中,出现过三种 ref 相关的引用模式:
- String 类型(已不推荐使用)
- 函数类型
- { current : T }
目前最为推荐的是在类组件中使用 createRef,函数组件中使用 useRef 来创建 Ref。
当开发者调用 useRef 来创建 ref 时,在 mount 阶段,会创建一个 hook 对象,该 hook 对象的 memoizedState 存储的是 { current: initialValue } 对象,之后向外部返回了这个对象。在 update 阶段就是从 hook 对象的 memoizedState 拿到 { current: initialValue } 对象。
ref 内部的工作流程整体上可以分为两个阶段:
- render 阶段:标记 Ref flag,对应的内部函数为 markRef
- commit 阶段:根据 Ref flag,执行 ref 相关的操作,对应的相关函数有 commitDetachRef、commitAttachRef
所谓 ref 的失控,本质是由于开发者通过 ref 操作了 DOM,而这一行为本身是应该由 React 来进行接管的,所以两者之间发生了冲突导致的。
ref 失控的防治主要体现在两个方面:
- 防:控制 ref 失控影像的范围,使 ref 失控造成的影响更容易被定位,例如使用 forwardRef
- 治:从 ref 引用的数据结构入手,尽力避免可能引起失控的操作,例如使用 useImperativeHandle
之前在学习事件循环的时候,大家看得更多的是下面这张图:

首先会执行同步代码,同步代码执行的时候,如果遇到异步代码,就会放到 Webapis 里面进行执行,当 webapis 执行完毕之后,会将结果放入到 task queue(任务队列),同步代码执行完毕后,就会从任务队列中会获取一个一个的任务进行执行。
如果将事件循环和浏览器渲染结合到一起,大致就是下面这张图:

从上面的胴体,我们可以看出,每一次事件循环,会从任务队列里面获取一个任务来执行。
之前有讲过,大多数设备的刷新率是 60hz,也就是1秒钟要绘制60次,这意味着浏览器每隔 16.66ms 就需要重新渲染一次。
总结一下:事件循环的机制就是每一次循环,会从任务队列中取一个任务来执行,如果还没有达到浏览器需要重新渲染的时间(16.66ms),那么就继续循环一次,从任务队列里面再取一个任务来执行,依此类推,直到浏览器需要重新渲染,这个时候就会执行重选渲染的任务,执行完毕后,回到之前的流程。
requestAnimationFrame Api 是在每一次重新渲染之前执行,这个 API 的出现,就是专门拿来做动画的。以前我们做动画,用的更多的是 setInterval 或者 setTimeout,但是这些 API 本意不是拿来做动画的。使用 requestAnimationFrame Api 拿到做动画,最大的优点就是频率是和浏览器重新渲染的频率一致。

requestAnimationFrame 就不会存在这个问题,因为它是在渲染之前,保证了和浏览器渲染是同频

微任务:如果微任务队列里面存在任务,那么事件循环会在循环一次的时候,将整个微任务队列清空。
每一次事件循环时这几种任务的区别,如下图:

MessageChannel 接口本身是用来做消息通信的,允许我们创建一个消息通道,通过它的两个 MessagePort 来进行信息的发送和接收。
基本使用如下:
<div>
<input type="text" id="content" placeholder="请输入消息">
</div>
<div>
<button id="btn1">给 port1 发消息</button>
<button id="btn2">给 port2 发消息</button>
</div>const channel = new MessageChannel();
// 两个信息端口,这两个信息端口可以进行信息的通信
const port1 = channel.port1;
const port2 = channel.port2;
btn1.onclick = function(){
// 给 port1 发消息
// 那么这个信息就应该由 port2 来进行发送
port2.postMessage(content.value);
}
// port1 需要监听发送给自己的消息
port1.onmessage = function(event){
console.log(`port1 收到了来自 port2 的消息:${event.data}`);
}
btn2.onclick = function(){
// 给 port2 发消息
// 那么这个信息就应该由 port1 来进行发送
port1.postMessage(content.value);
}
// port2 需要监听发送给自己的消息
port2.onmessage = function(event){
console.log(`port2 收到了来自 port1 的消息:${event.data}`);
}那么这个和 scheduler 有什么关系呢?
之前,我们有说过 scheduler 是用来调度任务,调度任务需要满足两个条件:
- JS 暂停,将主线程还给浏览器,让浏览器能够有序的重新渲染页面
- 暂停了的 JS(说明还没有执行完),需要再下一次接着来执行
那么这里自然而然就会想到事件循环,我们可以将没有执行完的 JS 放入到任务队列,下一次事件循环的时候再取出来执行。
那么,如何将没有执行完的任务放入到任务队列中呢?
那么这里就需要产生一个任务(宏任务),这里就可以使用 MessageChannel,因为 MessageChannel 能够产生宏任务。
为什么不选择 setTimeout
以前要创建一个宏任务,可以采用 setTimeout(fn, 0) 这种方式,但是 react 团队没有采用这种方式。
这是因为 setTimeout 在嵌套层级超过 5 层,timeout(延时)如果小于 4ms,那么则会设置为 4ms。
这个你可以参阅 HTML 规范:https://html.spec.whatwg.org/multipage/timers-and-user-prompts.html#dom-settimeout
If nesting level is greater than 5, and timeout is less than 4, then set timeout to 4.
可以写一个例子来进行验证:
let count = 0; // 计数器
let startTime = new Date(); // 获取当前的时间戳
console.log("start time:", 0, 0);
function fn(){
setTimeout(function(){
console.log("exec time:", ++count, new Date() - startTime);
if(count === 50){
return;
}
fn();
},0)
}
fn();执行结果部分截图如下:

正因为这个原因,所以 react 团队没有选择使用 setTimeout 来产生任务,因为 4ms 的时间的浪费还是不可忽视的。
为什么没有选择 requestAnimationFrame
这个也不合适,因为这个只能在重新渲染之前,才能够执行一次,而如果我们包装成一个任务,放入到任务队列中,那么只要没到重新渲染的时间,就可以一直从任务队列里面获取任务来执行。
而且 requestAnimationFrame 还会有一定的兼容性问题,safari 和 edge 浏览器是将 requestAnimationFrame 放到渲染之后执行的,chrome 和 firefox 是将 requestAnimationFrame 放到渲染之前执行的,所以这里存在不同的浏览器有不同的执行顺序的问题。
根据标准,应该是放在渲染之前。
为什么没有选择包装成一个微任务?
这是因为和微任务的执行机制有关系,微任务队列会在清空整个队列之后才会结束。那么微任务会在页面更新前一直执行,直到队列被清空,达不到将主线程还给浏览器的目的。
Scheduler 的核心源码位于 packages/scheduler/src/forks/Scheduler.js
该函数的主要目的就是用调度任务,该方法的分析如下:
let getCurrentTime = () => performance.now();
// 有两个队列分别存储普通任务和延时任务
// 里面采用了一种叫做小顶堆的算法,保证每次从队列里面取出来的都是优先级最高(时间即将过期)
var taskQueue = []; // 存放普通任务
var timerQueue = []; // 存放延时任务
var maxSigned31BitInt = 1073741823;
// Timeout 对应的值
var IMMEDIATE_PRIORITY_TIMEOUT = -1;
var USER_BLOCKING_PRIORITY_TIMEOUT = 250;
var NORMAL_PRIORITY_TIMEOUT = 5000;
var LOW_PRIORITY_TIMEOUT = 10000;
var IDLE_PRIORITY_TIMEOUT = maxSigned31BitInt;
/**
*
* @param {*} priorityLevel 优先级等级
* @param {*} callback 具体要做的任务
* @param {*} options { delay: number } 这是一个对象,该对象有 delay 属性,表示要延迟的时间
* @returns
*/
function unstable_scheduleCallback(priorityLevel, callback, options) {
// 获取当前的时间
var currentTime = getCurrentTime();
var startTime;
// 整个这个 if.. else 就是在设置起始时间,如果有延时,起始时间需要添加上这个延时
if (typeof options === "object" && options !== null) {
var delay = options.delay;
// 如果设置了延时时间,那么 startTime 就为当前时间 + 延时时间
if (typeof delay === "number" && delay > 0) {
startTime = currentTime + delay;
} else {
startTime = currentTime;
}
} else {
startTime = currentTime;
}
var timeout;
// 根据传入的优先级等级来设置不同的 timeout
switch (priorityLevel) {
case ImmediatePriority:
timeout = IMMEDIATE_PRIORITY_TIMEOUT;
break;
case UserBlockingPriority:
timeout = USER_BLOCKING_PRIORITY_TIMEOUT;
break;
case IdlePriority:
timeout = IDLE_PRIORITY_TIMEOUT;
break;
case LowPriority:
timeout = LOW_PRIORITY_TIMEOUT;
break;
case NormalPriority:
default:
timeout = NORMAL_PRIORITY_TIMEOUT;
break;
}
// 接下来就计算出过期时间
// 计算出来的时间有些比当前时间要早,绝大部分比当前的时间要晚一些
var expirationTime = startTime + timeout;
// 创建一个新的任务
var newTask = {
id: taskIdCounter++, // 任务 id
callback, // 该任务具体要做的事情
priorityLevel, // 任务的优先级别
startTime, // 任务开始时间
expirationTime, // 任务的过期时间
sortIndex: -1, // 用于后面在小顶堆(这是一种算法,可以始终从任务队列中拿出最优先的任务)进行排序的索引
};
if (enableProfiling) {
newTask.isQueued = false;
}
if (startTime > currentTime) {
// This is a delayed task.
// 说明这是一个延时任务
newTask.sortIndex = startTime;
// 将该任务推入到 timerQueue 的任务队列中
push(timerQueue, newTask);
if (peek(taskQueue) === null && newTask === peek(timerQueue)) {
// 进入此 if,说明 taskQueue 里面的任务已经执行完毕了
// 并且从 timerQueue 里面取出一个最新的任务又是当前任务
// All tasks are delayed, and this is the task with the earliest delay.
// 下面的 if.. else 就是一个开关
if (isHostTimeoutScheduled) {
// Cancel an existing timeout.
cancelHostTimeout();
} else {
isHostTimeoutScheduled = true;
}
// Schedule a timeout.
// 如果是延时任务,调用 requestHostTimeout 进行任务的调度
requestHostTimeout(handleTimeout, startTime - currentTime);
}
} else {
// 说明不是延时任务
newTask.sortIndex = expirationTime; // 设置了 sortIndex 后,可以在任务队列里面进行一个排序
// 推入到 taskQueue 任务队列
push(taskQueue, newTask);
if (enableProfiling) {
markTaskStart(newTask, currentTime);
newTask.isQueued = true;
}
// Schedule a host callback, if needed. If we're already performing work,
// wait until the next time we yield.
// 最终调用 requestHostCallback 进行任务的调度
if (!isHostCallbackScheduled && !isPerformingWork) {
isHostCallbackScheduled = true;
requestHostCallback(flushWork);
}
}
// 向外部返回任务
return newTask;
}该方法主要注意以下几个关键点:
- 关于任务队列有两个,一个 taskQueue,另一个是 timerQueue,taskQueue 存放普通任务,timerQueue 存放延时任务,任务队列内部用到了小顶堆的算法,保证始终放进去(push)的任务能够进行正常的排序,回头通过 peek 取出任务时,始终取出的是时间优先级最高的那个任务
- 根据传入的不同的 priorityLevel,会进行不同的 timeout 的设置,任务的 timeout 时间也就不一样了,有的比当前时间还要小,这个代表立即需要执行的,绝大部分的时间比当前时间大。

