- 当今深度思考语言模型(如ChatGPT o1/o3/o4、DeepSeek R1、Gemini 2、Claude 3.7 Sonnet)等,在给定输入问题时,除了给出答案,还会有一段推理(
Reasoning)的过程,包括验证答案(Verification)、探索其他可能(Explore)、规划(Planning)
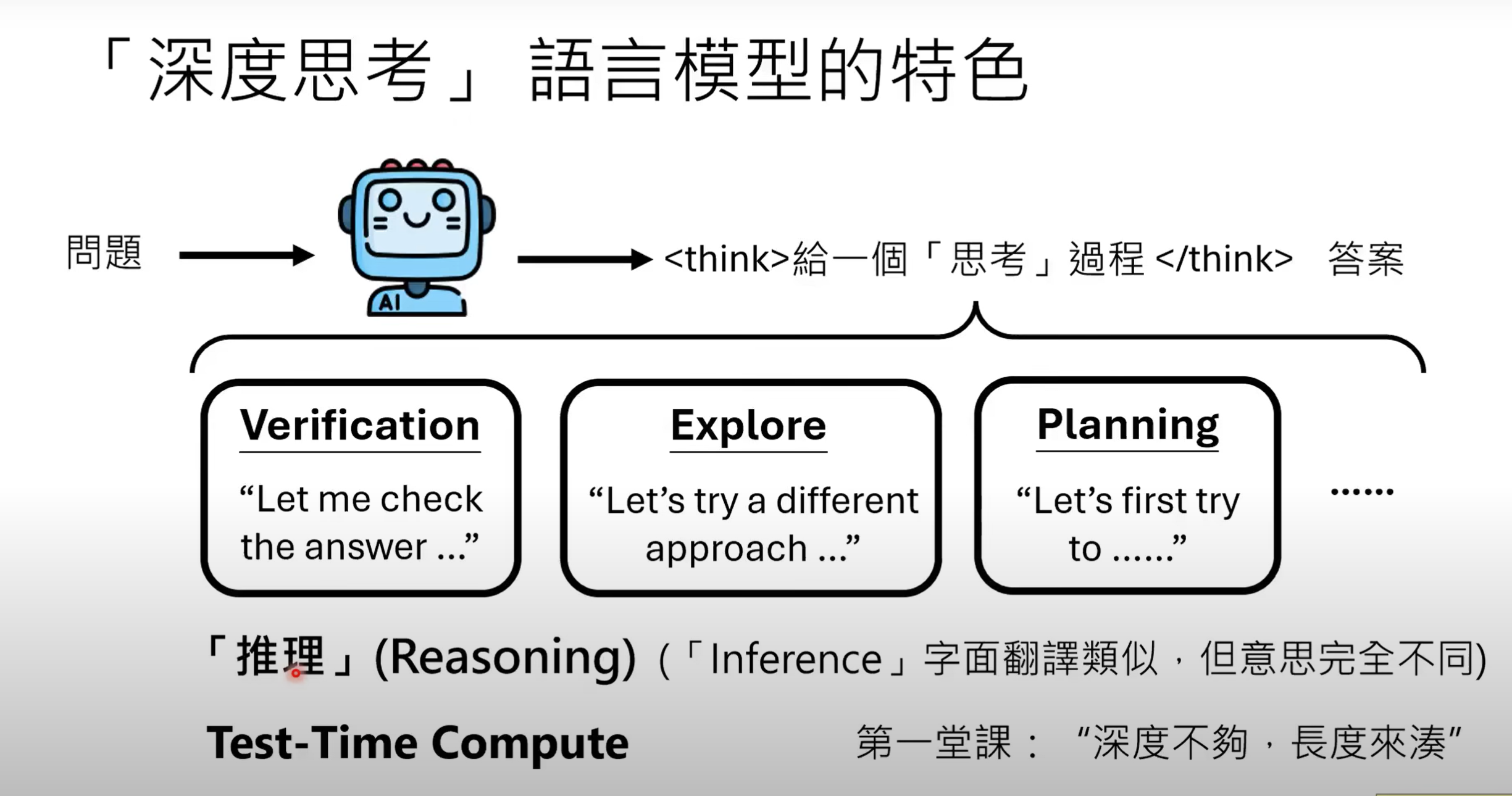
本堂课介绍四种方法:其中前两种不需微调参数,后两种需要.
有两种达到CoT的方式:
- 1.
Few-shot Cot:即给模型解题范例,再问问题 - 2.
Zero-shot Cot: 不给模型范例,直接要求一步步输出答案 如今深度思考模型在做的事与CoT类似,称作Long CoT,以上两种统称为Short CoT.

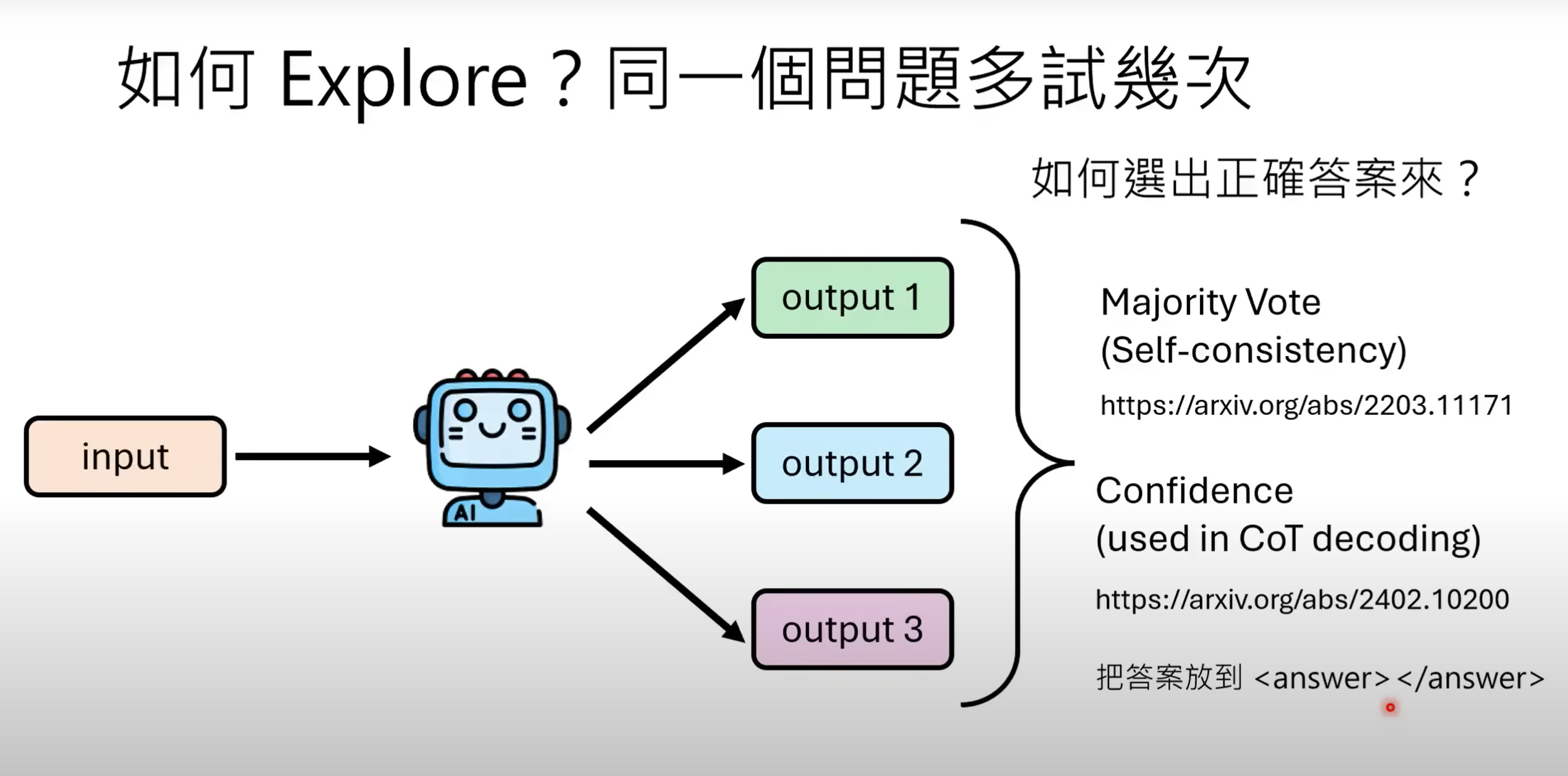
- 对于较强模型,同一个问题只要增加模型尝试次数,其产生过正确答案的几率便会上升.

