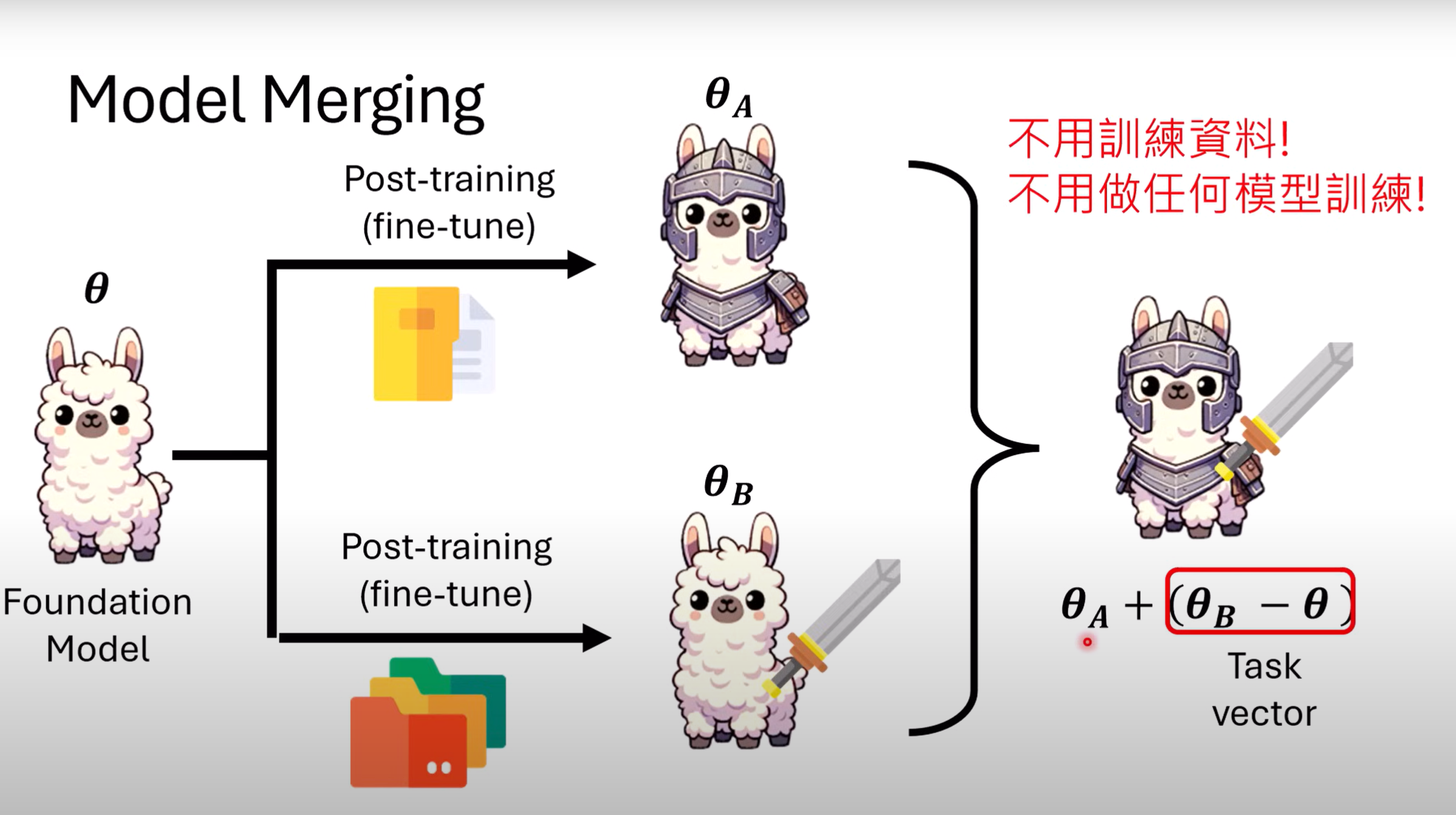
假定有两个不同资料集对base model进行Post-training,使模型获得能力A或者能力B.如果要模型同时具备能力AB,则可以用另一资料集(混杂部分原资料)再次进行Post-training.但模型融合仅需要求出base model的参数$\theta$,再求得$\theta_A$和$\theta_B$,$\theta_A+(\theta_B-\theta)$即为同时具备AB能力的模型,把$\theta_B-\theta$称作Task Vector