- 不同的任务,最终调用的函数不一样
- 普通任务:requestHostCallback(flushWork)
- 延时任务:requestHostTimeout(handleTimeout, startTime - currentTime);
/**
*
* @param {*} callback 是在调用的时候传入的 flushWork
* requestHostCallback 这个函数没有做什么事情,主要就是调用 schedulePerformWorkUntilDeadline
*/
function requestHostCallback(callback) {
scheduledHostCallback = callback;
// scheduledHostCallback ---> flushWork
if (!isMessageLoopRunning) {
isMessageLoopRunning = true;
schedulePerformWorkUntilDeadline(); // 实例化 MessageChannel 进行后面的调度
}
}
let schedulePerformWorkUntilDeadline; // undefined
if (typeof localSetImmediate === 'function') {
// Node.js and old IE.
// https://github.com/facebook/react/issues/20756
schedulePerformWorkUntilDeadline = () => {
localSetImmediate(performWorkUntilDeadline);
};
} else if (typeof MessageChannel !== 'undefined') {
// 大多数情况下,使用的是 MessageChannel
const channel = new MessageChannel();
const port = channel.port2;
channel.port1.onmessage = performWorkUntilDeadline;
schedulePerformWorkUntilDeadline = () => {
port.postMessage(null);
};
} else {
// setTimeout 进行兜底
schedulePerformWorkUntilDeadline = () => {
localSetTimeout(performWorkUntilDeadline, 0);
};
}- requestHostCallback 主要就是调用了 schedulePerformWorkUntilDeadline
- schedulePerformWorkUntilDeadline 一开始是 undefiend,根据不同的环境选择不同的生成宏任务的方式
let startTime = -1;
const performWorkUntilDeadline = () => {
// scheduledHostCallback ---> flushWork
if (scheduledHostCallback !== null) {
// 获取当前的时间
const currentTime = getCurrentTime();
// Keep track of the start time so we can measure how long the main thread
// has been blocked.
// 这里的 startTime 并非 unstable_scheduleCallback 方法里面的 startTime
// 而是一个全局变量,默认值为 -1
// 用来测量任务的执行时间,从而能够知道主线程被阻塞了多久
startTime = currentTime;
const hasTimeRemaining = true; // 默认还有剩余时间
// If a scheduler task throws, exit the current browser task so the
// error can be observed.
//
// Intentionally not using a try-catch, since that makes some debugging
// techniques harder. Instead, if `scheduledHostCallback` errors, then
// `hasMoreWork` will remain true, and we'll continue the work loop.
let hasMoreWork = true; // 默认还有需要做的任务
try {
// scheduledHostCallback ---> flushWork(true, 开始时间): boolean
// 如果是 true,代表工作没做完
// false 代表没有任务了
hasMoreWork = scheduledHostCallback(hasTimeRemaining, currentTime);
} finally {
if (hasMoreWork) {
// If there's more work, schedule the next message event at the end
// of the preceding one.
// 那么就使用 messageChannel 进行一个 message 事件的调度,就将任务放入到任务队列里面
schedulePerformWorkUntilDeadline();
} else {
// 说明任务做完了
isMessageLoopRunning = false;
scheduledHostCallback = null; // scheduledHostCallback 之前为 flushWork,设置为 null
}
}
} else {
isMessageLoopRunning = false;
}
// Yielding to the browser will give it a chance to paint, so we can
// reset this.
needsPaint = false;
};- 该方法实际上主要就是在调用 scheduledHostCallback(flushWork),调用之后,返回一个布尔值,根据这个布尔值来判断是否还有剩余的任务,如果还有,就是用 messageChannel 进行一个宏任务的包装,放入到任务队列里面
/**
*
* @param {*} hasTimeRemaining 是否有剩余的时间,一开始是 true
* @param {*} initialTime 做这一个任务时开始执行的时间
* @returns
*/
function flushWork(hasTimeRemaining, initialTime) {
// ...
try {
if (enableProfiling) {
try {
// 核心实际上是这一句,调用 workLoop
return workLoop(hasTimeRemaining, initialTime);
} catch (error) {
// ...
}
} else {
// 核心实际上是这一句,调用 workLoop
return workLoop(hasTimeRemaining, initialTime);
}
} finally {
// ...
}
}
/**
*
* @param {*} hasTimeRemaining 是否有剩余的时间,一开始是 true
* @param {*} initialTime 做这一个任务时开始执行的时间
* @returns
*/
function workLoop(hasTimeRemaining, initialTime) {
let currentTime = initialTime;
// 该方法实际上是用来遍历 timerQueue,判断是否有已经到期了的任务
// 如果有,将这个任务放入到 taskQueue
advanceTimers(currentTime);
// 从 taskQueue 里面取一个任务出来
currentTask = peek(taskQueue);
while (
currentTask !== null &&
!(enableSchedulerDebugging && isSchedulerPaused)
) {
if (
currentTask.expirationTime > currentTime &&
(!hasTimeRemaining || shouldYieldToHost())
) {
// This currentTask hasn't expired, and we've reached the deadline.
// currentTask.expirationTime > currentTime 表示任务还没有过期
// hasTimeRemaining 代表是否有剩余时间
// shouldYieldToHost 任务是否应该暂停,归还主线程
// 那么我们就跳出 while
break;
}
// 没有进入到上面的 if,说明这个任务到过期时间,并且有剩余时间来执行,没有到达需要浏览器渲染的时候
// 那我们就执行该任务即可
const callback = currentTask.callback; // 拿到这个任务
if (typeof callback === "function") {
// 说明当前的任务是一个函数,我们执行该任务
currentTask.callback = null;
currentPriorityLevel = currentTask.priorityLevel;
const didUserCallbackTimeout = currentTask.expirationTime <= currentTime;
if (enableProfiling) {
markTaskRun(currentTask, currentTime);
}
// 任务的执行实际上就是在这一句
const continuationCallback = callback(didUserCallbackTimeout);
currentTime = getCurrentTime();
if (typeof continuationCallback === "function") {
// If a continuation is returned, immediately yield to the main thread
// regardless of how much time is left in the current time slice.
// $FlowFixMe[incompatible-use] found when upgrading Flow
currentTask.callback = continuationCallback;
if (enableProfiling) {
// $FlowFixMe[incompatible-call] found when upgrading Flow
markTaskYield(currentTask, currentTime);
}
advanceTimers(currentTime);
return true;
} else {
if (enableProfiling) {
// $FlowFixMe[incompatible-call] found when upgrading Flow
markTaskCompleted(currentTask, currentTime);
// $FlowFixMe[incompatible-use] found when upgrading Flow
currentTask.isQueued = false;
}
if (currentTask === peek(taskQueue)) {
pop(taskQueue);
}
advanceTimers(currentTime);
}
} else {
// 直接弹出
pop(taskQueue);
}
// 再从 taskQueue 里面拿一个任务出来
currentTask = peek(taskQueue);
}
// Return whether there's additional work
if (currentTask !== null) {
// 如果不为空,代表还有更多的任务,那么回头外部的 hasMoreWork 拿到的就也是 true
return true;
} else {
// taskQueue 这个队列是空了,那么我们就从 timerQueue 里面去看延时任务
const firstTimer = peek(timerQueue);
if (firstTimer !== null) {
requestHostTimeout(handleTimeout, firstTimer.startTime - currentTime);
}
// 没有进入上面的 if,说明 timerQueue 里面的任务也完了,返回 false,回头外部的 hasMoreWork 拿到的就也是 false
return false;
}
}- flushWork 主要就是在调用 workLoop
- workLoop 首先有一个 while 循环,该 while 循环保证了能够从任务队列中不停的取任务出来
while (
currentTask !== null &&
!(enableSchedulerDebugging && isSchedulerPaused)
){
// ...
}- 当然,不是说一直从任务队列里面取任务出来执行就完事儿,每次取出一个任务后,我们还需要一系列的判断
if (
currentTask.expirationTime > currentTime &&
(!hasTimeRemaining || shouldYieldToHost())
) {
break;
}- currentTask.expirationTime > currentTime 表示任务还没有过期
- hasTimeRemaining 代表是否有剩余时间
- shouldYieldToHost 任务是否应该暂停,归还主线程
- 如果进入 if,说明因为某些原因不能再执行任务,需要立即归还主线程,那么我们就跳出 while
function shouldYieldToHost() {
// getCurrentTime 获取当前时间
// startTime 是我们任务开始时的时间,一开始是 -1,之后任务开始时,将任务开始时的时间复值给了它
const timeElapsed = getCurrentTime() - startTime;
// frameInterval 默认设置的是 5ms
if (timeElapsed < frameInterval) {
// 主线程只被阻塞了一点点时间,远远没达到需要归还的时候
return false;
}
// 如果没有进入上面的 if,说明主线程已经被阻塞了一段时间了
// 需要归还主线程
if (enableIsInputPending) {
if (needsPaint) {
// There's a pending paint (signaled by `requestPaint`). Yield now.
return true;
}
if (timeElapsed < continuousInputInterval) {
// We haven't blocked the thread for that long. Only yield if there's a
// pending discrete input (e.g. click). It's OK if there's pending
// continuous input (e.g. mouseover).
if (isInputPending !== null) {
return isInputPending();
}
} else if (timeElapsed < maxInterval) {
// Yield if there's either a pending discrete or continuous input.
if (isInputPending !== null) {
return isInputPending(continuousOptions);
}
} else {
// We've blocked the thread for a long time. Even if there's no pending
// input, there may be some other scheduled work that we don't know about,
// like a network event. Yield now.
return true;
}
}
// `isInputPending` isn't available. Yield now.
return true;
}- 首先计算 timeElapsed,然后判断是否超时,没有的话就返回 false,表示不需要归还,否则就返回 true,表示需要归还。
- frameInterval 默认设置的是 5ms
function advanceTimers(currentTime) {
// Check for tasks that are no longer delayed and add them to the queue.
// 从 timerQueue 里面获取一个任务
let timer = peek(timerQueue);
// 遍历整个 timerQueue
while (timer !== null) {
if (timer.callback === null) {
// 这个任务没有对应的要执行的 callback,直接从这个队列弹出
pop(timerQueue);
} else if (timer.startTime <= currentTime) {
// 进入这个分支,说明当前的任务已经不再是延时任务
// 我们需要将其转移到 taskQueue
pop(timerQueue);
timer.sortIndex = timer.expirationTime;
push(taskQueue, timer); // 推入到 taskQueue
// ...
} else {
return;
}
// 从 timerQueue 里面再取一个新的进行判断
timer = peek(timerQueue);
}
}- 该方法就是遍历整个 timerQueue,查看是否有已经过期的方法,如果有,不是说直接执行,而是将这个过期的方法添加到 taskQueue 里面。
function unstable_scheduleCallback(priorityLevel,callback,options){
//...
if (startTime > currentTime) {
// 调度一个延时任务
requestHostTimeout(handleTimeout, startTime - currentTime);
} else {
// 调度一个普通任务
requestHostCallback(flushWork);
}
}- 可以看到,调度一个延时任务的时候,主要是执行 requestHostTimeout
// 实际上在浏览器环境就是 setTimeout
const localSetTimeout = typeof setTimeout === 'function' ? setTimeout : null;
/**
*
* @param {*} callback 就是传入的 handleTimeout
* @param {*} ms 延时的时间
*/
function requestHostTimeout(callback, ms) {
taskTimeoutID = localSetTimeout(() => {
callback(getCurrentTime());
}, ms);
/**
* 因此,上面的代码,就可以看作是
* id = setTimeout(function(){
* handleTimeout(getCurrentTime())
* }, ms)
*/
}可以看到,requestHostTimeout 实际上就是调用 setTimoutout,然后在 setTimeout 中,调用传入的 handleTimeout
/**
*
* @param {*} currentTime 当前时间
*/
function handleTimeout(currentTime) {
isHostTimeoutScheduled = false; // 开关
// 遍历timerQueue,将时间已经到了的延时任务放入到 taskQueue
advanceTimers(currentTime);
if (!isHostCallbackScheduled) {
if (peek(taskQueue) !== null) {
// 从普通任务队列中拿一个任务出来
isHostCallbackScheduled = true;
// 采用调度普通任务的方式进行调度
requestHostCallback(flushWork);
} else {
// taskQueue任务队列里面是空的
// 再从 timerQueue 队列取一个任务出来
// peek 是小顶堆中提供的方法
const firstTimer = peek(timerQueue);
if (firstTimer !== null) {
// 取出来了,接下来取出的延时任务仍然使用 requestHostTimeout 进行调度
requestHostTimeout(handleTimeout, firstTimer.startTime - currentTime);
}
}
}
}- handleTimeout 里面主要就是调用 advanceTimers 方法,该方法的作用是将时间已经到了的延时任务放入到 taskQueue,那么现在 taskQueue 里面就有要执行的任务,然后使用 requestHostCallback 进行调度。如果 taskQueue 里面没有任务了,再次从 timerQueue 里面去获取延时任务,然后通过 requestHostTimeout 进行调度。
Scheduler 这一块儿大致的流程图如下:

在 Scheduler 中,使用最小堆的数据结构在对任务进行排序。
// 两个任务队列
var taskQueue: Array<Task> = [];
var timerQueue: Array<Task> = [];
push(timerQueue, newTask); // 像数组中推入一个任务
pop(timerQueue); // 从数组中弹出一个任务
timer = peek(timerQueue); // 从数组中获取第一个任务所谓二叉树,指的是一个父节点只能有1个或者2个子节点,例如下图:
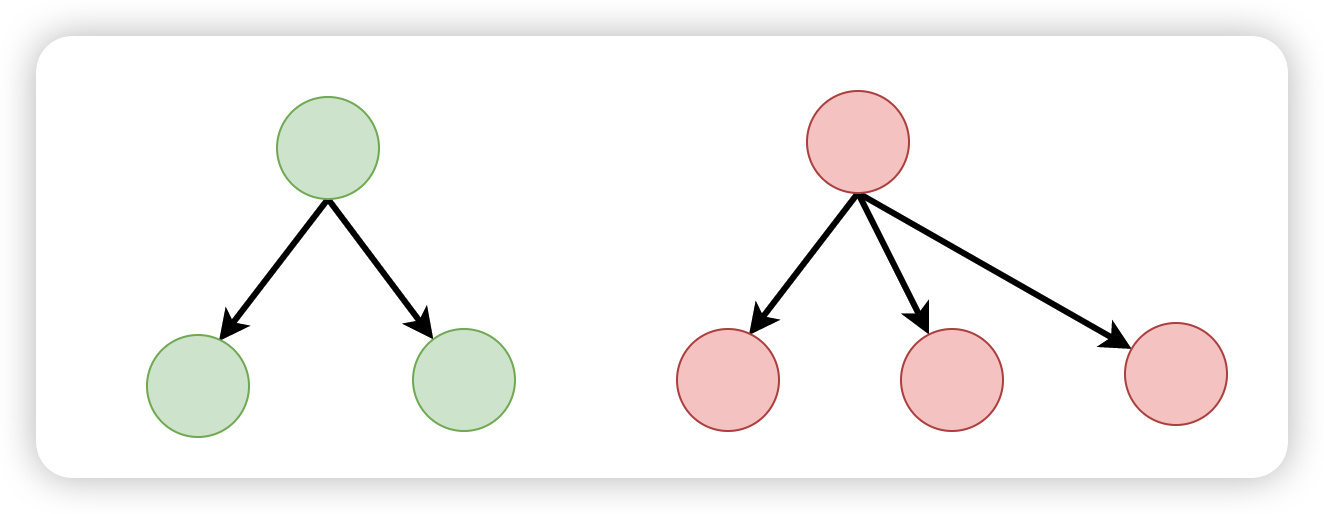
总之就是不能多余两个节点。
所谓完全树,指的是一棵树再进行填写的时候,遵循的是“从左往右,从上往下”
例如下面的这些树,就都是完全树:
再例如,下面的这些树,就不是完全树:

可以分为两大类:
- 最大堆:父节点的数值大于或者等于所有的子节点
- 最小堆:刚好相反,父节点的数值小于或者等于所有的子节点
最大堆示例:
最小堆示例:
- 无论是最大堆还是最小堆,第一个节点一定是这个堆中最大的或者最小的
- 每一层并非是按照一定顺序来排列的,比如下面的例子,6可以在左分支,3可以在右分支
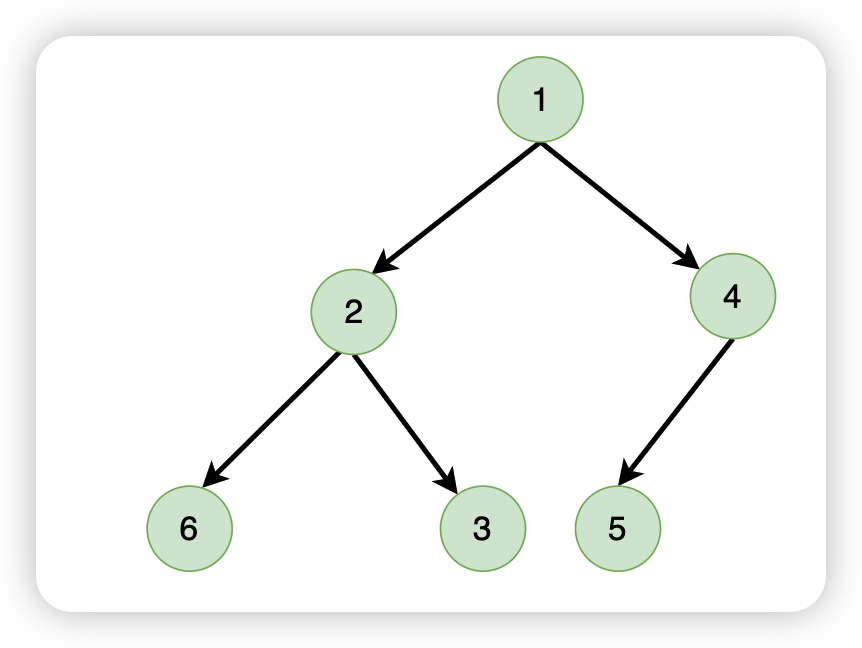
- 每一层的所有元素并非一定比下一层(非自己的子节点)大或者小
堆一般来讲,可以使用数组来实现
通过数组,我们可以非常方便的找到一个节点的所有亲属
- 父节点:Math.floor((当前节点的下标 - 1) / 2)
| 子节点 | 父节点 |
|---|---|
| 1 | 0 |
| 3 | 1 |
| 4 | 1 |
| 5 | 2 |
- 左分支节点:当前节点下标 * 2 + 1
| 父节点 | 左分支节点 |
|---|---|
| 0 | 1 |
| 1 | 3 |
| 2 | 5 |
- 右分支节点:当前节点下标 * 2 + 2
| 父节点 | 右分支节点 |
|---|---|
| 0 | 2 |
| 1 | 4 |
| 2 | 6 |
在 react 中,最小堆对应的源码在 SchedulerMinHeap.js 文件中,总共有 6 个方法,其中向外暴露了 3 个方法
- push:向最小堆推入一个元素
- pop:弹出一个
- peek:取出第一个
没有暴露的是:
- siftUp:向上调整
- siftDown:向下调整
- compare:这是一个辅助方法,就是两个元素做比较的
所谓向上调整,就是指将一个元素和它的父节点做比较,如果比父节点小,那么就应该和父节点做交换,交换完了之后继续和上一层的父节点做比较,依此类推,直到该元素放置到了正确的位置
向下调整,就刚好相反,元素往下走,先和左分支进行比较,如果比左分支小,那就交换。
取出堆顶的任务,堆顶一定是最小的
这个方法极其的简单,如下:
peek(timerQueue);
export function peek(heap) {
// 返回这个数组的第一个元素
return heap.length === 0 ? null : heap[0];
}向最小堆推入一个新任务,因为使用的是数组,所以在推入任务的时候,首先该任务是被推入到数组的最后一项,但是这个时候,涉及到一个调整,我们需要向上调整,把这个任务调整到合适的位置
push(timerQueue, newTask);
export function push(heap, node) {
const index = heap.length;
// 推入到数组的最后一位
heap.push(node);
// 向上调整,调整到合适的位置
siftUp(heap, node, index);
}pop 是从任务堆里面弹出第一个任务,也就是意味着该任务已经没有在队列里面了
pop(taskQueue);
export function pop(heap) {
if (heap.length === 0) {
return null;
}
// 获取数组的第一个任务(一定是最小的)
const first = heap[0];
// 拿到数组的最后一个
const last = heap.pop();
if (last !== first) {
// 将最后一个任务放到第一个
heap[0] = last;
// 接下来向下调整
siftDown(heap, last, 0);
}
return first;
}具体的调整示意图如下:
思考:为什么要从之前的 expirationTime 模型转换为 lane 模型?
之前我们已经介绍过 Scheduler,React 团队是打算将 Scheduler 进行独立发布。
在 React 内部,还会有一个粒度更细的优先级算法,这个就是 lane 模型。
接下来我们来看一下两套优先级模型的一个转换。
在 Scheduler 内部,拥有 5 种优先级:
export const NoPriority = 0;
export const ImmediatePriority = 1;
export const UserBlockingPriority = 2;
export const NormalPriority = 3;
export const LowPriority = 4;
export const IdlePriority = 5;作为一个独立的包,需要考虑到通用性,Scheduler 和 React 的优先级并不共通,在 React 内部,有四种优先级,如下四种:
export const DiscreteEventPriority: EventPriority = SyncLane;
export const ContinuousEventPriority: EventPriority = InputContinuousLane;
export const DefaultEventPriority: EventPriority = DefaultLane;
export const IdleEventPriority: EventPriority = IdleLane;由于 React 中不同的交互对应的事件回调中产生的 update 会有不同的优先级,因此优先级与事件有关,因此在 React 内部的优先级也被称之为 EventPriority,各种优先级的含义如下:
- DiscreteEventPriority:对应离散事件优先级,例如 click、input、focus、blur、touchstart 等事件都是离散触发的
- ContinuousEventPriority:对应连续事件的优先级,例如 drag、mousemove、scroll、touchmove 等事件都是连续触发的
- DefaultEventPriority:对应默认的优先级,例如通过计时器周期性触发更新,这种情况下产生的 update 不属于交互产生 update,所以优先级是默认的优先级
- IdleEventPriority:对应空闲情况的优先级
在上面的代码中,我们还可以观察出一件事情,不同级别的 EventPriority 对应的是不同的 lane
既然 React 与 Scheduler 优先级不互通,那么这里就会涉及到一个转换的问题,这里分为:
- React 优先级转为 Scheduler 的优先级
- Scheduler 的优先级转为 React 的优先级
React 优先级转为 Scheduler 的优先级
整体会经历两次转换:
- 首先是将 lanes 转为 EventPriority,涉及到的方法如下:
export function lanesToEventPriority(lanes: Lanes): EventPriority {
// getHighestPriorityLane 方法用于分离出优先级最高的 lane
const lane = getHighestPriorityLane(lanes);
if (!isHigherEventPriority(DiscreteEventPriority, lane)) {
return DiscreteEventPriority;
}
if (!isHigherEventPriority(ContinuousEventPriority, lane)) {
return ContinuousEventPriority;
}
if (includesNonIdleWork(lane)) {
return DefaultEventPriority;
}
return IdleEventPriority;
}- 将 EventPriority 转换为 Scheduler 的优先级,方法如下:
// ...
let schedulerPriorityLevel;
switch (lanesToEventPriority(nextLanes)) {
case DiscreteEventPriority:
schedulerPriorityLevel = ImmediateSchedulerPriority;
break;
case ContinuousEventPriority:
schedulerPriorityLevel = UserBlockingSchedulerPriority;
break;
case DefaultEventPriority:
schedulerPriorityLevel = NormalSchedulerPriority;
break;
case IdleEventPriority:
schedulerPriorityLevel = IdleSchedulerPriority;
break;
default:
schedulerPriorityLevel = NormalSchedulerPriority;
break;
}
// ...举一个例子,假设现在有一个点击事件,在 onClick 中对应有一个回调函数来触发更新,该更新属于 DiscreteEventPriority,经过上面的两套转换规则进行转换之后,最终得到的 Scheduler 对应的优先级就是 ImmediateSchedulerPriority
Scheduler 的优先级转为 React 的优先级
转换相关的代码如下:
const schedulerPriority = getCurrentSchedulerPriorityLevel();
switch (schedulerPriority) {
case ImmediateSchedulerPriority:
return DiscreteEventPriority;
case UserBlockingSchedulerPriority:
return ContinuousEventPriority;
case NormalSchedulerPriority:
case LowSchedulerPriority:
return DefaultEventPriority;
case IdleSchedulerPriority:
return IdleEventPriority;
default:
return DefaultEventPriority;
}这里会涉及到一个问题,在同一时间可能存在很多的更新,究竟先去更新哪一个?
- 从众多的有优先级的 update 中选出一个优先级最高的
- 表达批的概念
React 在表达方式上面实际上经历了两次迭代:
- 基于 expirationTime 的算法
- 基于 lane 的算法
React 早期采用的就是 expirationTime 的算法,这一点和 Scheduler 里面的设计是一致的。
在 Scheduler 中,设计了 5 种优先级,不同的优先级会对应不同的 timeout,最终会对应不同的 expirationTime,然后 task 根据 expirationTime 来进行任务的排序。
早期的时候在 React 中延续了这种设计,update 的优先级与触发事件的当前时间以及优先级对应的延迟时间相关,这样的算法实际上是比较简单易懂的,每当进入 schedule 的时候,就会选出优先级最高的 update 进行一个调度。
但是这种算法在表示“批”的概念上不够灵活。
在基于 expirationTime 模型的算法中,有如下的表达:
const isUpdateIncludedInBatch = priorityOfUpdate >= priorityOfBatch;priorityOfUpdate 表示的是当前 update 的优先级,priorityOfBatch 代表的是批对应的优先级下限,也就是说,当前的 update 只要大于等于 priorityOfBatch,就会被划分为同一批:

但是此时就会存在一个问题,如何将某一范围的某几个优先级划为同一批?