- 因而,可以要求模型提供多个输出,并通过
Majority Vote(多数决策)或Confidence(置信度计算)的方法选出正确答案 -
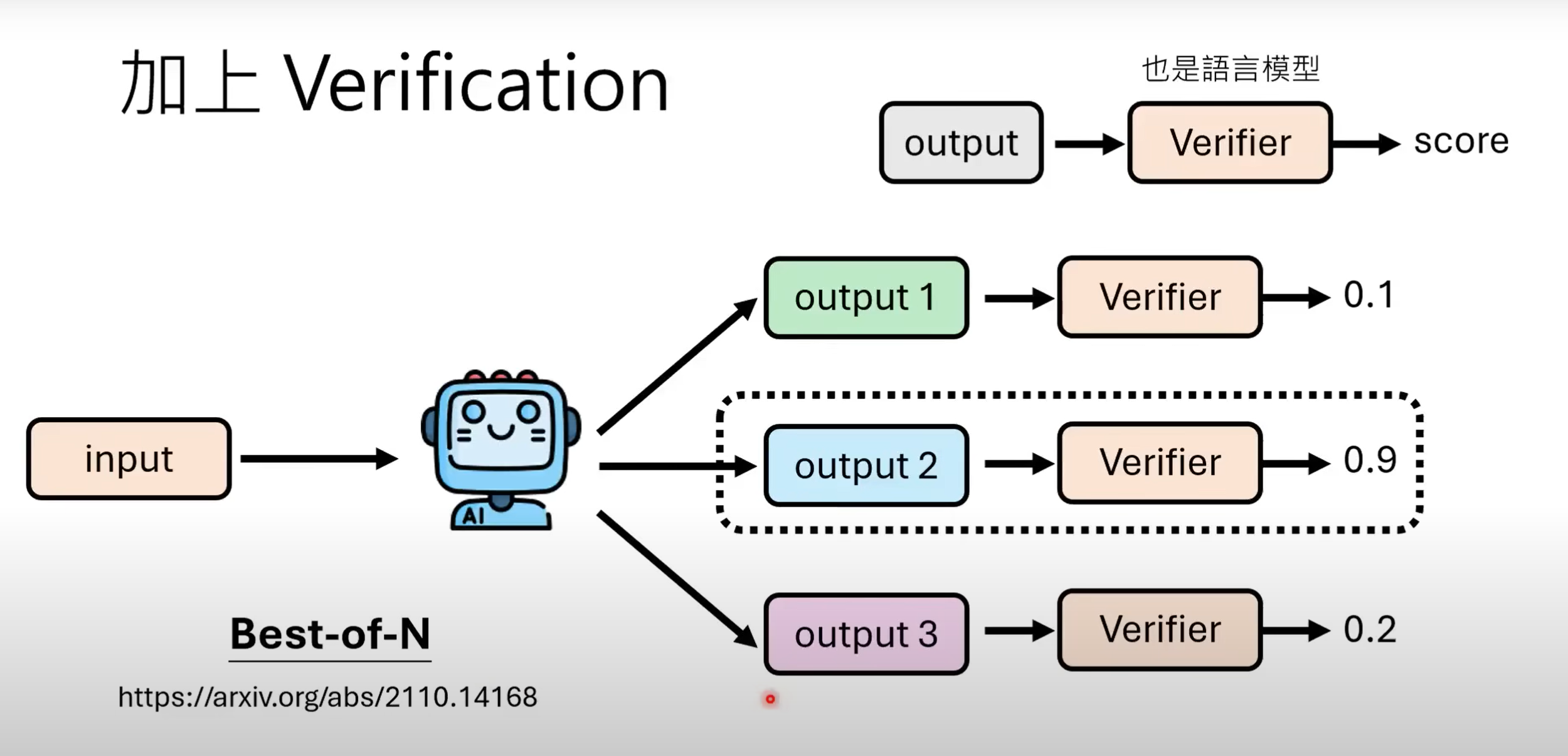
- 还可以通过
Best-of-N方法:即训练一个同为语言模型作为Varifier来验证答案.