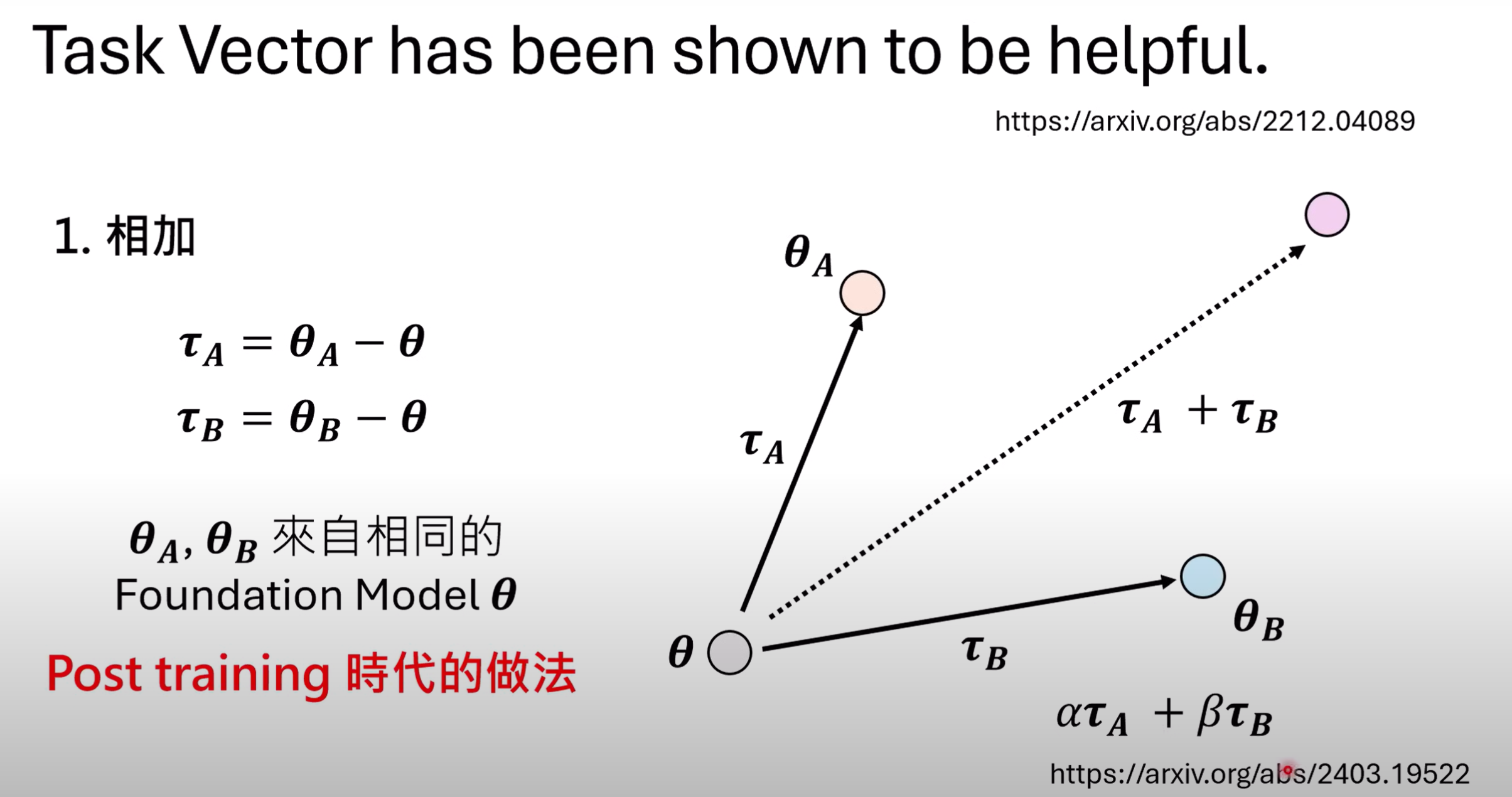
- 在$\theta_A$和$\theta_B$来自相同的Foundation Model$\theta$的情况下,可以对Task Vector$\tau$赋予需要的权重后相加,可以融合不同模型的不同技能.
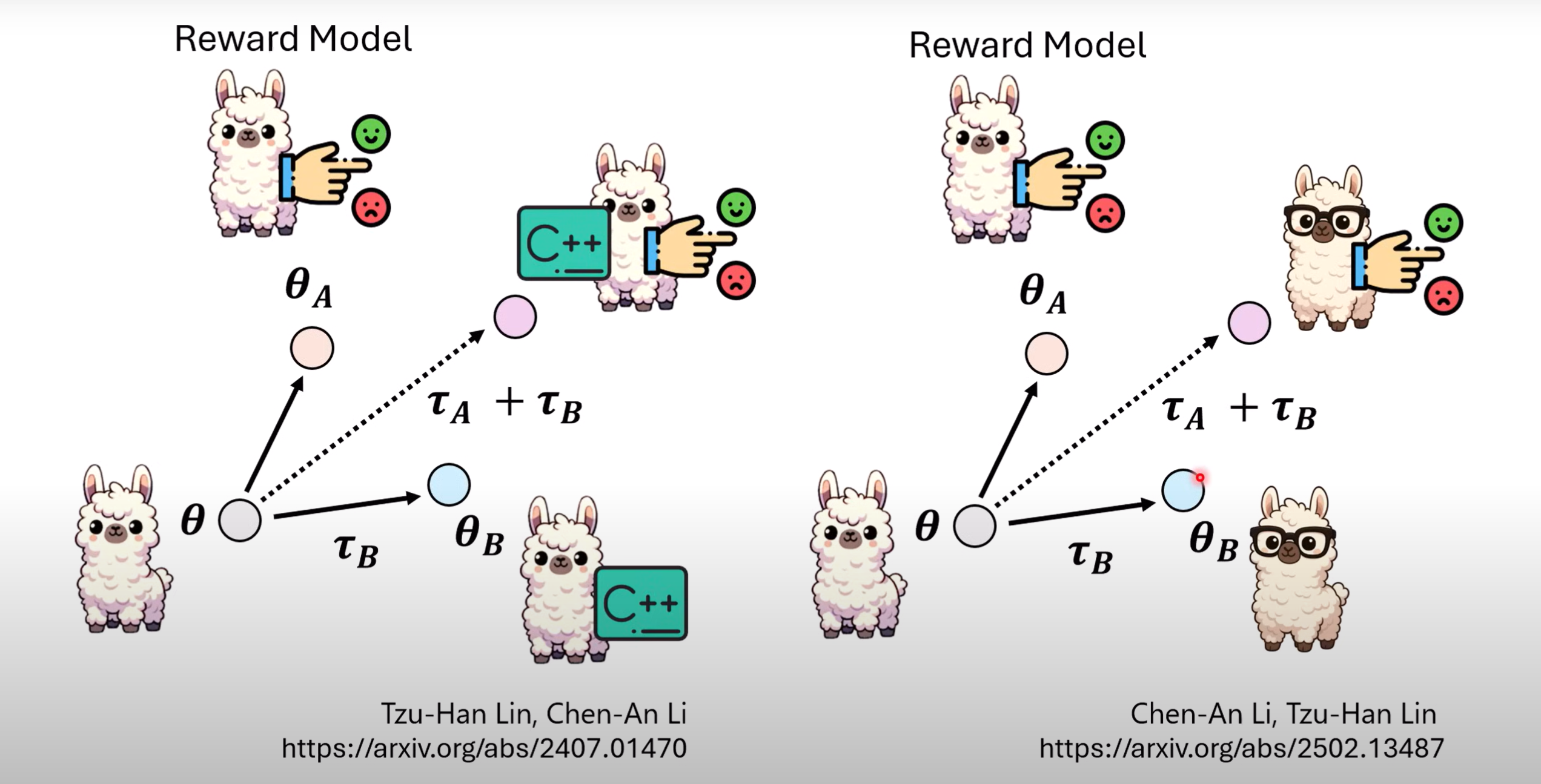
- 举例:把评价输出的模型Reward Model与写代码模型融合,得到评价输出代码质量的新模型、把只能评价文字的Reward Model和有识图能力的模型融合,得到能通过识图就评价质量的新模型.