在上图中,我们想要将 u1、u2、u3 和 u4 划分为同一批,但是以前的 expirationTime 模型是无法做到的。
究其原因,是因为 expirationTime 模型优先级算法耦合了“优先级”和“批”的概念,限制了模型的表达能力。优先级算法的本质是为 update 进行一个排序,但是 expirationTime 模型在完成排序的同时还默认的划定了“批”。
因此,基于上述的原因,React 中引入了 lane 模型。
不管新引入什么模型,比如要保证以下两个问题得到解决:
- 以优先级为依据,对 update 进行一个排序
- 表达批的概念
针对第一个问题,lane模型中设置了很多的 lane,每一个lane实际上是一个二进制数,通过二进制来表达优先级,越低的位代表越高的优先级,例如:
export const SyncLane: Lane = /* */ 0b0000000000000000000000000000001;
export const InputContinuousLane: Lane = /* */ 0b0000000000000000000000000000100;
export const DefaultLane: Lane = /* */ 0b0000000000000000000000000010000;
export const IdleLane: Lane = /* */ 0b0100000000000000000000000000000;
export const OffscreenLane: Lane = /* */ 0b1000000000000000000000000000000;在上面的代码中,SyncLane 是最高优先级,OffscreenLane 是最低优先级。
对于第二个问题,lane模型能够非常灵活的表达批的概念:
// 要使用的批
let batch = 0;
// laneA 和 laneB。是不相邻的优先级
const laneA = 0b0000000000000000000000001000000;
const laneB = 0b0000000000000000000000000000001;
// 将 laneA 纳入批中
batch |= laneA;
// 将 laneB 纳入批中
batch |= laneB;题目:是否了解过 React 中的 lane 模型?为什么要从之前的 expirationTime 模型转换为 lane 模型?
参考答案:
在 React 中有一套独立的粒度更细的优先级算法,这就是 lane 模型。
这是一个基于位运算的算法,每一个 lane 是一个 32 bit Integer,不同的优先级对应了不同的 lane,越低的位代表越高的优先级。
早期的 React 并没有使用 lane 模型,而是采用的的基于 expirationTime 模型的算法,但是这种算法耦合了“优先级”和“批”这两个概念,限制了模型的表达能力。优先级算法的本质是“为 update 排序”,但 expirationTime 模型在完成排序的同时还默认的划定了“批”。
使用 lane 模型就不存在这个问题,因为是基于位运算,所以在批的划分上会更加的灵活。
在 React 中,有很多和性能优化相关的 API:
- shouldComponentUpdate
- PureComponent
- React.memo
- useMemo
- useCallback
实际上,开发者调用上面的 API,内部是在命中 React 的性能优化策略:
- eagerState
- bailout
import { useState } from "react";
// 子组件
function Child() {
console.log("child render");
return <span>child</span>;
}
// 父组件
function App() {
const [num, updateNum] = useState(0);
console.log("App render", num);
return (
<div onClick={() => updateNum(1)}>
<Child />
</div>
);
}在上面的代码中,渲染结果如下:
首次渲染:
App render 0
child render第一次点击
App render 1
child render第二次点击
App render 1第三次以及之后的点击
不会有打印
上面的这个例子实际上就涉及到了我们所提到的 React 内部的两种性能优化策略:
- 在第二次打印的时候,并没有打印 child render,此时实际上是命中了 bailout 策略。命中该策略的组件的子组件会跳过 reconcile 过程,也就是说子组件不会进入 render 阶段。
- 后面的第三次以及之后的点击,没有任何输入,说明 App、Child 都没有进入 render 阶段,此时命中的就是 eagerState 策略,这是一种发生于触发状态更新时的优化策略,如果命中了该策略,此次更新不会进入 schedule 阶段,更不会进入 render 阶段。
该策略的逻辑其实是很简单:如果某个状态更新前后没有变化,那么就可以跳过后续的更新流程。
state 是基于 update 计算出来的,计算过程发生在 render 的 beginWork,而 eagerState 则是将计算过程提前到了 shcedule 之前执行。
该策略有一个前提条件,那就是当前的 FiberNode 不存在待执行的更新,因为如果不存在待执行的更新,那么当前的更新就是第一个更新,那么计算出来的 state 即便有变化也可以作为后续更新的基础 state 来使用。
例如,在使用 useState 触发更新的时候,对应的 dispatchSetState 逻辑如下:
if (
fiber.lanes === NoLanes &&
(alternate === null || alternate.lanes === NoLanes)
) {
// 队列当前为空,这意味着我们可以在进入渲染阶段之前急切地计算下一个状态。 如果新状态与当前状态相同,我们或许可以完全摆脱困境。
const lastRenderedReducer = queue.lastRenderedReducer;
if (lastRenderedReducer !== null) {
let prevDispatcher;
try {
const currentState = queue.lastRenderedState; // 也就是 memoizedState
const eagerState = lastRenderedReducer(currentState, action); // 基于 action 提前计算 state
// 将急切计算的状态和用于计算它的缩减器存储在更新对象上。
// 如果在我们进入渲染阶段时 reducer 没有改变,那么可以使用 eager 状态而无需再次调用 reducer。
update.hasEagerState = true; // 标记该 update 存在 eagerState
update.eagerState = eagerState; // 存储 eagerState 的值
if (is(eagerState, currentState)) {
// ...
return;
}
} catch (error) {
// ...
} finally {
// ...
}
}
}在上面的代码中,首先通过 lastRenderedReducer 来提前计算 state,计算完成后在当前的 update 上面进行标记,之后使用 is(eagerState, currentState) 判断更新后的状态是否有变化,如果进入 if,说明更新前后的状态没有变化,此时就会命中 eagerState 策略,不会进入 schedule 阶段。
即便不为 true,由于当前的更新是该 FiberNode 的第一个更新,因此可以作为后续更新的基础 state,因此这就是为什么在 FC 组件类型的 update 里面有 hasEagerState 以及 eagerState 字段的原因:
const update = {
hasEagerState: false,
eagerState: null,
// ...
}在上面的示例中,比较奇怪的是第二次点击,在第二次点击之前,num 已经为 1 了,但是父组件仍然重新渲染了一次,为什么这种情况没有命中 eagerState 策略?
FiberNode 分为 current 和 wip 两种。
在上面的判断中,实际上会对 current 和 wip 都进行判断,判断的条件为两个 Fiber.lanes 必须要为 NoLanes
if (
fiber.lanes === NoLanes &&
(alternate === null || alternate.lanes === NoLanes)
){
// ....
}对于第一次更新,当 beginWork 开始前,current.lanes 和 wip.lanes 都不是 NoLanes。当 beginWork 执行后, wip.lanes 会被重置为 NoLanes,但是 current.lanes 并不会,current 和 wip 会在 commit 阶段之后才进行互换,这就是为什么第二次没有命中 eagerState 的原因。
那么为什么后面的点击又命中了呢?
虽然上一次点击没有命中 eagerState 策略,但是命中了 bailout 策略,对于命中了 bailout 策略的 FC,会执行 bailoutHooks 方法:
function bailoutHooks(
current: Fiber,
workInProgress: Fiber,
lanes: Lanes,
) {
workInProgress.updateQueue = current.updateQueue;
// ...
current.lanes = removeLanes(current.lanes, lanes);
}在执行 bailoutHooks 方法的时候,最后一句会将当前 FiberNode 的 lanes 移除,因此当这一轮更新完成后,current.lanes 和 wip.lanes 就均为 NoLanes,所以在后续的点击中就会命中 eagerState 策略。
题目:谈一谈 React 中的 eagerState 策略是什么?
参考答案:
在 React 内部,性能优化策略可以分为:
- eagerState 策略
- bailout 策略
eagerState 的核心逻辑是如果某个状态更新前后没有变化,则可以跳过后续的更新流程。该策略将状态的计算提前到了 schedule 阶段之前。当有 FiberNode 命中 eagerState 策略后,就不会再进入 schedule 阶段,直接使用上一次的状态。
该策略有一个前提条件,那就是当前的 FiberNode 不存在待执行的更新,因为如果不存在待执行的更新,当前的更新就是第一个更新,计算出来的 state 即便不能命中 eagerState,也能够在后面作为基础 state 来使用,这就是为什么 FC 所使用的 Update 数据中有 hasEagerState 以及 eagerState 字段的原因。
前面我们学习 beginWork 的时候,我们知道 beginWork 的作用主要是生成 wipFiberNode 的子 FiberNode,要达到这个目录存在两种方式:
- 通过 reconcile 流程生成子 FiberNode
- 通过命中 bailout 策略来复用子 FiberNode
在前面我们讲过,所有的变化都是由“自变量”的改变造成的,在 React 中自变量:
- state
- props
- context
因此是否命中 bailout 主要也是围绕这三个变量展开的,整体的工作流程如下:
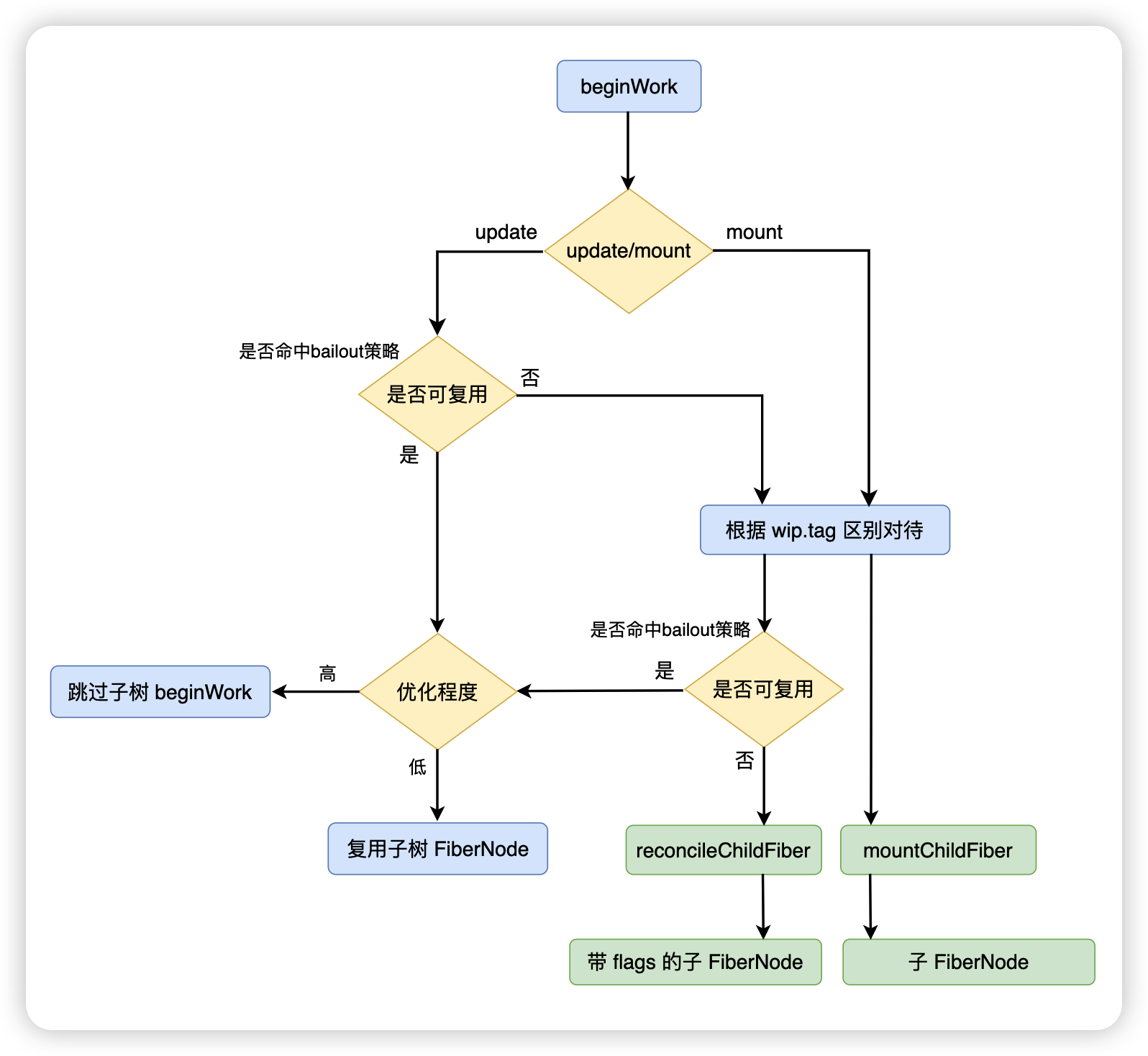
从上图可以看出,bailout 是否命中发生在 update 阶段,在进入 beginWork 后,会有两次是否命中 bailout 策略的相关判断
第一次判断发生在确定了是 update 后,立马就会进行是否能够复用的判断:
- oldProps 全等于 newProps
- Legacy Context 没有变化
- FiberNode.type 没有变化
- 当前 FiberNode 没有更新发生
oldProps 全等于 newProps
注意这里是做的一个全等比较。组件在 render 之后,拿到的是一个 React 元素,会针对 React 元素的 props 进行一个全等比较。但是由于每一次组件 render 的时候,会生成一个全新的对象引用,因此 oldProps 和 newProps 并不会全等,此时是没有办法命中 bailout。
只有当父 FiberNode 命中 bailout 策略时,复用子 FiberNode,在子 FiberNode 的 beginWork 中,oldProps 才有可能和 newProps 全等。
备注:视频中这里讲解有误,不是针对 props 属性每一项进行比较,而是针对 props 对象进行全等比较。上面的笔记内容已修改。
Legacy Context 没有变化
Legacy Context指的是旧的 ContextAPI,ContextAPI重构过一次,之所以重构,就是和 bailout策略相关。
FiberNode.type 没有变化
这里所指的 FiberNode.type 没有变化,指的是不能有例如从 div 变为 p 这种变化。
function App(){
const Child = () => <div>child</div>
return <Child/>
}在上面的代码中,我们在 App 组件中定义了 Child 组件,那么 App 每次 render 之后都会创建新的 Child 的引用,因此对于 Child 来讲,FiberNode.type 始终是变化的,无法命中 bailout 策略。
因此不要在组件内部再定义组件,以免无法命中优化策略。
当前 FiberNode 没有更新发生
当前 FiberNode 没有发生更新,则意味着 state 没有发生变化。
例如在源码中经常会存在是否有更新的检查:
function checkScheduledUpdateOrContext(current, renderLanes) {
// 在执行 bailout 之前,我们必须检查是否有待处理的更新或 context。
const updateLanes = current.lanes;
if (includesSomeLane(updateLanes, renderLanes)) {
// 存在更新
return true;
}
//...
// 不存在更新
return false;
}当以上条件都满足的时候,会命中 bailout 策略,命中该策略后,会执行 bailoutOnAlreadyFinishedWork 方法,在该方法中,会进一步的判断优化程序,根据优化程度来决定是整颗子树都命中 bailout 还是复用子树的 FiberNode
function bailoutOnAlreadyFinishedWork(current, workInProgress, renderLanes) {
// ...
if (!includesSomeLane(renderLanes, workInProgress.childLanes)) {
// ...
// 整颗子树都命中 bailout 策略
return null;
}
// 该 FiberNode 没有命中 bailout,但它的子树命中了。克隆子 FiberNode 并继续
cloneChildFibers(current, workInProgress);
return workInProgress.child;
}通过 wipFiberNode.childLanes 就可以快速的排查当前的 FiberNode 的整颗子树是否存在更新,如果不存在,直接跳过整颗子树的 beginWork。
这其实也解释了为什么每次 React 更新都会生成一颗完整的 FiberTree 但是性能上并不差的原因。
如果第一次没有命中 bailout 策略,则会根据 tag 的不同进入不同的处理逻辑,之后还会再进行第二次的判断。
第二次判断的时候会有两种命中的可能:
- 开发者使用了性能优化 API
- 虽然有更新,但是 state 没有变化
开发者使用了性能优化 API
在第一次判断的时候,默认是对 props 进行全等比较,要满足这个条件实际上是比较困难的,性能优化 API 的工作原理主要就是改写这个判断条件。
比如 React.memo,通过该 API 创建的 FC 对应的 FiberNode.tag 为 MemoComponent,在 beginWork 中对应的处理逻辑如下:
const hasScheduledUpdateOrContext = checkScheduledUpdateOrContext(
current,
renderLanes,
);
if (!hasScheduledUpdateOrContext) {
const prevProps = currentChild.memoizedProps;
// 比较函数,默认进行浅比较
let compare = Component.compare;
compare = compare !== null ? compare : shallowEqual;
if (compare(prevProps, nextProps) && current.ref === workInProgress.ref) {
// 如果 props 经比较未变化,且 ref 不变,则命中 bailout 策略
return bailoutOnAlreadyFinishedWork(current, workInProgress, renderLanes);
}
}因此是否命中 bailout 策略的条件就变成了如下三个:
- 不存在更新
- 经过比较(浅比较)后 props 没有变化
- ref 没有发生改变
如果同时满足上面这三个条件,就会命中 bailout 策略,执行 bailoutOnAlreadyFinishedWork 方法。相较于第一次判断,第二次判断 props 采用的是浅比较进行判断,因此能够更加容易命中 bailout