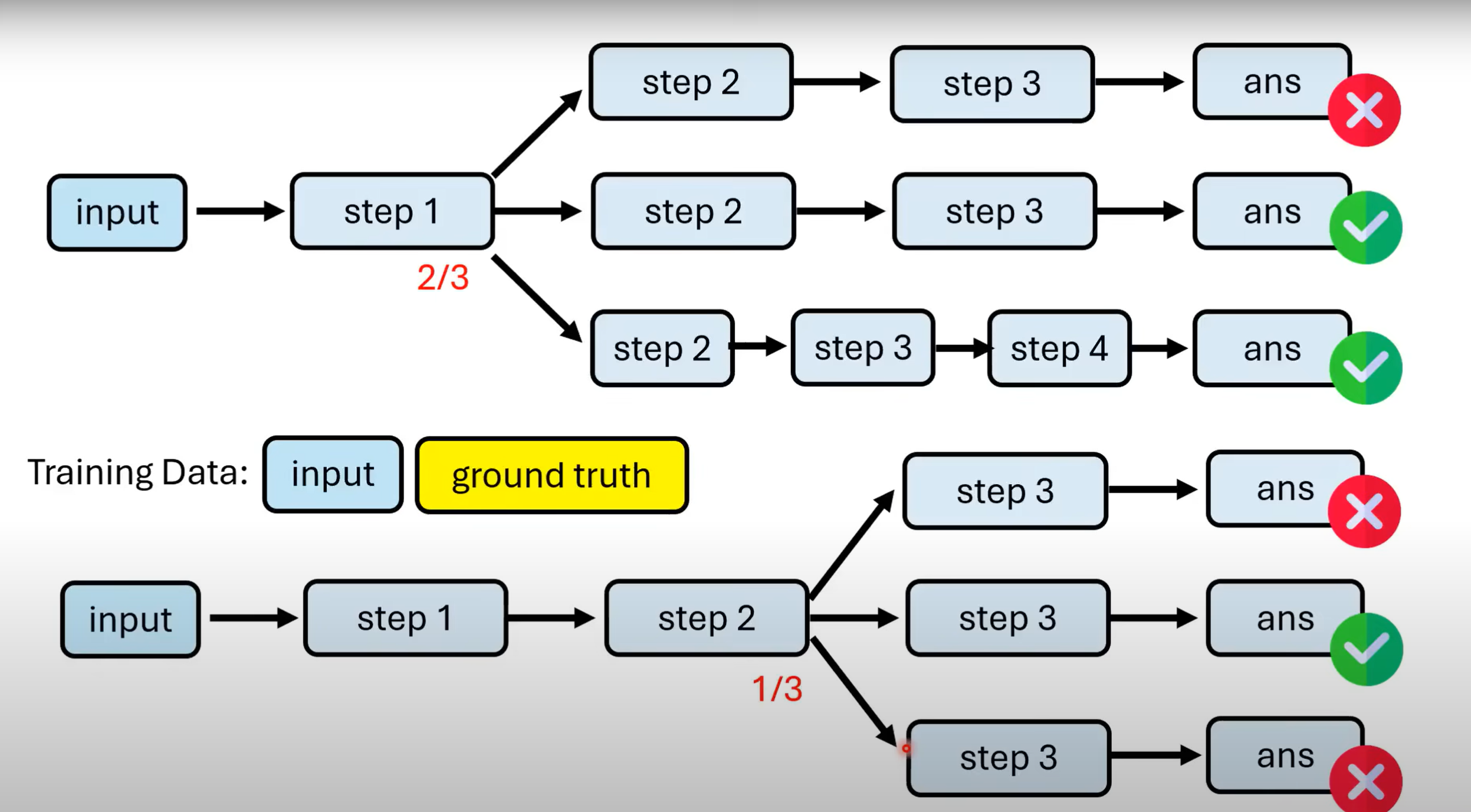
- 但只对结果进行验证效率过低,我们希望在推理中间过程便能进行验证.可以使用
Process Verifier,要求模型不直接给输出,而是依次给出步骤,经过验证通过后再继续产生下去. 对于一般训练资料,我们只拥有问题与答案,不一定能判断出步骤是否准确.那如何得到一个Process Verifier呢? - 对于能输出正确答案的每一个step,我们都让其往下输出多条路径,用古典概型的方法估算该step的正确率.再把对应step交给Process Verifier进行学习.
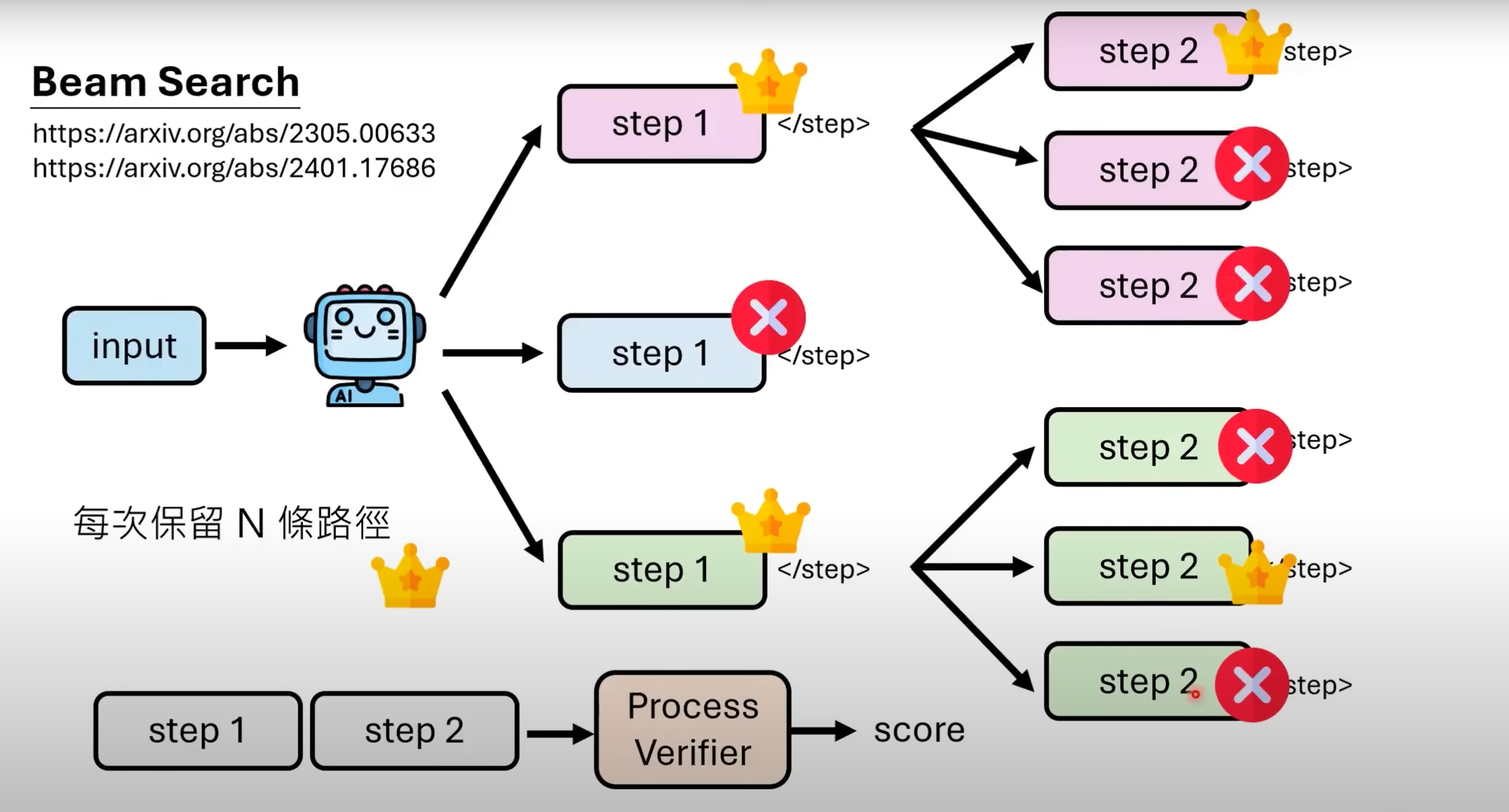