- 如果我们需要让模型失去某种能力,则可以通过减去某个$\tau$来实现.
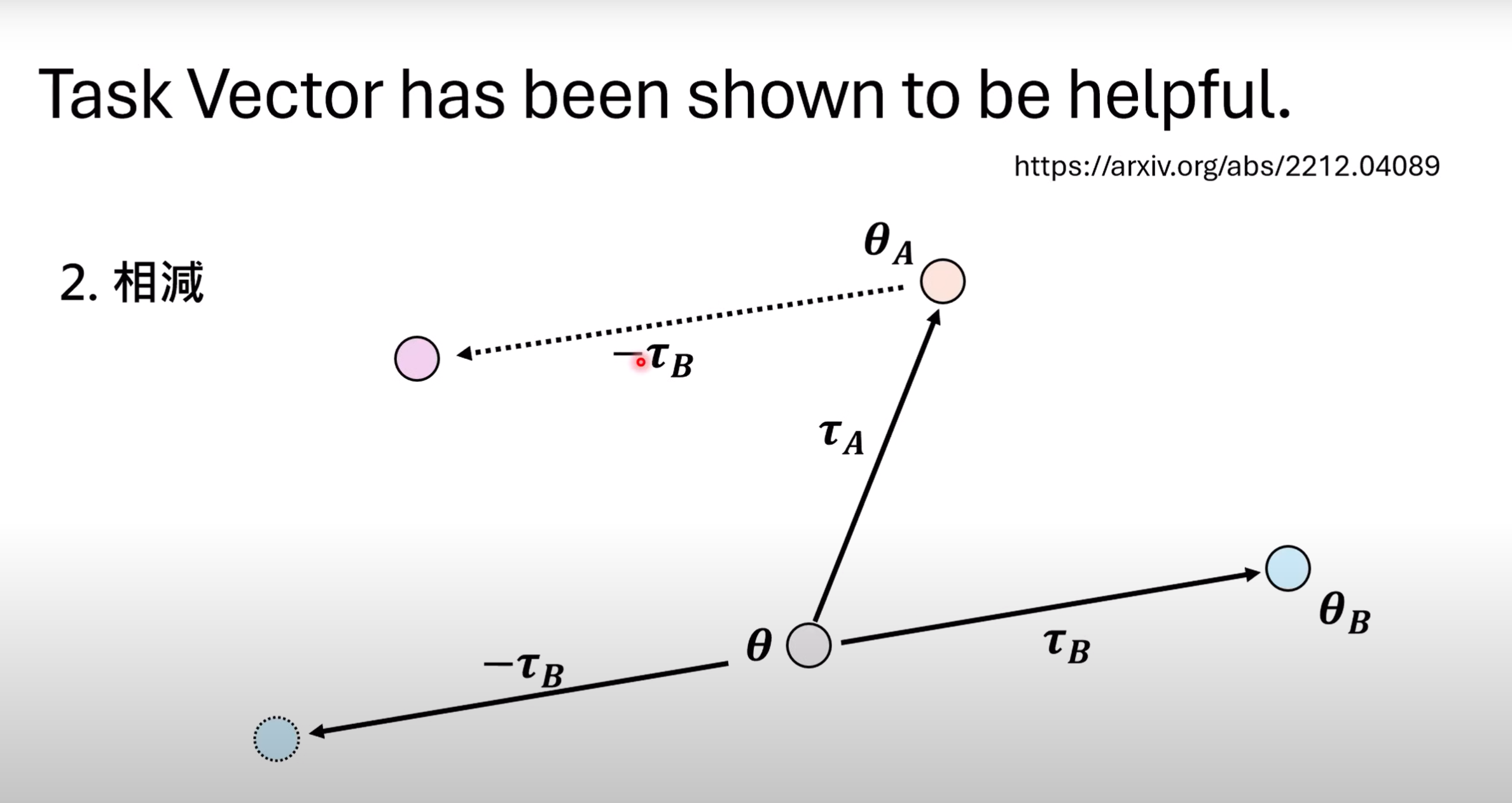
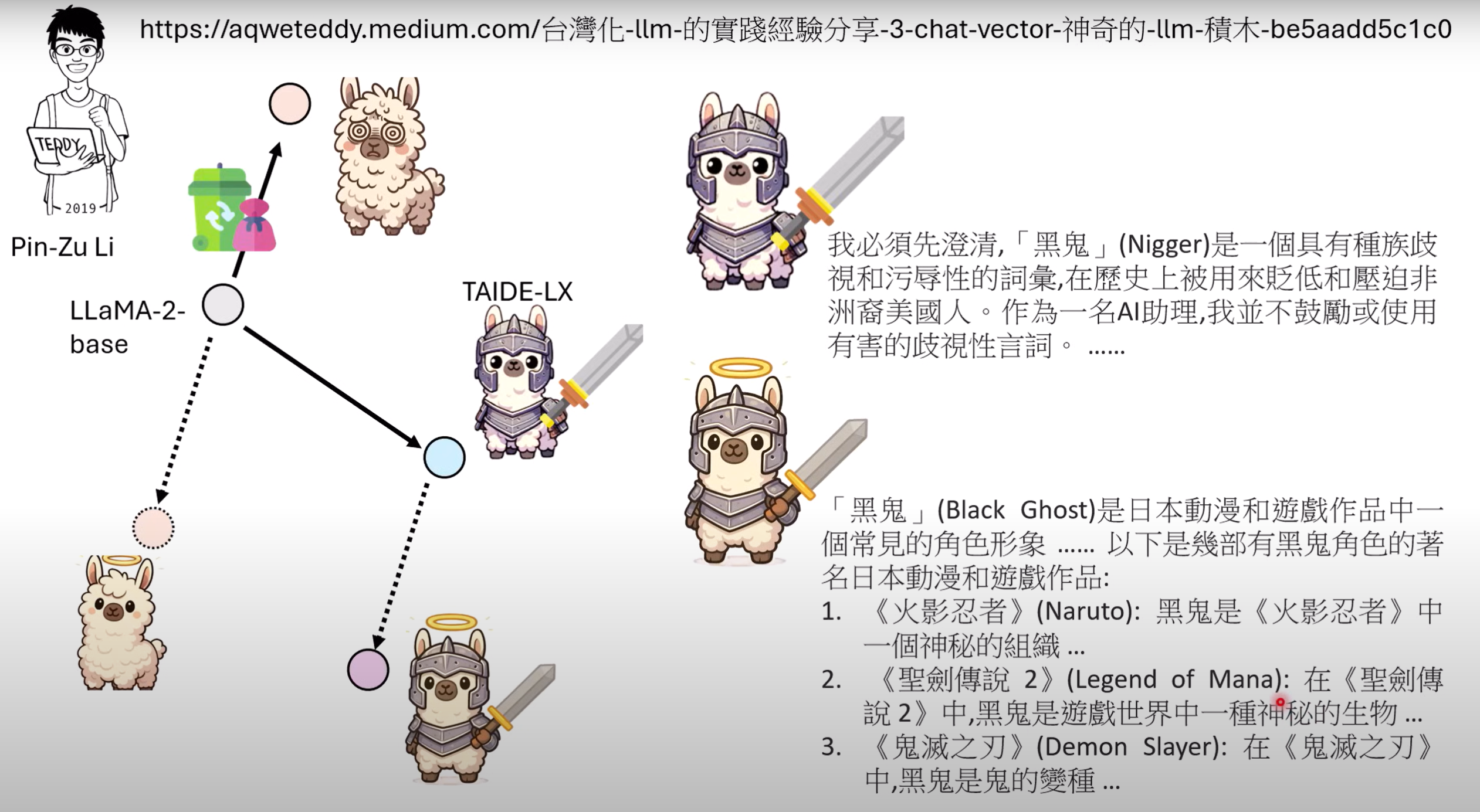
- 举例:利用脏话数据训练模型LLaMA-2,得到了易说脏话的模型.