例如再来看一个例子,比如 ClassComponent 的优化手段经常会涉及到 PureComponent 或者 shouldComponentUpdate,这两个 API 实际上背后也是在优化命中bailout 策略的方式
在 ClassComponnet 的 beginWork 方法中,有如下的代码:
if(!shouldUpdate && !didCaptureError){
// 省略代码
return bailoutOnAlreadyFinishedWork(current, workInProgress, renderLanes);
}shouldUpdate 变量受 checkShouldComponentUpdate 方法的影响:
function checkShouldComponentUpdate(
workInProgress,
ctor,
oldProps,
newProps,
oldState,
newState,
nextContext,
) {
// ClassComponent 实例
const instance = workInProgress.stateNode;
if (typeof instance.shouldComponentUpdate === 'function') {
let shouldUpdate = instance.shouldComponentUpdate(
newProps,
newState,
nextContext,
);
// shouldComponentUpdate 执行后的返回值作为 shouldUpdate
return shouldUpdate;
}
// 如果是 PureComponent
if (ctor.prototype && ctor.prototype.isPureReactComponent) {
// 进行浅比较
return (
!shallowEqual(oldProps, newProps) || !shallowEqual(oldState, newState)
);
}
return true;
}通过上面的代码中我们可以看出,PureComponent 通过浅比较来决定shouldUpdate的值,而shouldUpdate的值又决定了是否能够命中 bailout 策略。
虽然有更新,但是 state 没有变化
在第一次进行判断的时候,其中有一个条件是当前的 FiberNode 没有更新发生,没有更新就意味着 state 没有改变。但是还有一种情况,那就是有更新,但是更新前后计算出来的 state 仍然没有变化,此时就也会命中 bailout 策略。
例如在 FC 的 beginWork 中,有如下一段逻辑:
function updateFunctionComponent(
current,
workInProgress,
Component,
nextProps: any,
renderLanes,
) {
//...
if (current !== null && !didReceiveUpdate) {
// 命中 bailout 策略
bailoutHooks(current, workInProgress, renderLanes);
return bailoutOnAlreadyFinishedWork(current, workInProgress, renderLanes);
}
// ...
// 进入 reconcile 流程
reconcileChildren(current, workInProgress, nextChildren, renderLanes);
return workInProgress.child;
}在上面的代码中,是否能够命中 bailout 策略取决于 didReceiveUpdate,接下来我们来看一下这个值是如何确定的:
// updateReducer 内部在计算新的状态时
if (!is(newState, hook.memoizedState)) {
markWorkInProgressReceivedUpdate();
}
function markWorkInProgressReceivedUpdate() {
didReceiveUpdate = true;
}题目:谈一谈 React 中的 bailout 策略
参考答案:
在 beginWork 中,会根据 wip FiberNode 生成对应的子 FiberNode,此时会有两次“是否命中 bailout策略”的相关判断。
第一次判断
- oldProps 全等于 newProps
- Legacy Context 没有变化
- FiberNode.type 没有变化
- 当前 FiberNode 没有更新发生
当以上条件都满足时会命中 bailout 策略,之后会执行 bailoutOnAlreadyFinishedWork 方法,该方法会进一步判断能够优化到何种程度。
通过 wip.childLanes 可以快速排查“当前 FiberNode 的整颗子树中是否存在更新”,如果不存在,则可以跳过整个子树的 beginWork。这其实也是为什么 React 每次更新都要生成一棵完整的 Fiebr Tree 但是性能并不差的原因。
第二次判断
- 开发者使用了性能优化 API,此时要求当前的 FiberNode 要同时满足:
- 不存在更新
- 经过比较(默认浅比较)后 props 未变化
- ref 不变
- 虽然有更新,但是 state 没有变化
思考:为什么要重构 ContextAPI,旧版的 ContextAPI 有什么问题?
ContextAPI 经历过一次重构,重构的原因和 bailout 策略相关。
在旧版的 ContextAPI 中,数据是保存在栈里面的。
在 beginWork 中,context 会不断的入栈(context栈),这意味着 context consumer 可以通过这个 context 栈来找到对应的 context 数据。在 completeWork 中,context 会不断的出栈。
这种入栈出栈的模式,刚好对应了 reconcile 的流程以及一般的 bailout 策略。
那么旧版的 ContextAPI 存在什么缺陷呢?
但是针对“跳过整颗子树的 beginWork”这种程度的 bailout 策略,被跳过的子树就不会再经历 context 入栈出栈的过程,因此如果使用旧的 ContextAPI ,即使此时 context 里面的数据发生了变化,但是因为子树命中了 bailout 策略被整颗跳过了,所以子树中的 context consumer 就不会响应更新。
例如,有如下的代码:
import React, { useState,useContext } from "react";
// 创建了一个 context 上下文
const MyContext = React.createContext(0);
const { Provider } = MyContext;
function NumProvider({children}) {
// 在 NumProvider 中维护了一个数据
const [num, add] = useState(0);
return (
// 将 num 数据放入到了上下文中
<Provider value={num}>
<button onClick={() => add(num + 1)}>add</button>
{children}
</Provider>
);
}
class Middle extends React.Component{
shouldComponentUpdate(){
// 直接返回 false,意味着会命中 bailout 策略
return false;
}
render(){
return <Child/>;
}
}
function Child(){
// 从 context 上下文中获取数据,然后渲染
const num = useContext(MyContext);
// 也就是说,最终 Child 组件所渲染的数据不是自身组件,而是来自于上下文
// 其中它的父组件会命中 bailout 策略
return <p>{num}</p>
}
// 父组件
function App() {
return (
<NumProvider>
<Middle />
</NumProvider>
);
}
export default App;在上面的示例中,App 是挂载的组件,NumProvider 是 context Provider(上下文的提供者),Child 是 context Consumer(上下文的消费者)。在 App 和 Child 之间有一个 Middle,我们在 Middle 组件直接使用了性能优化 API,设置 shouldComponentUpdate 为 false,使其直接命中 bailout 策略。
当点击 button 之后,num 会增加,但是如果是在旧版的 ContextAPI 中,这段代码是会存在缺陷的,在旧版 ContextAPI 中,子树的 beginWork 都会被跳过,这意味着 Child 组件的 beginWork 也会被跳过,表现出来的现象就是点击 button 后 num 不变。
那么新版的 ContextAPI 是如何修复的呢?
当 beginWork 进行到 context privider 的时候,会有如下的处理逻辑:
if(objectIs(oldValue, newValue)){
// context value 未发生变化
if(oldProps.children === newProps.children && !hasContextChanged()) {
// 命中 bailout 策略
return bailoutOnAlreadyFinnishedWork(current, workInProgress, renderLanes);
}
} else {
// context value 变化,向下寻找 Consumer,标记更新
propageteContextChange(workInProgress, context, renderLanes);
}在上面的代码中,首先会判断 context value 是否有变化,当 context value 发生变化时,beginWork 会从 Provider 立刻向下开启一次深度优先遍历,目的就是为了寻找 context consumer,如果一旦找到 context consumer,就对为对应的 FiberNode.lanes 上面附加一个 renderLanes,对应的相关逻辑如下:
// Context Consumer lanes 附加上 renderLanes
fiber.lanes = mergeLanes(fiber.lanes, renderLanes);
const alternate = fiber.alternate;
if(alternate !== null){
alternate.lanes = mergeLanes(alternate.lanes, renderLanes);
}
// 从 Context Consumer 向上遍历
scheduleWorkOnParentPath(fiber.return, renderLanes);上面的 scheduleWorkOnParentPath 方法的作用是从 context consumer 向上遍历,依次为祖先的 FiberNode.childLanes 附加 renderLanes。
因此,我们来总结一下,当 context value 发生变化的时候,beginWork 从 Provider 开始向下遍历,找到 context consumer 之后为当前的 FiberNode 标记一个 renderLanes,再从 context consumer 向上遍历,为祖先的 FiberNode.childLanes 标记一个 renderLanes。
注意无论是向下遍历寻找 context consumer 还是从 context consumer 向上遍历修改 childLanes,这个都发生在 Provider 的 beginWork 中。
因此,上述的流程完成后,虽然 Provider 命中了 bailout 策略,但是由于流程中 childLanes 已经被修改了,因此就不会命中“跳过整颗子树的beginWork”的逻辑,相关代码如下:
function bailoutOnAlreadyFinishedWork(
current,
workInProgress,
renderLanes
){
//...
// 不会命中该逻辑
if(!includesSomeLane(renderLanes, workInProgress.childLanes)){
// 整颗子树都命中 bailout 策略
return null;
}
//...
}通过上面的代码我们可以看出,“如果子树深处存在 context consumer”,即使子树的根 FiberNode 命中了 bailout 策略,由于存在 childLanes 的标记,因此不会完全跳过子树的 beginWork 过程,所以新版的 ContextAPI 能实现更新,解决了旧版 ContextAPI 无法更新的问题。
题目:为什么要重构 ContextAPI,旧版的 ContextAPI 有什么问题?
参考答案:
旧版的 ContextAPI 存在一些缺陷。
context 中的数据是保存在栈里面的。在 beginWork 中,context 会不断的入栈,所以 context Consumer 可以通过 context 栈向上找到对应的 context value,在 completeWork 中,context 会不断出栈。
这种入栈出栈的模式刚好可以用来应对 reconcile 流程以及一般的 bailout 策略。
但是,对于“跳过整颗子树的 beginWork”这种程度的 bailout 策略,被跳过的子树就不会再经历 context 的入栈和出栈过程,因此在使用旧的ContextAPI时,即使 context里面的数据发生了变化,但只要子树命中了bailout策略被跳过了,那么子树中的 Consumer 就不会响应更新。
新版的 ContextAPI 当 context value 发生变化时,beginWork 会从 Provider 立刻向下开启一次深度优先遍历,目的是寻找 Context Consumer。Context Consumer 找到后,会为其对应的 FiberNode.lanes 附加 renderLanes,再从 context consumer 向上遍历,为祖先的 FiberNode.childLanes 标记一个 renderLanes。因此如果子树深处存在 Context Consumer,即使子树的根 FiberNode 命中 bailout 策略,也不会完全跳过子树的 beginWork 流程 。
在前面我们已经学习了 React 中内置的性能优化相关策略,包括:
- eagerState 策略
- bailout 策略
其中 eagerState 策略需要满足的条件是比较苛刻的,开发时不必强求。但是作为 React 开发者,应该追求写出满足 bailout 策略的组件。
当我们聊到性能优化的时候,常见的想法就是使用性能优化相关的 API,但是当我们深入学习 bailout 策略的原理后,我们就会知道,即使不使用性能优化 API,只要满足一定条件,也能命中 bailout 策略。
我们来看一个例子:
import React, { useState } from "react";
function ExpensiveCom() {
const now = performance.now();
while (performance.now() - now < 200) {}
return <p>耗时的组件</p>;
}
function App() {
const [num, updateNum] = useState(0);
return (
<>
<input value={num} onChange={(e) => updateNum(e.target.value)} />
<p>num is {num}</p>
<ExpensiveCom />
</>
);
}
export default App;在上面的例子中,App 是挂载的组件,由于 ExpensiveCom 在 render 时会执行耗时的操作,因此在 input 输入框中输入内容时,会发生明显的卡顿。
究其原因,是因为 ExpensiveCom 组件并没有命中 bailout 策略。
那么为什么该组件没有命中 bailout 策略呢?
在 App 组件中,会触发 state 更新(num 变化),所以 App 是肯定不会命中 bailout 策略的,而在 ExpensiveCom 中判断是否能够命中 bailout 策略时,有一条是 oldProps === newProps,由于 App 每次都是重新 render 的,所以子组件的这个条件并不会满足。
为了使 ExpensiveCom 命中 bailout 策略,咱们就需要从 App 入手,将 num 与 num 相关的视图部分进行一个分离,形成一个独立的组件,如下:
import React, { useState } from "react";
function ExpensiveCom() {
const now = performance.now();
while (performance.now() - now < 200) {}
return <p>耗时的组件</p>;
}
function Input() {
const [num, updateNum] = useState(0);
return (
<div>
<input value={num} onChange={(e) => updateNum(e.target.value)} />
<p>num is {num}</p>
</div>
);
}
function App() {
return (
<>
<Input/>
<ExpensiveCom />
</>
);
}
export default App;在上面的代码中,我们将 App 中的 state 变化调整到了 Input 组件中,这样修改之后对于 App 来讲就不存在 state 的变化了,那么 App 组件就会命中 bailout 策略,从而让 ExpensiveCom 组件也命中 bailout 策略。