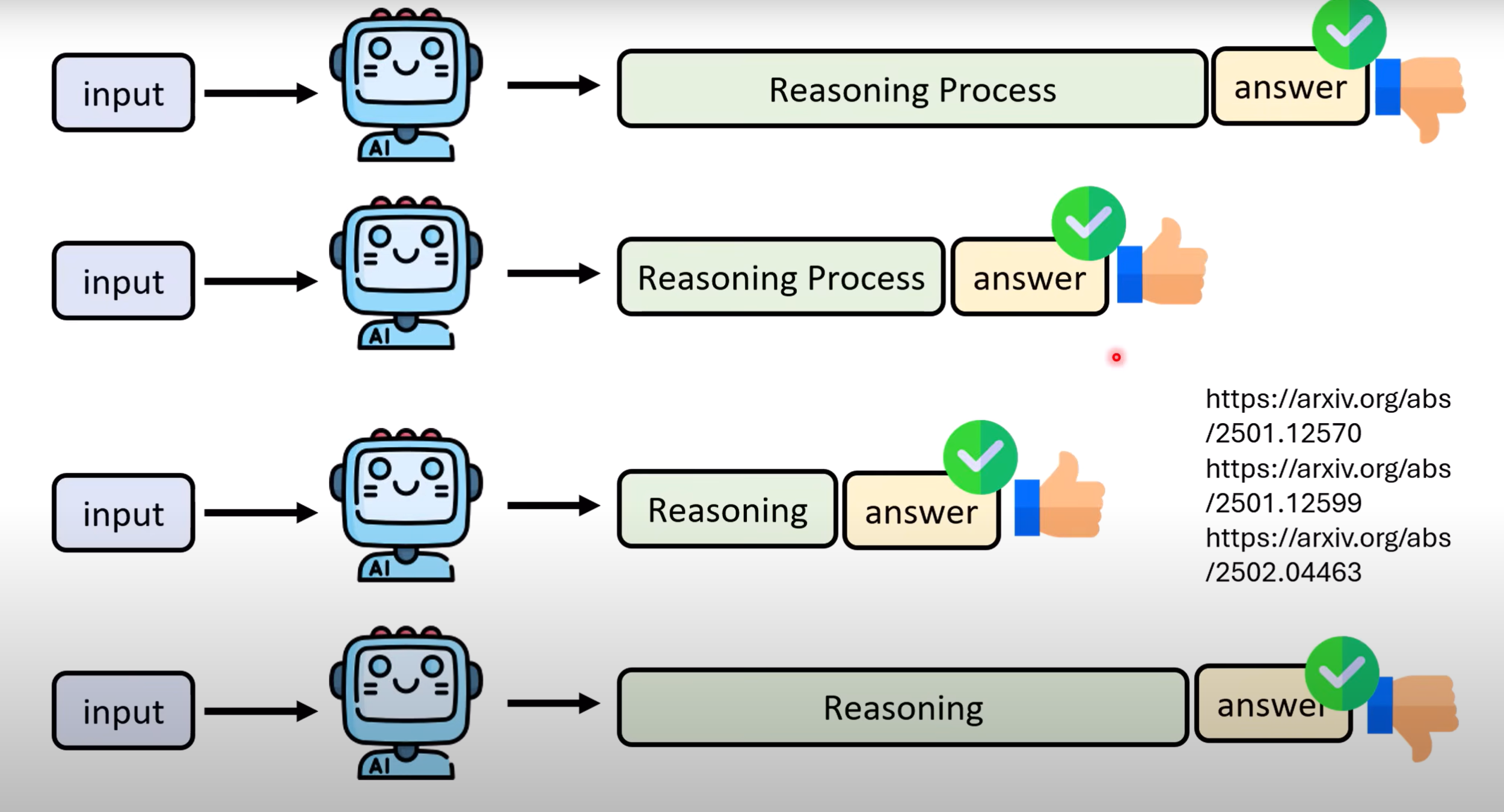
- 该方法本质如图所示,通过在训练资料加入
Reasoning的内容来让模型学习.
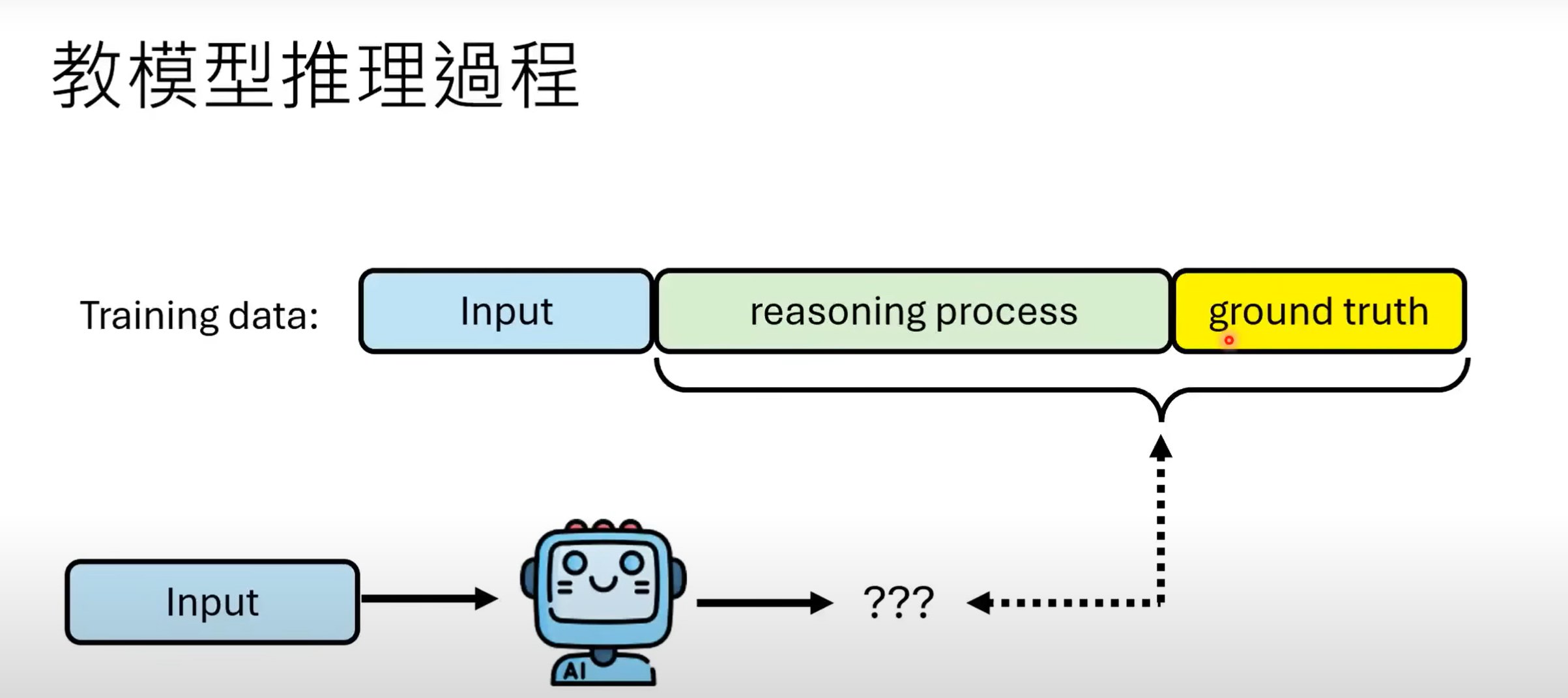
- 而难点在于,如何获取reasoning process的资料.人为标注费时费力,可以采取让其他语言模型输出CoT,把答案正确的reasoning process纳入训练资料. 但显而易见的弊端是:答案正确,过程不一定正确.因而我们应结合上述提到过的树状搜寻的方法,对step进行展开,用process verifier逐步验证,这样得到的reasoning process正确率才有一定可信度.