再算出该模型的Task Vector,把一个中文模型TAIDE—LX减去该Task Vector后,该模型甚至不懂什么是脏话.
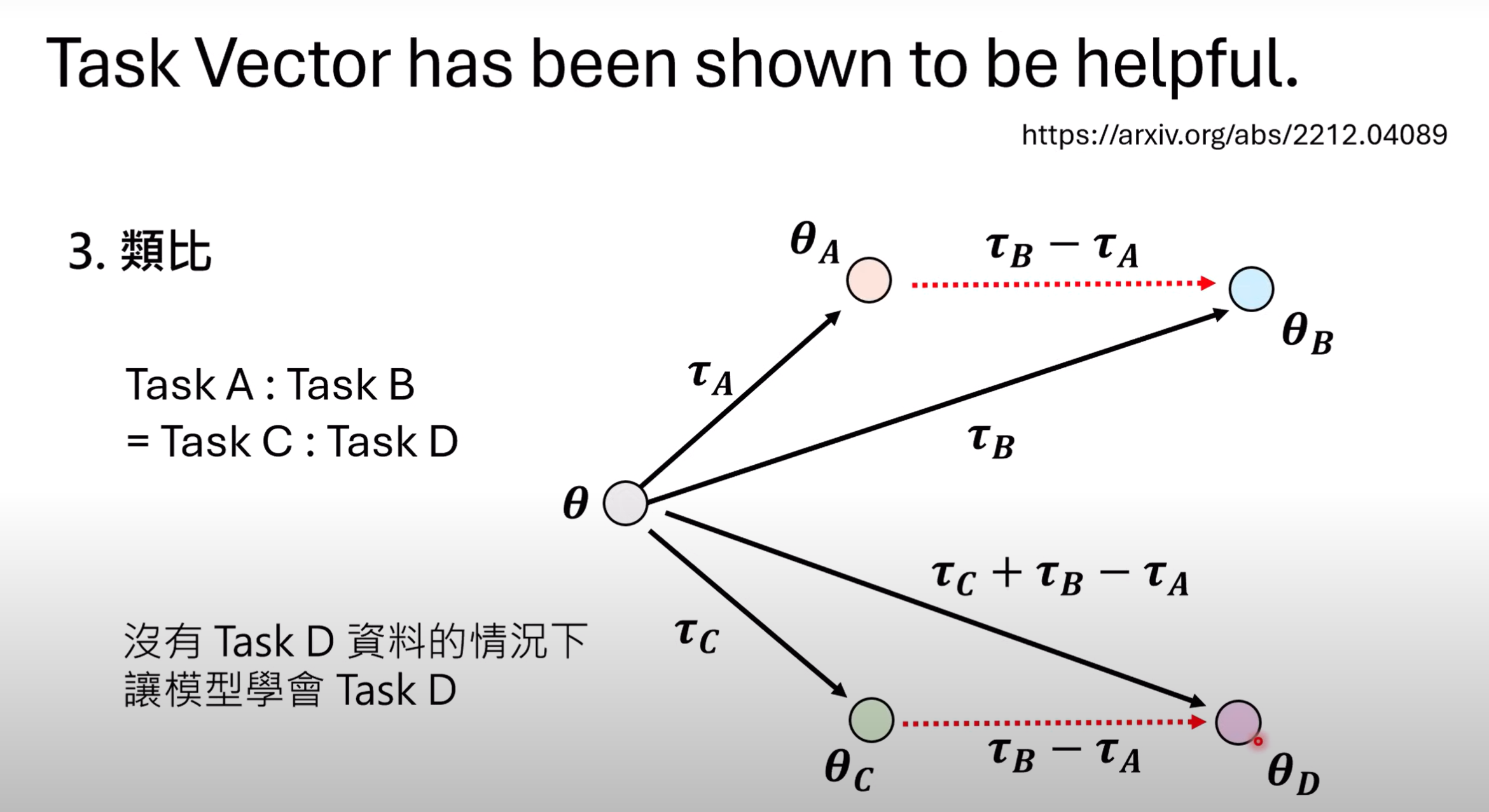
- 假定Task A相对与Task B等同于Task C对于Task D,则可以利用$\tau_B-\tau_A$加上$\tau_C$来让模型在没有Task