命中 bailout 策略后的 ExpensiveCom 组件就不会再执行耗时的 render。
现在我们考虑另一种情况,在如下的组件中,div 的 title 属性依赖 num,无法像上面例子中进行分离,如下:
import React, { useState } from "react";
function ExpensiveCom() {
const now = performance.now();
while (performance.now() - now < 200) {}
return <p>耗时的组件</p>;
}
function App() {
const [num, updateNum] = useState(0);
return (
<div title={num}>
<input value={num} onChange={(e) => updateNum(e.target.value)} />
<p>num is {num}</p>
<ExpensiveCom />
</div>
);
}
export default App;那么此时我们可以通过 children 来达到分离的目的,如下:
import React, { useState } from "react";
function ExpensiveCom() {
const now = performance.now();
while (performance.now() - now < 200) {}
return <p>耗时的组件</p>;
}
function Counter({ children }) {
const [num, updateNum] = useState(0);
return (
<div title={num}>
<input value={num} onChange={(e) => updateNum(e.target.value)} />
<p>num is {num}</p>
{children}
</div>
);
}
function App() {
// 在该 App 当中就没有维护数据了,也就不存在 state 的变化
return (
<Counter>
<ExpensiveCom/>
</Counter>
);
}
export default App;不管采用哪种方式,其本质就是将可变部分与不可变部分进行分离,使不变的部分能够命中 bailout 策略。在日常开发中,即使不使用性能优化 API,合理的组件结构也能为性能助力。
在默认情况下,FiberNode 要命中 bailout 策略还需要满足 oldProps === newProps。这意味着默认情况下,如果父 FiberNode 没有命中策略,子 FiberNode 就不会命中策略,孙 FiberNode 以及子树中的其他 FiberNode 都不会命中策略。所以当我们编写好符合性能优化条件的组件后,还需要注意组件对应子树的根节点。
如果根节点是应用的根节点(HostRootFiber),那么默认情况下 oldProps === newProps,挂载其下的符合性能优化条件的组件能够命中bailout策略。
如果根节点是其他组件,则此时需要使用性能优化 API,将命中 bailout 策略其中的一个条件从“满足 oldProps === newProps” 变为“浅比较 oldProps 与 newProps”。只有根节点命中 bailout 策略,挂载在它之下的符合性能优化条件的组件才能命中 bailout 策略。
如果将性能优化比作治病的话,那么编写符合性能优化条件的组件就相当于药方,而使用性能优化 API 的组件则相当于药引子。单纯使用药方可能起不到预期的疗效(不满足 oldProps === newProps),单纯的使用药引子(仅使用性能优化 API)也会事倍功半。只有足量的药方(满足性能优化条件的组件子树)加上恰到好处的药引子(在子树根节点这样的关键位置使用性能优化API)才能药到病除。
在 React 中,有一套自己的事件系统,如果说 React 中的 FiberTree 这个数据结构是用来描述 UI 的,那么 React 里面的事件系统就是用来描述 FiberTree 和 UI 之间的的交互的。
对于 ReactDOM 宿主环境,这套事件系统由两个部分:
- 合成事件对象
SyntheticEvent (合成事件对象)这个是对浏览器原生事件对象的一层封装,兼容了主流的浏览器,同时拥有和浏览器原生事件相同的 API,例如 stopPropagation 和 preventDefault。SyntheticEvent 存在的目的就是为了消除不同浏览器在事件对象上面的差异。
- 模拟实现事件传播机制
利用事件委托的原理,React 会基于 FiberTree 来实现了事件的捕获、目标以及冒泡的过程(就类似于原生 DOM 的事件传递过程),并且在自己实现的这一套事件传播机制中还加入了许多新的特性,比如:
- 不同的事件对应了不同的优先级
- 定制事件名
- 比如在 React 中统一采用 onXXX 的驼峰写法来绑定事件
- 定制事件的行为
- 例如 onChange 的默认行为与原生的 oninput 是相同
React 事件系统需要考虑到很多边界情况,因此代码量是非常大的,我们这里通过书写一个简易版的事件系统来学习 React 事件系统的原理。
假设,现在我们有如下这一段 JSX 代码:
const jsx = (
<div onClick={(e) => console.log("click div")}>
<h3>你好</h3>
<button
onClick={(e) => {
// e.stopPropagation();
console.log("click button");
}}
>
点击
</button>
</div>
);在上面的代码中,我们为外层的 div 以及内部的 button 都绑定了点击事件,默认情况下,点击 button 会打印出 click button、click div,如果打开 e.stopPropagation( ),那么就会阻止事件冒泡,只打印出 click button。
可以看出,React 内部的事件系统实现了“模拟实现事件传播机制”。
接下来我们自己来写一套简易版事件系统,绑定事件的方式改为 bindXXXX
SyntheticEvent 指的是合成事件对象,在 React 中的 SyntheticEvent 会包含很多的属性和方法,这里我们出于演示的目的,我们只实现一个阻止冒泡
/**
* 合成事件对象类
*/
class SyntheticEvent {
constructor(e) {
// 保存原生的事件对象
this.nativeEvent = e;
}
// 合成事件对象需要提供一个和原生 DOM 同名的阻止冒泡的方法
stopPropagation() {
// 当开发者调用 stopPropagation 方法,将该合成事件对象的 _stopPropagation 设置为 true
this._stopPropagation = true;
if (this.nativeEvent.stopPropagation) {
// 调用原生事件对象的 stopPropagation 方法来阻止冒泡
this.nativeEvent.stopPropagation();
}
}
}在上面的代码中,我们创建了一个 SyntheticEvent 类,这个类可以用来创建合成事件对象。内部保存了原生的事件对象,还提供了一个和原生 DOM 的事件对象同名的阻止冒泡的方法。
对于可以冒泡的事件,整个事件的传播机制实现步骤如下:
- 在根元素绑定“事件类型对应的事件回调”,所有子孙元素触发该类事件时最终会委托给根元素的事件回调函数来进行处理
- 寻找触发事件的 DOM 元素,找到对应的 FiberNode
- 收集从当前的 FiberNode 到 HostRootFiber 之间所有注册了该事件的回调函数
- 反向遍历并执行一遍收集的所有的回调函数(模拟捕获阶段的实现)
- 正向遍历并执行一遍收集的所有的回调函数(模拟冒泡阶段的实现)
首先我们通过 addEvent 来给根元素绑定事件,目前是为了使用事件委托
/**
* 该方法用于给根元素绑定事件
* @param {*} container 根元素
* @param {*} type 事件类型
*/
export const addEvent = (container, type) => {
container.addEventListener(type, (e) => {
// 进行事件的派发
dispatchEvent(e, type.toUpperCase());
});
};接下来在入口中通过调用 addEvent 来绑定事件,如下:
const root = ReactDOM.createRoot(document.getElementById("root"));
root.render(jsx);
// 进行根元素的事件绑定,换句话说,就是使用我们自己的事件系统
addEvent(document.getElementById("root"), "click");在 addEvent 里面,调用 dispatchEvent 做事件的派发:
/**
*
* @param {*} e 原生的事件对象
* @param {*} type 事件类型,已经全部转为了大写,比如这里传递过来的是 CLICK
*/
const dispatchEvent = (e, type) => {
// 实例化一个合成事件对象
const se = new SyntheticEvent(e);
// 拿到触发事件的元素
const ele = e.target;
let fiber;
// 通过 DOM 元素找到对应的 FiberNode
for (let prop in ele) {
if (prop.toLocaleLowerCase().includes("fiber")) {
fiber = ele[prop];
}
}
// 找到对应的 fiberNode 之后,接下来我们需要收集路径中该事件类型所对应的所有的回调函数
const paths = collectPaths(type, fiber);
// 模拟捕获的实现
triggerEventFlow(paths, type + "CAPTURE", se);
// 模拟冒泡的实现
// 首先需要判断是否阻止了冒泡,如果没有,那么我们只需要将 paths 进行反向再遍历执行一次即可
if(!se._stopPropagation){
triggerEventFlow(paths.reverse(), type, se);
}
};dispatchEvent 方法对应有如下的步骤:
- 实例化一个合成事件对象
- 找到对应的 FiberNode
- 收集从当前的 FiberNode 一直往上所有的该事件类型的回调函数
- 模拟捕获的实现
- 模拟冒泡的实现
/**
* 该方法用于收集路径中所有 type 类型的事件回调函数
* @param {*} type 事件类型
* @param {*} begin FiberNode
* @returns
* [{
* CLICK : function(){...}
* },{
* CLICK : function(){...}
* }]
*/
const collectPaths = (type, begin) => {
const paths = []; // 存放收集到所有的事件回调函数
// 如果不是 HostRootFiber,就一直往上遍历
while (begin.tag !== 3) {
const { memoizedProps, tag } = begin;
// 如果 tag 对应的值为 5,说明是 DOM 元素对应的 FiberNode
if (tag === 5) {
const eventName = "bind" + type; // bindCLICK
// 接下来我们来看当前的节点是否有绑定事件
if (memoizedProps && Object.keys(memoizedProps).includes(eventName)) {
// 如果进入该 if,说明当前这个节点绑定了对应类型的事件
// 需要进行收集,收集到 paths 数组里面
const pathNode = {};
pathNode[type] = memoizedProps[eventName];
paths.push(pathNode);
}
begin = begin.return;
}
}
return paths;
};实现的思路就是从当前的 FiberNode 一直向上遍历,直到 HostRootFiber,收集遍历过程中 FiberNode.memoizedProps 属性所保存的对应的事件处理函数。
最终返回的 paths 数组保存的结构大致如下:
[{
CLICK : function(){...}
},{
CLICK : function(){...}
}]由于我们是从目标元素的 FiberNode 向上遍历的,因此收集到的顺序:
[ 目标元素的事件回调,某个祖先元素的事件回调,某个更上层的祖先元素的事件回调 ]
因此要模拟捕获阶段的实现,我们就需要从后往前进行遍历并执行:
/**
*
* @param {*} paths 收集到的事件回调函数的数组
* @param {*} type 事件类型
* @param {*} se 合成事件对象
*/
const triggerEventFlow = (paths, type, se) => {
// 挨着挨着遍历这个数组,执行回调函数即可
// 模拟捕获阶段的实现,所以需要从后往前遍历数组并执行回调
for (let i = paths.length; i--; ) {
const pathNode = paths[i];
const callback = pathNode[type];
if (callback) {
// 存在回调函数,执行该回调
callback.call(null, se);
}
if (se._stopPropagation) {
// 说明在当前的事件回调函数中,开发者阻止继续往上冒泡
break;
}
}
};在执行事件的回调的时候,每一次执行需要检验 _stopPropagation 属性是否为 true,如果为true,说明当前的事件回调函数中阻止了事件冒泡,因此我们应当停止后续的遍历。
如果是模拟冒泡阶段,只需要将 paths 进行反向再遍历一次并执行即可:
// 模拟冒泡的实现
// 首先需要判断是否阻止了冒泡,如果没有,那么我们只需要将 paths 进行反向再遍历执行一次即可
if(!se._stopPropagation){
triggerEventFlow(paths.reverse(), type, se);
}至此,我们就实现了一个简易版的 React 事件系统。
题目:简述一下 React 中的事件是如何处理的?
参考答案:
在 React 中,有一套自己的事件系统,如果说 React 用 FiberTree 这一数据结构是用来描述 UI 的话,那么事件系统则是基于 FiberTree 来描述和 UI 之间的交互。
对于 ReactDOM 宿主环境,这套事件系统由两个部分组成:
(1)SyntheticEvent(合成事件对象)
SyntheticEvent 是对浏览器原生事件对象的一层封装,兼容主流浏览器,同时拥有与浏览器原生事件相同的 API,例如 stopPropagation 和 preventDefault。SyntheticEvent 存在的目的是为了消除不同浏览器在 “事件对象” 间的差异。
(2)模拟实现事件传播机制
利用事件委托的原理,React 基于 FiberTree 实现了事件的捕获、目标、冒泡的流程(类似于原生事件在 DOM 元素中传递的流程),并且在这套事件传播机制中加入了许多新的特性,例如:
- 不同事件对应了不同的优先级
- 定制事件名
- 例如事件统一采用如 “onXXX” 的驼峰写法
- 定制事件行为
- 例如 onChange 的默认行为与原生 oninput 相同
所谓二进制,指的就是以二为底的一种计数方式。
| 十进制 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 二进制 | 0000 | 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 | 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 |
| 八进制 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 十六进制 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
我们经常会使用二进制来进行计算,基于二进制的位运算能够很方便的表达“增、删、查、改”。
例如一个后台管理系统,一般的话会有针对权限的控制,一般权限的控制就使用的是二进制:
# 各个权限
permissions = {
"SYS_SETTING" : {
"value" : 0b10000000,
"info" : "系统重要设置权限"
},
"DATA_ADMIN" : {
"value" : 0b01000000,
"info" : "数据库管理权限"
},
"USER_MANG" : {
"value" : 0b00100000,
"info" : "用户管理权限"
},
"POST_EDIT" : {
"value" : 0b00010000,
"info" : "文章编辑操作权限"
},
"POST_VIEW" : {
"value" : 0b00001000,
"info" : "文章查看权限"
}
}再例如,在 linux 操作系统里面,x 代表可执行权限,w代表可写权限,r 代表可读权限,对应的权限值分别就是1、2、4(2 的幂次方)
使用二进制来表示权限,首先速度上面会更快一些,其次在表示多种权限的时候,会更加方便一些。
比如,现在有 3 个权限 A、B、C...
根据不同的权限做不同的事情:
if(value === A){
// ...
} else if(value === B){
// ...
}在上面的代码中,会有一个问题,目前仅仅只是一对一的关系,但是在实际开发中,往往有很多一对多的关系,一个 value 可能会对应好几个值。