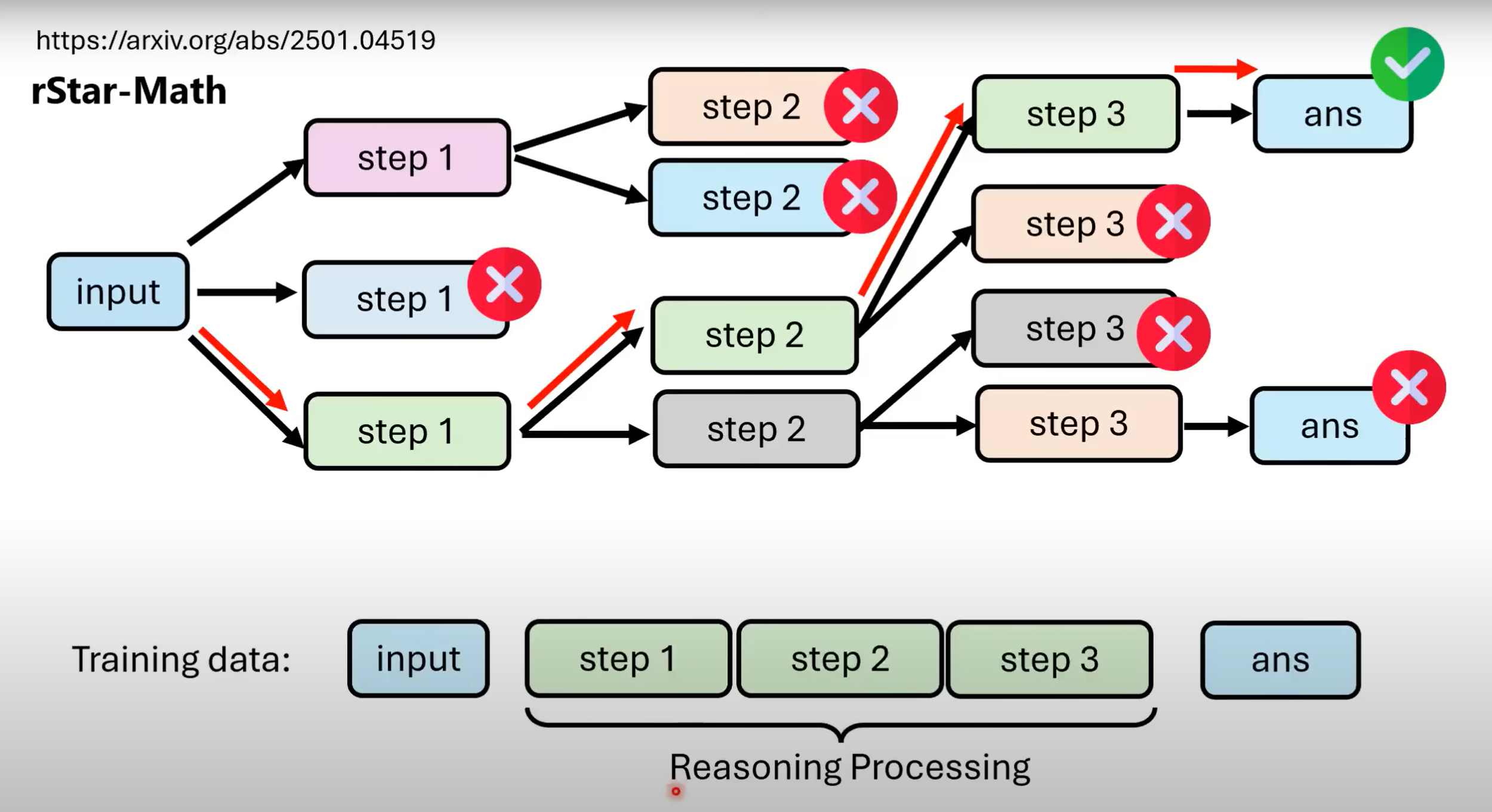
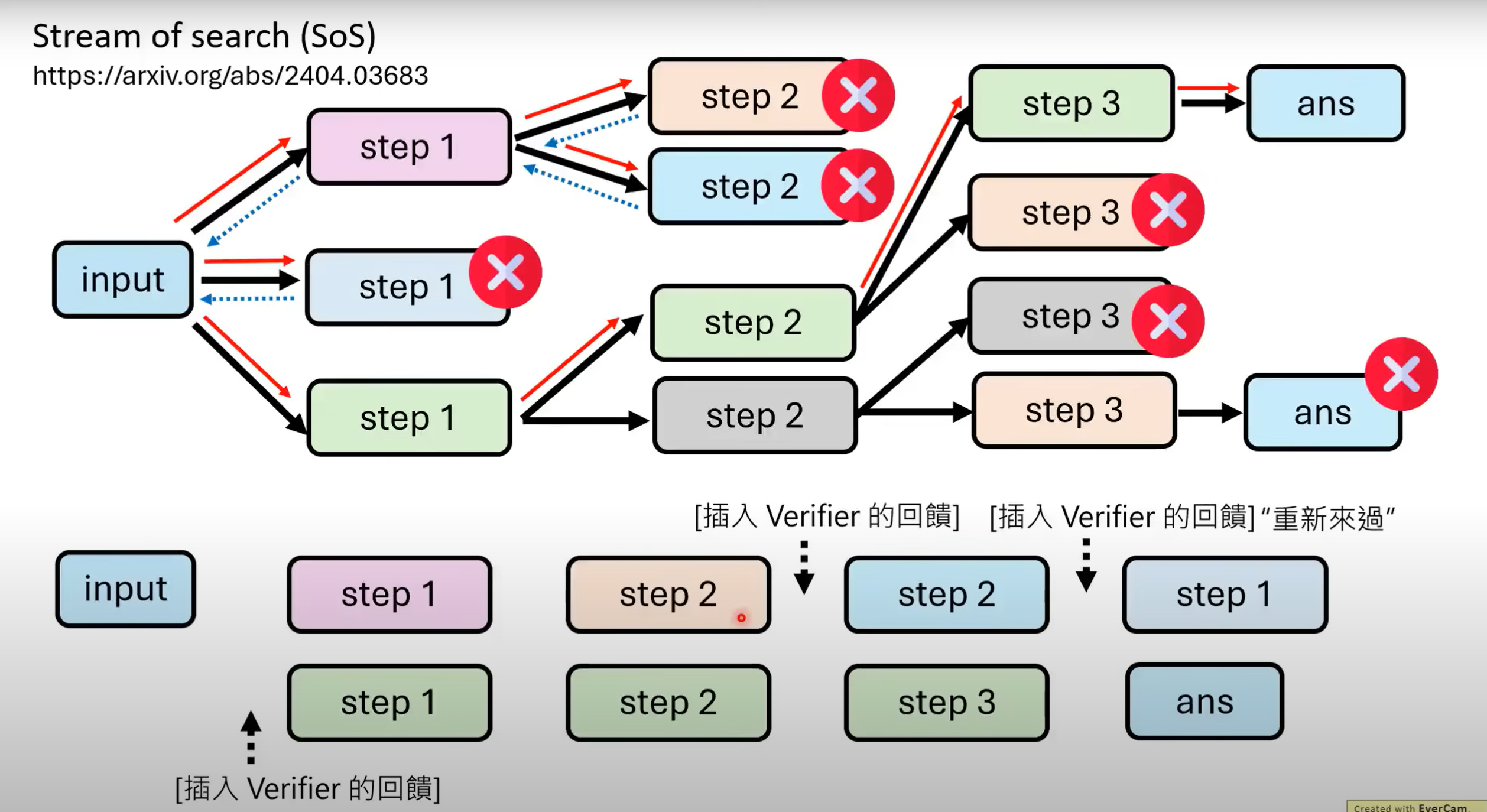
- 如果只给模型正确的过程与结果,模型便会认为不论如何,其推理过程一定是正确的.在推论出错情况下,其无法找出其自身的问题,会“一步错步步错”
- 解决方法:可以在训练资料中通过深搜,加进一些错误的搜索过程. 在遇到认为是错误步骤时,让模型能够回溯到上一步骤,继续尝试另一路径(可插入Verifier回馈,加入连词等让推理过程看起来顺畅而不跳跃)