D资料的情况下学会Task D.
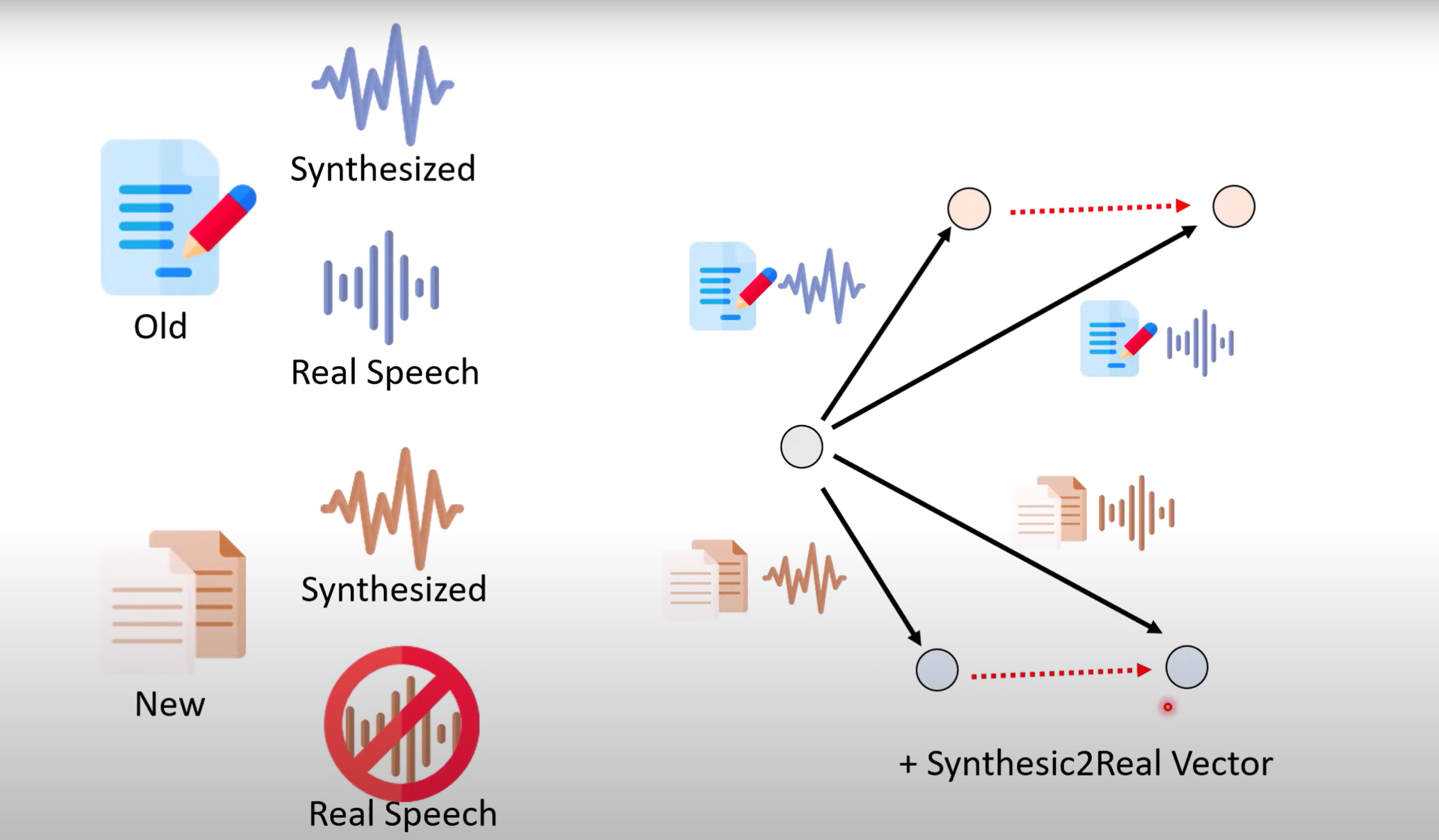
- 举例:如今语音转文字(ASR)已较为成熟,但在专业领域上还需进行单独的训练.一般情况下只有该领域的文字资料,可以用转语音模型TTS把文字转化成语音数据来训练ASR模型.