复习一下和二进制相关的运算:
- 与( & ):只要有一位数为 0,那么最终结果就是 0,也就是说,必须两位都是 1,最终结果才是 1
- 或( | ): 只要有一位数是 1,那么最终结果就是 1,也就是说必须两个都是 0,最终才是 0
- 非 ( ~ ): 对一个二进制数逐位取反,也就是说 0、1 互换
- 异或( ^ ): 如果两个二进制位不相同,那么结果就为 1,相同就为 0
1 & 1 = 1
0000 0001
0000 0001
---------
0000 0001
1 & 0 = 0
0000 0001
0000 0000
---------
0000 0000
1 | 0 = 1
0000 0001
0000 0000
---------
0000 0001
1 ^ 0 = 1
0000 0001
0000 0000
---------
0000 0001
~3
0000 0011
// 逐位取反
1111 1100
// 计算结果最终为 -4(涉及到补码的知识)接下来我们来看一下位运算在权限系统里面的实际运用:
| 下载 | 打印 | 查看 | 审核 | 详细 | 删除 | 编辑 | 创建 |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
如果是 0,代表没有权限,如果是 1,代表有权限
0000 0001 代表只有创建的权限,0010 0011 代表有查看、编辑以及创建的权限
添加权限
直接使用或运算即可。
0000 0011 目前有创建和编辑的权限,我们要给他添加一个查看的权限 0010 0000
0000 0011
0010 0000
---------
0010 0011删除权限
可以使用异或
0010 0011 目前有查看、编辑和创建,取消编辑的权限 0000 0010
0010 0011
0000 0010
---------
0010 0001判断是否有某一个权限
可以使用与来进行判断
0011 1100(查看、审核、详细、删除),判断是否有查看(0010 0000)权限、再判断是否有创建(0000 0001)权限
0011 1100
0010 0000
---------
0010 0000
// 判断是否有“查看”权限,做与操作时得到了“查看”权限值本身,说明有这个权限0011 1100
0000 0001
---------
0000 0000
// 最终得到的值为 0,说明没有此权限通过上面的例子,我们会发现使用位运算确确实实非常的方便,接下来我们就来看一下 React 中针对位运算的使用。
- fiber 的 flags
- lane 模型
- 上下文
fiber 的 flags
在 React 中,用来标记 fiber 操作的 flags,使用的就是二进制:
export const NoFlags = /* */ 0b000000000000000000000000000;
export const PerformedWork = /* */ 0b000000000000000000000000001;
export const Placement = /* */ 0b000000000000000000000000010;
export const DidCapture = /* */ 0b000000000000000000010000000;
export const Hydrating = /* */ 0b000000000000001000000000000;
// ...这些 flags 就是用来标记 fiber 状态的。
之所以要专门抽离 fiber 的状态,是因为这种操作是非常高效的。针对一个 fiber 的操作,可能有增加、删除、修改,但是我不直接进行操作,而是给这个 fiber 打上一个 flag,接下来在后面的流程中针对有 flag 的 fiber 统一进行操作。
通过位运算,就可以很好的解决一个 fiber 有多个 flag 标记的问题,方便合并多个状态
// 初始化一些 flags
const NoFlags = 0b00000000000000000000000000;
const PerformedWork =0b00000000000000000000000001;
const Placement = 0b00000000000000000000000010;
const Update = 0b00000000000000000000000100;
// 一开始将 flag 变量初始化为没有 flag,也就是 NoFlags
let flag = NoFlags
// 这里就是在合并多个状态
flag = flag | PerformedWork | Update
// 要判断是否有某一个 flag,直接通过 & 来进行判断即可
//判断是否有 PerformedWork 种类的更新
if(flag & PerformedWork){
//执行
console.log('执行 PerformedWork')
}
//判断是否有 Update 种类的更新
if(flag & Update){
//执行
console.log('执行 Update')
}
if(flag & Placement){
//不执行
console.log('执行 Placement')
}lane 模型
lane 模型也是一套优先级机制,相比 Scheduler,lane 模型能够对任务进行更细粒度的控制。
export const NoLanes: Lanes = /* */ 0b0000000000000000000000000000000;
export const NoLane: Lane = /* */ 0b0000000000000000000000000000000;
export const SyncLane: Lane = /* */ 0b0000000000000000000000000000001;
export const InputContinuousHydrationLane: Lane = /* */ 0b0000000000000000000000000000010;
export const InputContinuousLane: Lane = /* */ 0b0000000000000000000000000000100;
// ...例如在 React 源码中,有一段如下的代码:
// lanes 一套 lane 的组合
function getHighestPriorityLanes(lanes) {
// 从 lanes 这一套组合中,分离出优先级最高的 lane
switch (getHighestPriorityLane(lanes)) {
case SyncLane:
return SyncLane;
case InputContinuousHydrationLane:
return InputContinuousHydrationLane;
case InputContinuousLane:
return InputContinuousLane;
// ...
return lanes;
}
}
// lane 在表示优先级的时候,大致是这样的:
// 0000 0001
// 0000 0010
// 0010 0000
// lanes 表示一套 lane 的组合,比如上面的三个 lane 组合到一起就变成了一个 lanes 0010 0011
// getHighestPriorityLane 这个方法要做的事情就是分离出优先级最高的
// 0010 0011 ----> getHighestPriorityLane -----> 0000 0001
export function getHighestPriorityLane(lanes) {
return lanes & -lanes;
}假设现在我们针对两个 lane 进行合并
const SyncLane: Lane = /* */ 0b0000000000000000000000000000001;
const InputContinuousLane: Lane = /* */ 0b0000000000000000000000000000100;合并出来就是一个 lanes,合并出来的结果如下:
0b0000000000000000000000000000001
0b0000000000000000000000000000100
---------------------------------
0b00000000000000000000000000001010b0000000000000000000000000000101 是我们的 lanes,接下来取负值
-lanes = 0b1111111111111111111111111111011最后一步,再和本身的 lanes 做一个 & 操作:
0b0000000000000000000000000000101
0b1111111111111111111111111111011
---------------------------------
0b0000000000000000000000000000001经过 & 操作之后,就把优先级最高的 lane 给分离出来了。
上下文
在 React 源码内部,有多个上下文:
// 未处于 React 上下文
export const NoContext = /* */ 0b000;
// 处于 batchedUpdates 上下文
const BatchedContext = /* */ 0b001;
// 处于 render 阶段
export const RenderContext = /* */ 0b010;
// 处于 commit 阶段
export const CommitContext = /* */ 0b100;当执行流程到了 render 阶段,那么接下来就会切换上下文,切换到 RenderContext
let executionContext = NoContext; // 一开始初始化为没有上下文
executionContext |= RenderContext;在执行方法的时候,就会有一个判断,判断当前处于哪一个上下文
// 是否处于 RenderContext 上下文中,结果为 true
(executionContext & RenderContext) !== NoContext
// 是否处于 CommitContext 上下文中,结果为 false
(executionContext & CommitContext) !== NoContext如果要离开某一个上下文
// 从当前上下文中移除 RenderContext 上下文
executionContext &= ~RenderContext;
// 是否处于 RenderContext 上下文中,结果为 false
(executionContext & CommitContext) !== NoContext题目:React 中哪些地方用到了位运算?
参考答案:
位运算可以很方便的表达“增、删、改、查”。在 React 内部,像 flags、状态、优先级等操作都大量使用到了位运算。
细分下来主要有如下的三个地方:
- fiber 的 flags
- lane 模型
- 上下文
思考:React 为什么不采用 Vue 的双端对比算法?
Render 阶段会生成 Fiber Tree,所谓的 diff 实际上就是发生在这个阶段,这里的 diff 指的是 current FiberNode 和 JSX 对象之间进行对比,然后生成新的的 wip FiberNode。
除了 React 以外,其他使用到了虚拟 DOM 的前端框架也会有类似的流程,比如 Vue 里面将这个流程称之为 patch。
diff 算法本身是有性能上面的消耗,在 React 文档中有提到,即便采用最前沿的算法,如果要完整的对比两棵树,那么算法的复杂度都会达到 O(n^3),n 代表的是元素的数量,如果 n 为 1000,要执行的计算量会达到十亿量级的级别。
因此,为了降低算法的复杂度,React 为 diff 算法设置了 3 个限制:
- 限制一:只对同级别元素进行 diff,如果一个 DOM 元素在前后两次更新中跨越了层级,那么 React 不会尝试复用它
- 限制二:两个不同类型的元素会产生不同的树。比如元素从 div 变成了 p,那么 React 会直接销毁 div 以及子孙元素,新建 p 以及 p 对应的子孙元素
- 限制三:开发者可以通过 key 来暗示哪些子元素能够保持稳定
更新前:
<div>
<p key="one">one</p>
<h3 key="two">two</h3>
</div>更新后
<div>
<h3 key="two">two</h3>
<p key="one">one</p>
</div>如果没有 key,那么 React 就会认为 div 的第一个子元素从 p 变成了 h3,第二个子元素从 h3 变成了 p,因此 React 就会采用限制二的规则。
但是如果使用了 key,那么此时的 DOM 元素是可以复用的,只不过前后交换了位置而已。
接下来我们回头再来看限制一,对同级元素进行 diff,究竟是如何进行 diff ?整个 diff 的流程可以分为两大类:
- 更新后只有一个元素,此时就会根据 newChild 创建对应的 wip FiberNode,对应的流程就是单节点 diff
- 更新后有多个元素,此时就会遍历 newChild 创建对应的 wip FiberNode 已经它的兄弟元素,此时对应的流程就是多节点 diff
单节点指的是新节点为单一节点,但是旧节点的数量是不一定
单节点 diff 是否能够复用遵循以下的流程:
- 判断 key 是否相同
- 如果更新前后没有设置 key,那么 key 就是 null,也是属于相同的情况
- 如果 key 相同,那么就会进入到步骤二
- 如果 key 不同,就不需要进入步骤,无需判断 type,结果直接为不能复用(如果有兄弟节点还会去遍历兄弟节点)
- 如果 key 相同,再判断 type 是否相同
- 如果 type 相同,那么就复用
- 如果 type 不同,无法复用(并且兄弟节点也一并标记为删除)
更新前
<ul>
<li>1</li>
<li>2</li>
<li>3</li>
</ul>更新后
<ul>
<p>1</p>
</ul>这里因为没有设置 key,所以会被设为 key 是相同的,接下来就会进入到 type 的判断,此时发现 type 不同,因此不能够复用。
既然这里唯一的可能性都已经不能够复用,会直接标记兄弟 FiberNode 为删除状态。
如果上面的例子中,key 不同只能代表当前的 FiberNode 无法复用,因此还需要去遍历兄弟的 FiberNode
下面我们再来看一些示例
更新前
<div>one</div>更新后
<p>one</p>没有设置 key,那么可以认为默认 key 就是 null,更新前后两个 key 是相同的,接下来就查看 type,发现 type 不同,因此不能复用。
更新前
<div key="one">one</div>更新后
<div key="two">one</div>更新前后 key 不同,不需要再判断 type,结果为不能复用
更新前
<div key="one">one</div>更新后
<p key="two">one</p>更新前后 key 不同,不需要再判断 type,结果为不能复用
更新前
<div key="one">one</div>更新后
<div key="one">two</div>首先判断 key 相同,接下来判断 type 发现也是相同,这个 FiberNode 就能够复用,children 是一个文本节点,之后将文本节点更新即可。
所谓多节点 diff,指的是新节点有多个。
React 团队发现,在日常开发中,对节点的更新操作的情况往往要多余对节点“新增、删除、移动”,因此在进行多节点 diff 的时候,React 会进行两轮遍历:
- 第一轮遍历会尝试逐个的复用节点
- 第二轮遍历处理上一轮遍历中没有处理完的节点
第一轮遍历会从前往后依次进行遍历,存在三种情况:
- 如果新旧子节点的key 和 type 都相同,说明可以复用
- 如果新旧子节点的 key 相同,但是 type 不相同,这个时候就会根据 ReactElement 来生成一个全新的 fiber,旧的 fiber 被放入到 deletions 数组里面,回头统一删除。但是注意,此时遍历并不会终止
- 如果新旧子节点的 key 和 type 都不相同,结束遍历
示例一
更新前
<div>
<div key="a">a</div>
<div key="b">b</div>
<div key="c">c</div>
<div key="d">d</div>
</div>更新后
<div>
<div key="a">a</div>
<div key="b">b</div>
<div key="e">e</div>
<div key="d">d</div>
</div>首先遍历到 div.key.a,发现该 FiberNode 能够复用