- 与第三种方法不同,RL更侧重结果,几乎根据最终答案来进行训练:
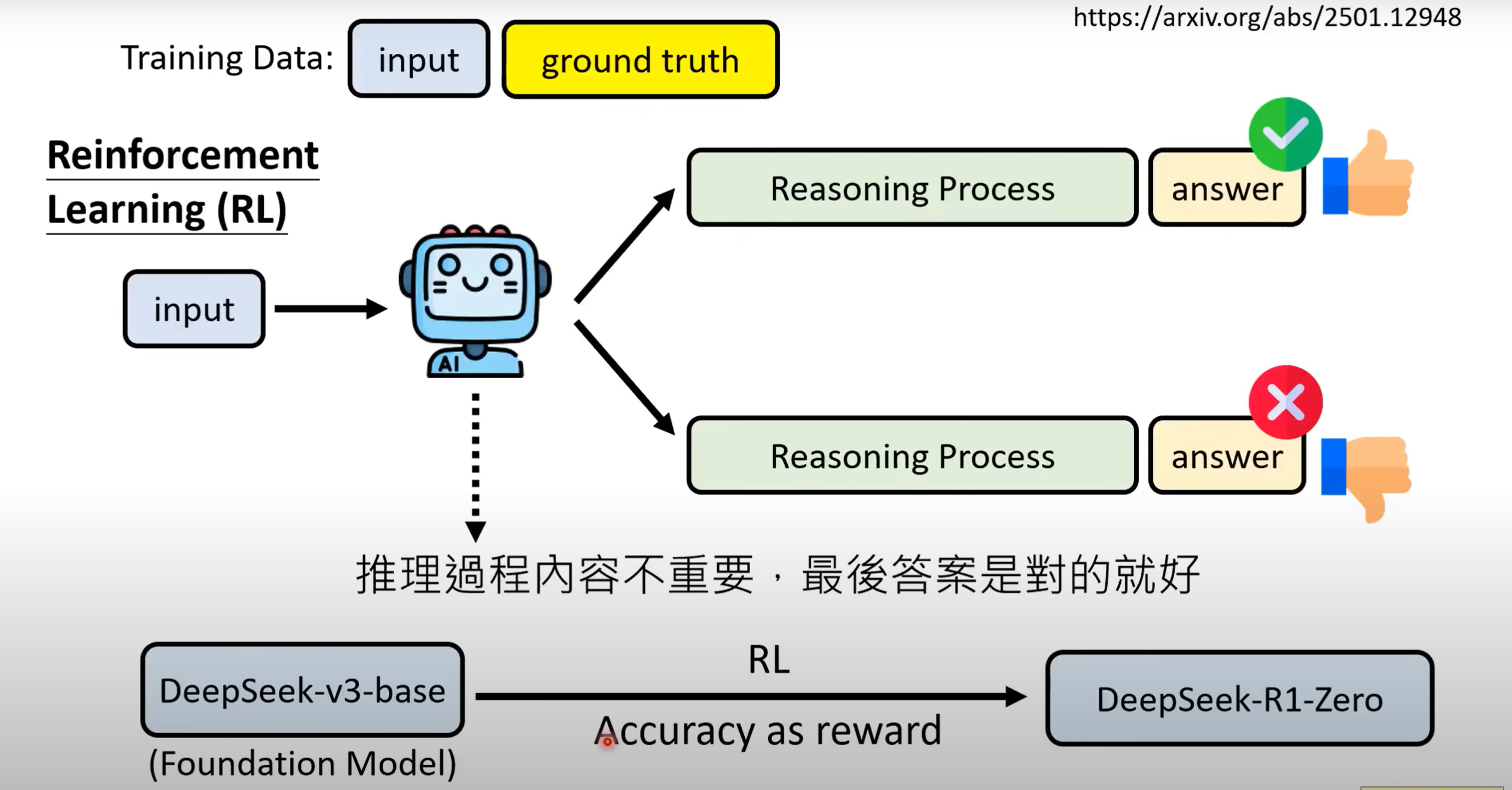
- Base模型经过RL后得到能产生Reasoning的R1-Zero模型,但其Reasoning过程难以理解,需经过人工转化. 将转化后的资料以及小部分通过Few-shot CoT和Supervised CoT获得的资料对Base模型进行Imitation Learning得到Model A,再经过RL得到具备初步Reasoning能力的Model B.