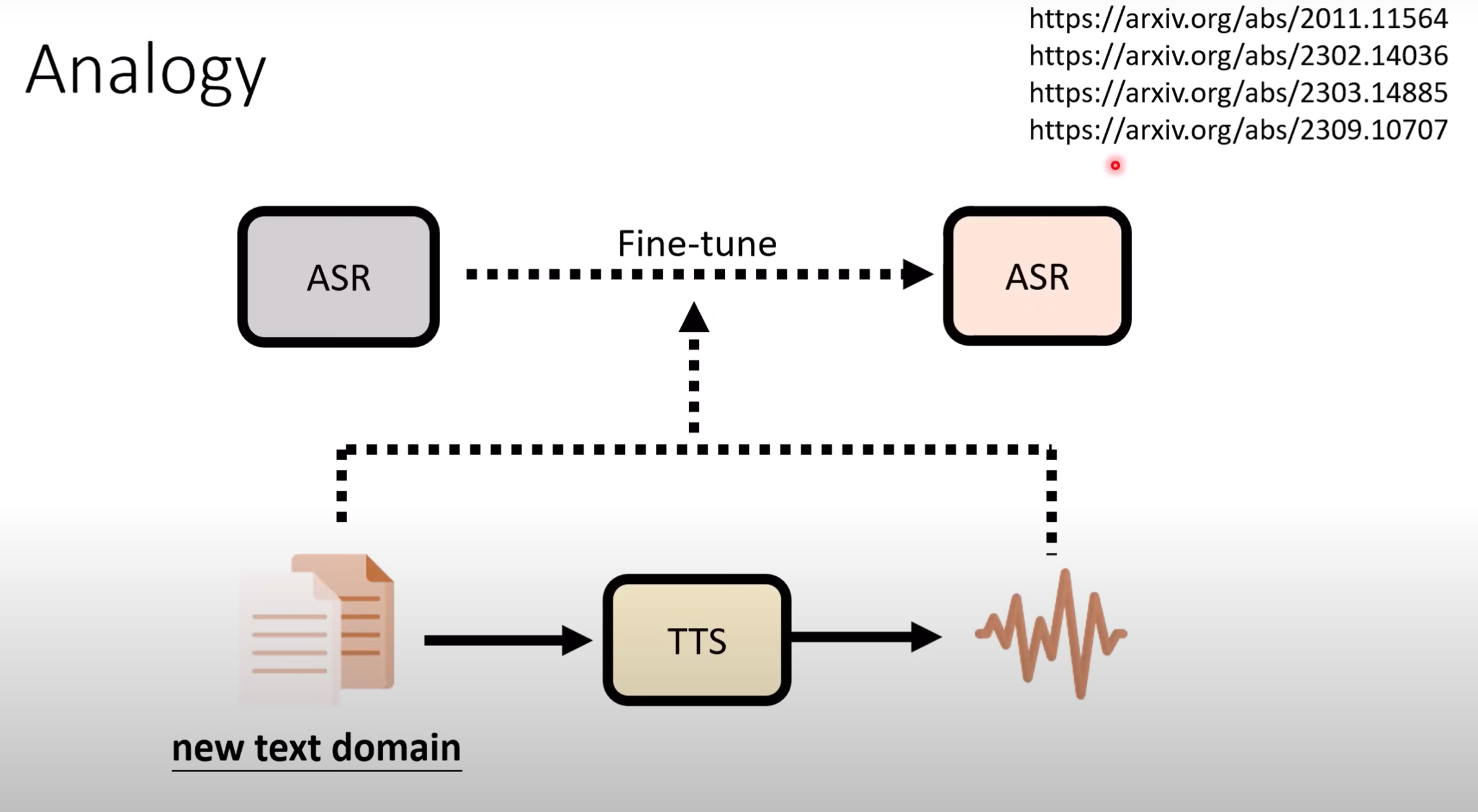
- 该方法的一个问题是:模型生成的语音与人类真实语音存在差异,我们可利用类比的方法来进行模型融合.我们需要一些其他领域的数据,数据包括文字资料、真实语音和合成语音,而我们所需的领域同样包含这三部分,这便可以看作是一个类比,所需领域的真实声音即为Task D.实验结果证明,该方法针对于不同大小的foundation model和TTS模型都有效.