继续往后面走,发现 div.key.b 也能够复用

接下来继续往后面走,div.key.e,这个时候发现 key 不一样,因此第一轮遍历就结束了

示例二
更新前
<div>
<div key="a">a</div>
<div key="b">b</div>
<div key="c">c</div>
<div key="d">d</div>
</div>更新后
<div>
<div key="a">a</div>
<div key="b">b</div>
<p key="c">c</p>
<div key="d">d</div>
</div>首先和上面的一样,div.key.a 和 div.key.b 这两个 FiberNode 可以进行复用,接下来到了第三个节点,此时会发现 key 是相同的,但是 type 不相同,此时就会将对应的旧的 FiberNode 放入到一个叫 deletions 的数组里面,回头统一进行删除,根据新的 React 元素创建一个新的 FiberNode,但是此时的遍历是不会结束的

接下来继续往后面进行遍历,遍历什么时候结束呢?
- 到末尾了,也就是说整个遍历完了
- 或者是和示例一相同,可以 key 不同

如果第一轮遍历被提前终止了,那么意味着有新的 React 元素或者旧的 FiberNode 没有遍历完,此时就会采用第二轮遍历
第二轮遍历会处理这么三种情况:
-
只剩下旧子节点:将旧的子节点添加到 deletions 数组里面直接删除掉(删除的情况)
-
只剩下新的 JSX 元素:根据 ReactElement 元素来创建 FiberNode 节点(新增的情况)
-
新旧子节点都有剩余:会将剩余的 FiberNode 节点放入一个 map 里面,遍历剩余的新的 JSX 元素,然后从 map 中去寻找能够复用的 FiberNode 节点,如果能够找到,就拿来复用。(移动的情况)
如果不能找到,就新增呗。然后如果剩余的 JSX 元素都遍历完了,map 结构中还有剩余的 Fiber 节点,就将这些 Fiber 节点添加到 deletions 数组里面,之后统一做删除操作
只剩下旧子节点
更新前
<div>
<div key="a">a</div>
<div key="b">b</div>
<div key="c">c</div>
<div key="d">d</div>
</div>更新后
<div>
<div key="a">a</div>
<div key="b">b</div>
</div>遍历前面两个节点,发现能够复用,此时就会复用前面的节点,对于 React 元素来讲,遍历完前面两个就已经遍历结束了,因此剩下的FiberNode就会被放入到 deletions 数组里面,之后统一进行删除

只剩下新的 JSX 元素
更新前
<div>
<div key="a">a</div>
<div key="b">b</div>
</div>更新后
<div>
<div key="a">a</div>
<div key="b">b</div>
<div key="c">c</div>
<div key="d">d</div>
</div>根据新的 React 元素新增对应的 FiberNode 即可。

新旧子节点都有剩余
更新前
<div>
<div key="a">a</div>
<div key="b">b</div>
<div key="c">c</div>
<div key="d">d</div>
</div>更新后
<div>
<div key="a">a</div>
<div key="c">b</div>
<div key="b">b</div>
<div key="e">e</div>
</div>首先会将剩余的旧的 FiberNode 放入到一个 map 里面

接下来会继续去遍历剩下的 JSX 对象数组,遍历的同时,从 map 里面去找有没有能够复用

如果在 map 里面没有找到,那就会新增这个 FiberNode,如果整个 JSX 对象数组遍历完成后,map 里面还有剩余的 FiberNode,说明这些 FiberNode 是无法进行复用,直接放入到 deletions 数组里面,后期统一进行删除。

所谓双端,指的是在新旧子节点的数组中,各用两个指针指向头尾的节点,在遍历的过程中,头尾两个指针同时向中间靠拢。
因此在新子节点数组中,会有两个指针,newStartIndex 和 newEndIndex 分别指向新子节点数组的头和尾。在旧子节点数组中,也会有两个指针,oldStartIndex 和 oldEndIndex 分别指向旧子节点数组的头和尾。

{kind=link}
每遍历到一个节点,就尝试进行双端比较:「新前 vs 旧前」、「新后 vs 旧后」、「新后 vs 旧前」、「新前 vs 旧后」,如果匹配成功,更新双端的指针。比如,新旧子节点通过「新前 vs 旧后」匹配成功,那么 newStartIndex += 1,oldEndIndex -= 1。
如果新旧子节点通过「新后 vs 旧前」匹配成功,还需要将「旧前」对应的 DOM 节点插入到「旧后」对应的 DOM 节点之前。如果新旧子节点通过「新前 vs 旧后」匹配成功,还需要将「旧后」对应的 DOM 节点插入到「旧前」对应的 DOM 节点之前。
实际上在 React 的源码中,解释了为什么不使用双端 diff
function reconcileChildrenArray(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
newChildren: Array<*>,
expirationTime: ExpirationTime,
): Fiber | null {
// This algorithm can't optimize by searching from boths ends since we
// don't have backpointers on fibers. I'm trying to see how far we can get
// with that model. If it ends up not being worth the tradeoffs, we can
// add it later.
// Even with a two ended optimization, we'd want to optimize for the case
// where there are few changes and brute force the comparison instead of
// going for the Map. It'd like to explore hitting that path first in
// forward-only mode and only go for the Map once we notice that we need
// lots of look ahead. This doesn't handle reversal as well as two ended
// search but that's unusual. Besides, for the two ended optimization to
// work on Iterables, we'd need to copy the whole set.
// In this first iteration, we'll just live with hitting the bad case
// (adding everything to a Map) in for every insert/move.
// If you change this code, also update reconcileChildrenIterator() which
// uses the same algorithm.
}将上面的注视翻译成中文如下:
由于双端 diff 需要向前查找节点,但每个 FiberNode 节点上都没有反向指针,即前一个 FiberNode 通过 sibling 属性指向后一个 FiberNode,只能从前往后遍历,而不能反过来,因此该算法无法通过双端搜索来进行优化。
React 想看下现在用这种方式能走多远,如果这种方式不理想,以后再考虑实现双端 diff。React 认为对于列表反转和需要进行双端搜索的场景是少见的,所以在这一版的实现中,先不对 bad case 做额外的优化。
题目:React 中的 diff 算法有没有了解过?具体的流程是怎么样的?React 为什么不采用 Vue 的双端对比算法?
参考答案:
diff 计算发生在更新阶段,当第一次渲染完成后,就会产生 Fiber 树,再次渲染的时候(更新),就会拿新的 JSX 对象(vdom)和旧的 FiberNode 节点进行一个对比,再决定如何来产生新的 FiberNode,它的目标是尽可能的复用已有的 Fiber 节点。这个就是 diff 算法。
在 React 中整个 diff 分为单节点 diff 和多节点 diff。
所谓单节点是指新的节点为单一节点,但是旧节点的数量是不一定的。
单节点 diff 是否能够复用遵循如下的顺序:
判断 key 是否相同
如果更新前后均未设置 key,则 key 均为 null,也属于相同的情况
如果 key 相同,进入步骤二
如果 key 不同,则无需判断 type,结果为不能复用(有兄弟节点还会去遍历兄弟节点)
如果 key 相同,再判断 type 是否相同
- 如果 type 相同,那么就复用
- 如果 type 不同,则无法复用(并且兄弟节点也一并标记为删除)
多节点 diff 会分为两轮遍历:
第一轮遍历会从前往后进行遍历,存在以下三种情况:
- 如果新旧子节点的key 和 type 都相同,说明可以复用
- 如果新旧子节点的 key 相同,但是 type 不相同,这个时候就会根据 ReactElement 来生成一个全新的 fiber,旧的 fiber 被放入到 deletions 数组里面,回头统一删除。但是注意,此时遍历并不会终止
- 如果新旧子节点的 key 和 type 都不相同,结束遍历
如果第一轮遍历被提前终止了,那么意味着还有新的 JSX 元素或者旧的 FiberNode 没有被遍历,因此会采用第二轮遍历去处理。
第二轮遍历会遇到三种情况:
只剩下旧子节点:将旧的子节点添加到 deletions 数组里面直接删除掉(删除的情况)
只剩下新的 JSX 元素:根据 ReactElement 元素来创建 FiberNode 节点(新增的情况)
新旧子节点都有剩余:会将剩余的 FiberNode 节点放入一个 map 里面,遍历剩余的新的 JSX 元素,然后从 map 中去寻找能够复用的 FiberNode 节点,如果能够找到,就拿来复用。(移动的情况)
如果不能找到,就新增呗。然后如果剩余的 JSX 元素都遍历完了,map 结构中还有剩余的 Fiber 节点,就将这些 Fiber 节点添加到 deletions 数组里面,之后统一做删除操作
整个 diff 算法最最核心的就是两个字“复用”。
React 不使用双端 diff 的原因:
由于双端 diff 需要向前查找节点,但每个 FiberNode 节点上都没有反向指针,即前一个 FiberNode 通过 sibling 属性指向后一个 FiberNode,只能从前往后遍历,而不能反过来,因此该算法无法通过双端搜索来进行优化。
React 想看下现在用这种方式能走多远,如果这种方式不理想,以后再考虑实现双端 diff。React 认为对于列表反转和需要进行双端搜索的场景是少见的,所以在这一版的实现中,先不对 bad case 做额外的优化。
如果你觉得这篇内容对你挺有有帮助的话:
点赞支持下吧,让更多的人也能看到这篇内容(收藏不点赞,都是耍流氓 -_-)欢迎在留言区与我分享你的想法,也欢迎你在留言区记录你的思考过程。觉得不错的话,也可以阅读Sunny近期梳理的文章(感谢掘友的鼓励与支持🌹🌹🌹):
热门文章
- ✨ 爆肝10w字,带你精通 React18 架构设计和源码实现【上】
- ✨ 爆肝10w字,带你精通 React18 架构设计和源码实现【下】
- 前端包管理进阶:通用函数库与组件库打包实战
- 🍻 前端服务监控原理与手写开源监控框架SDK
- 🚀 2w字带你精通前端脚手架开源工具开发
- 🔥 爆肝5w字,带你深入前端构建工具 Rollup 高阶使用、API、插件机制和开发
专栏