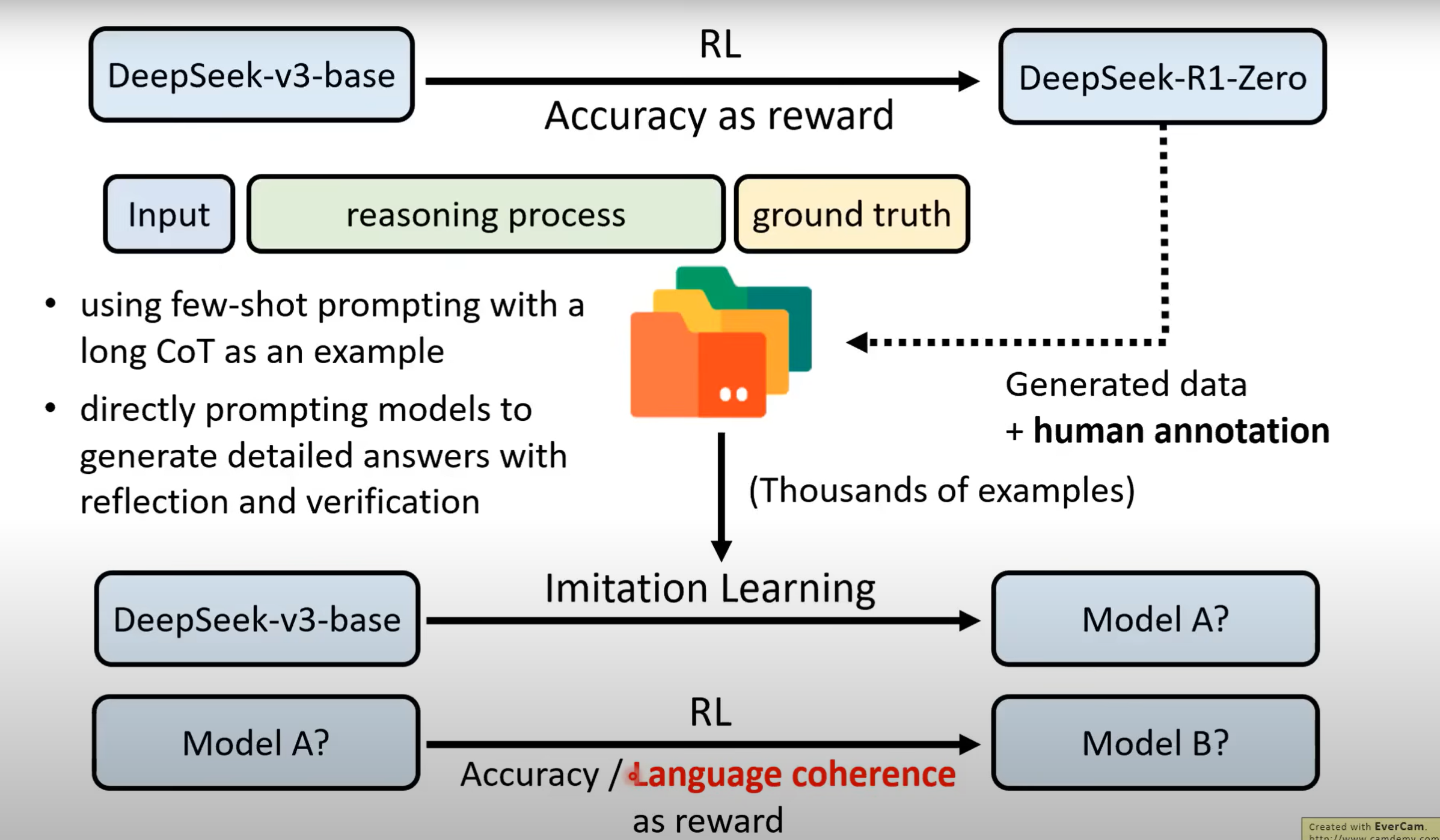
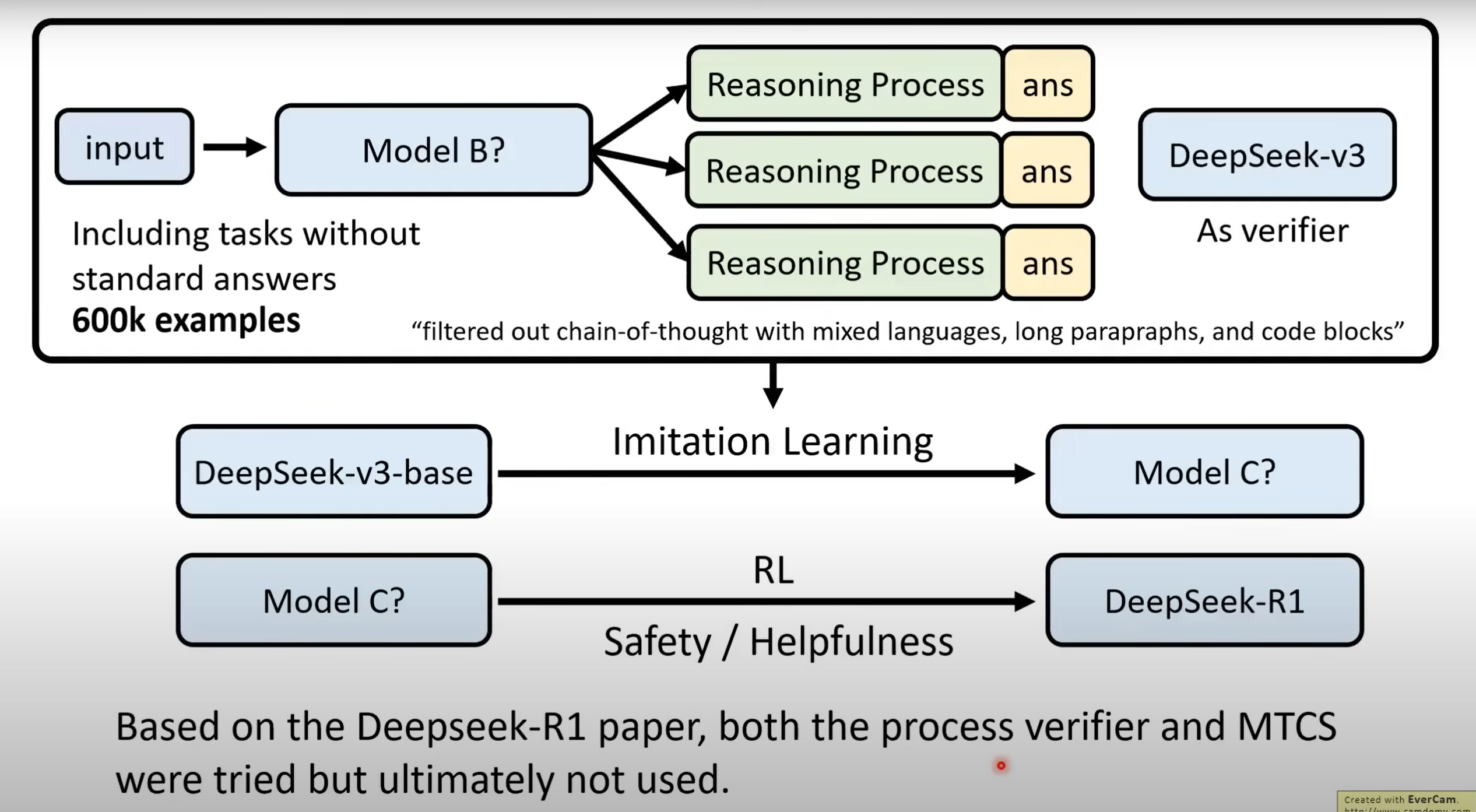
- 其次,利用DeepSeek-v3作为Verifier,让Model B生成60万笔资料(其中加入一些v3 Self-output的资料),利用这些资料对Base模型进行Imitation Learning得到Model C,再对Model C进行RL便得到了DeepSeek-R1.