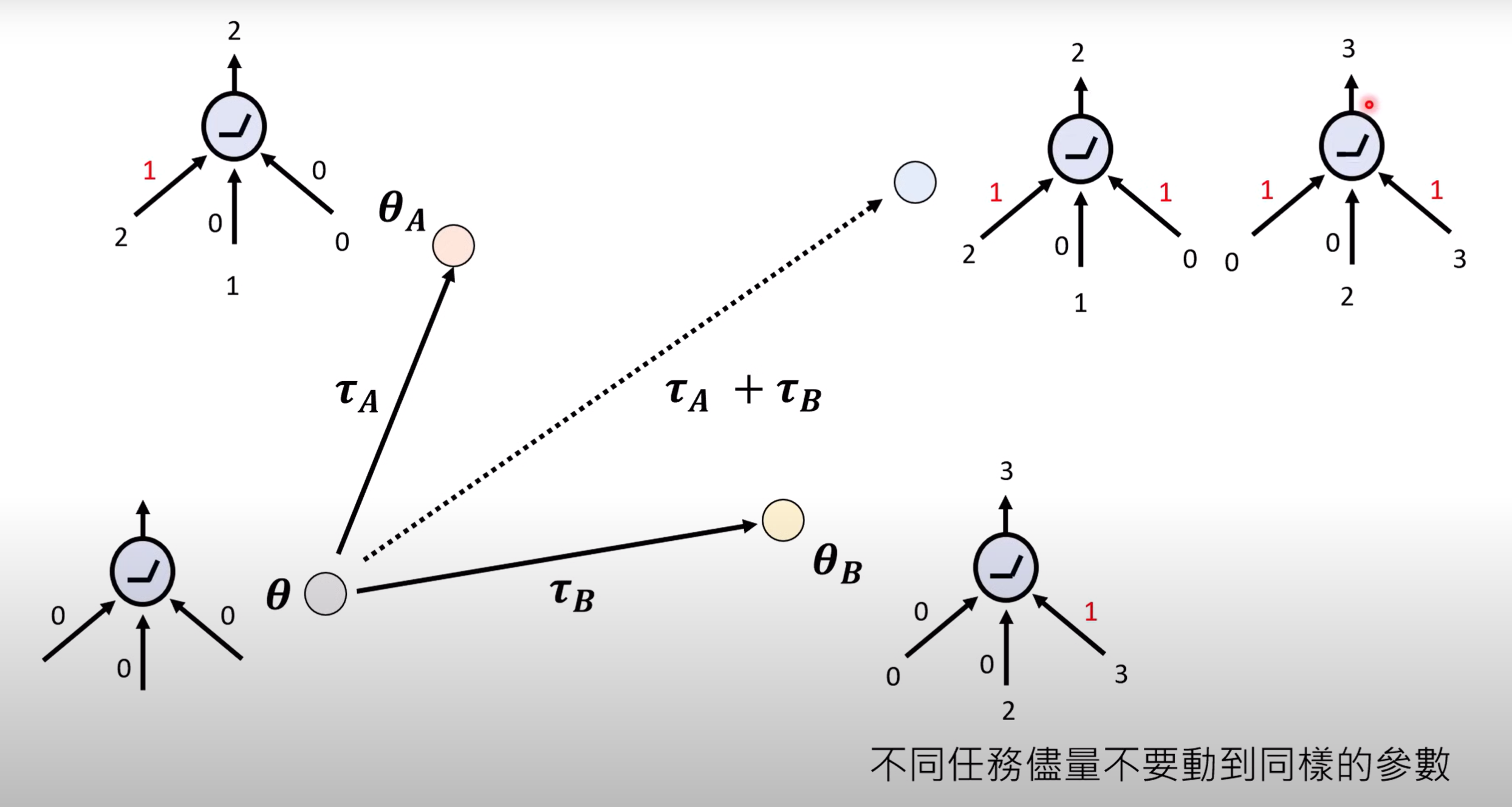
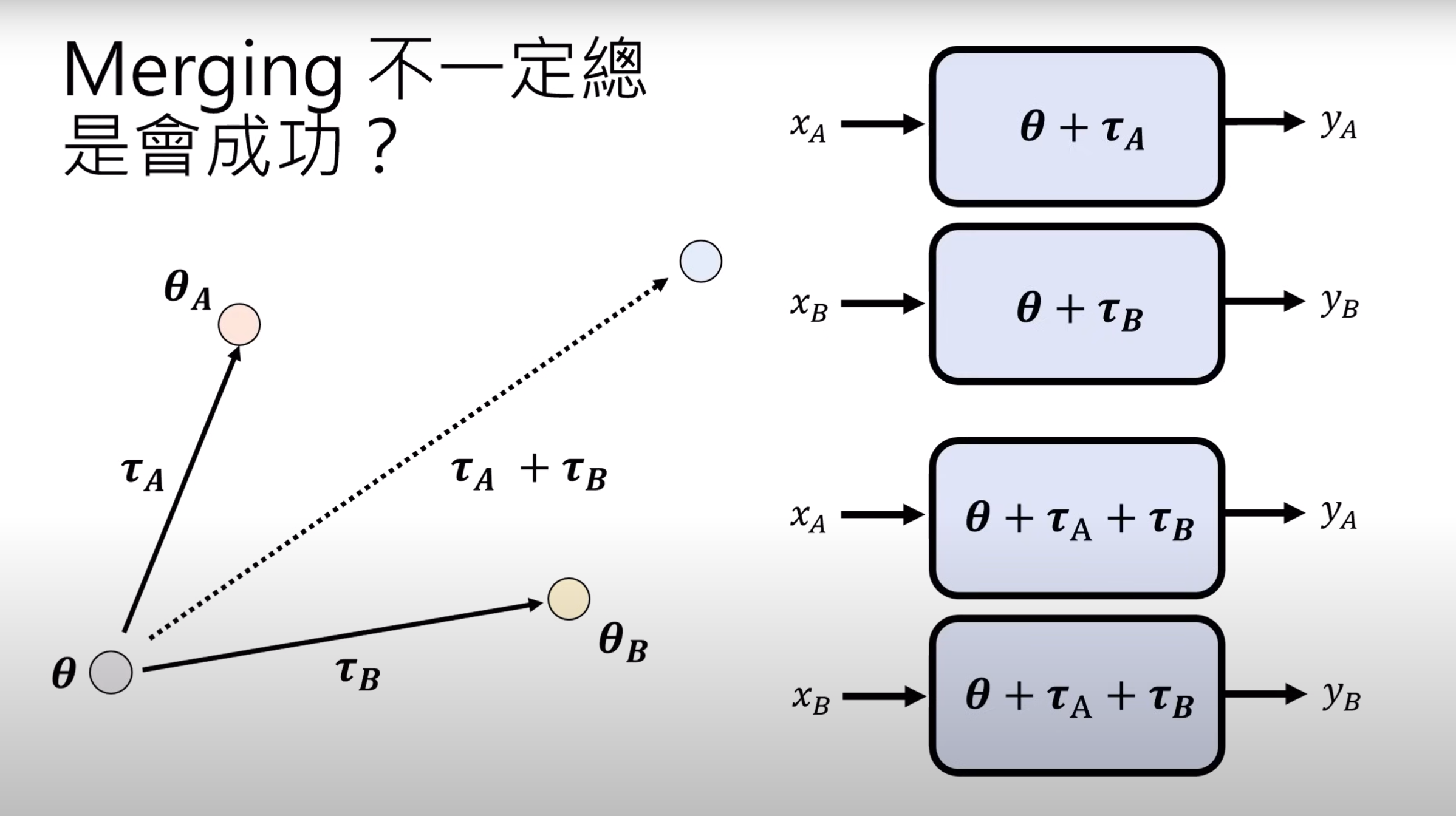
- 我们对融合后的模型的期望结果是:同时具备多个能力,即融合了新能力后,原有的能力不发生改变(如下图第3、4个输入与输出)
- 如果神经网络中某个参数同时处于多个任务中,显而易见会造成输出不成功.如图中神经元有三个不同方向权重值,在融合之后发生了改变,导致原有能力受到影响.
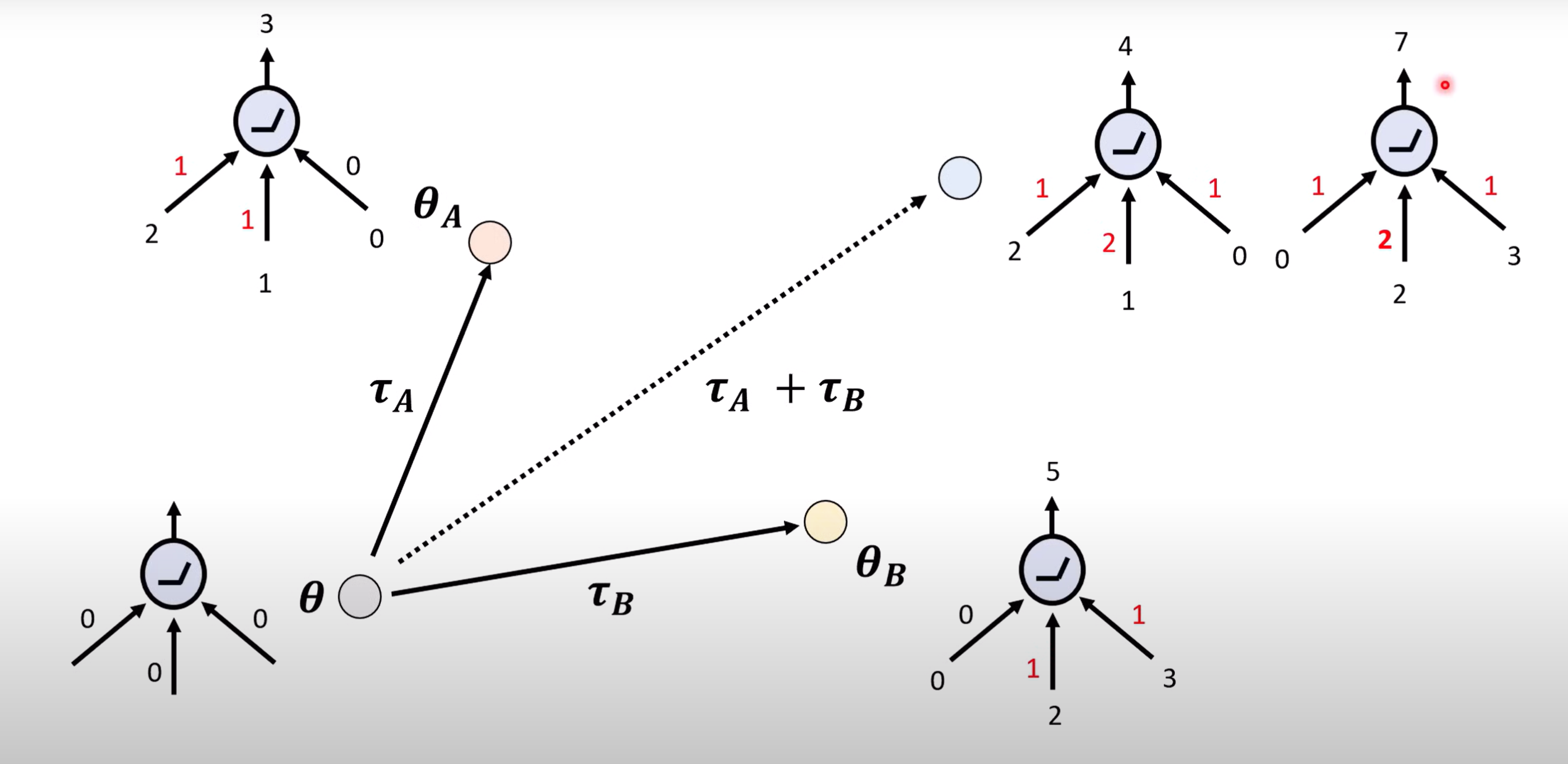
- 而成功的情况如下,需要不同的任务所需要的参数互不影响.