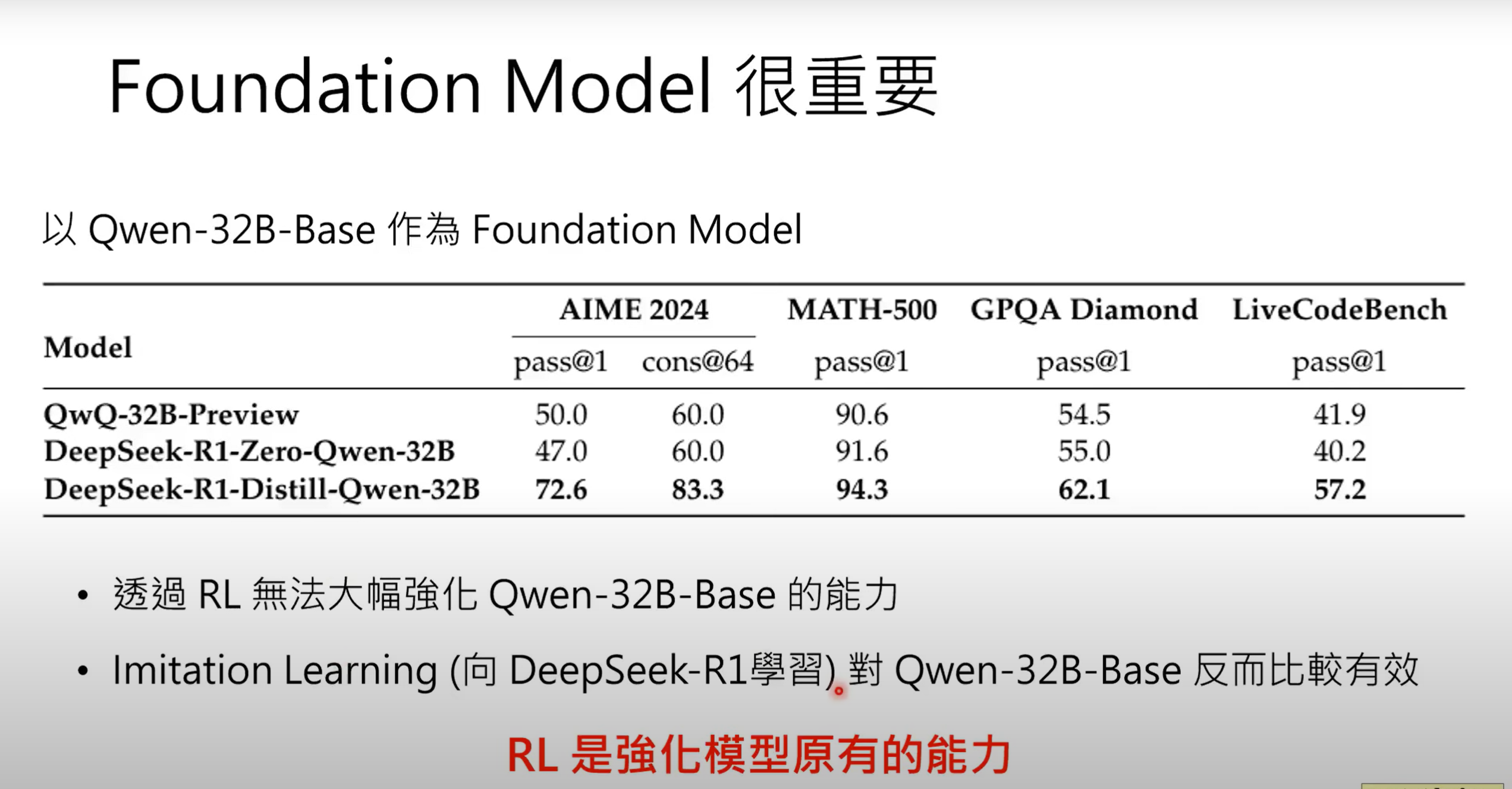
- RL本质是强化一个模型原有的能力,较弱模型不适用RL
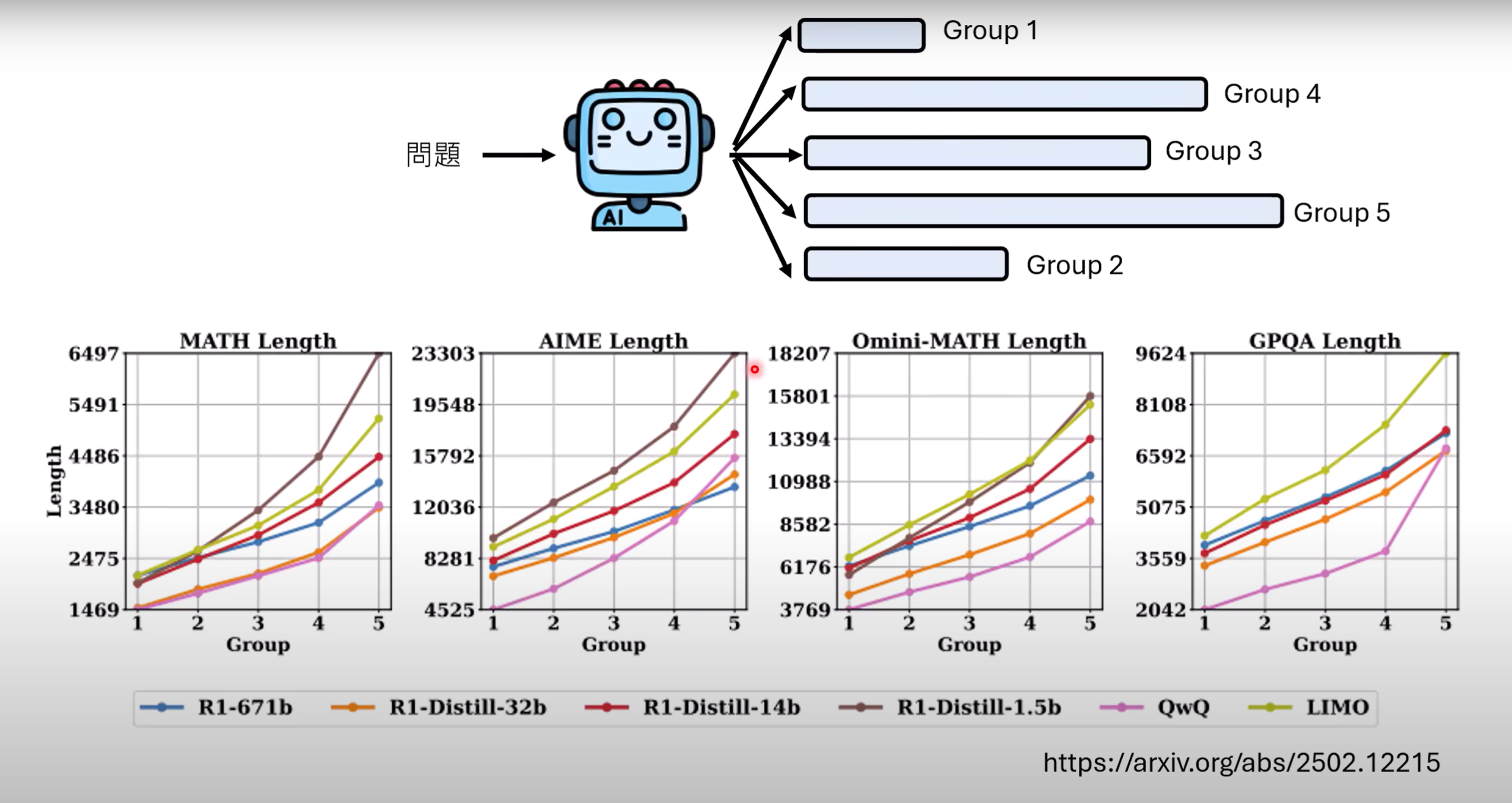
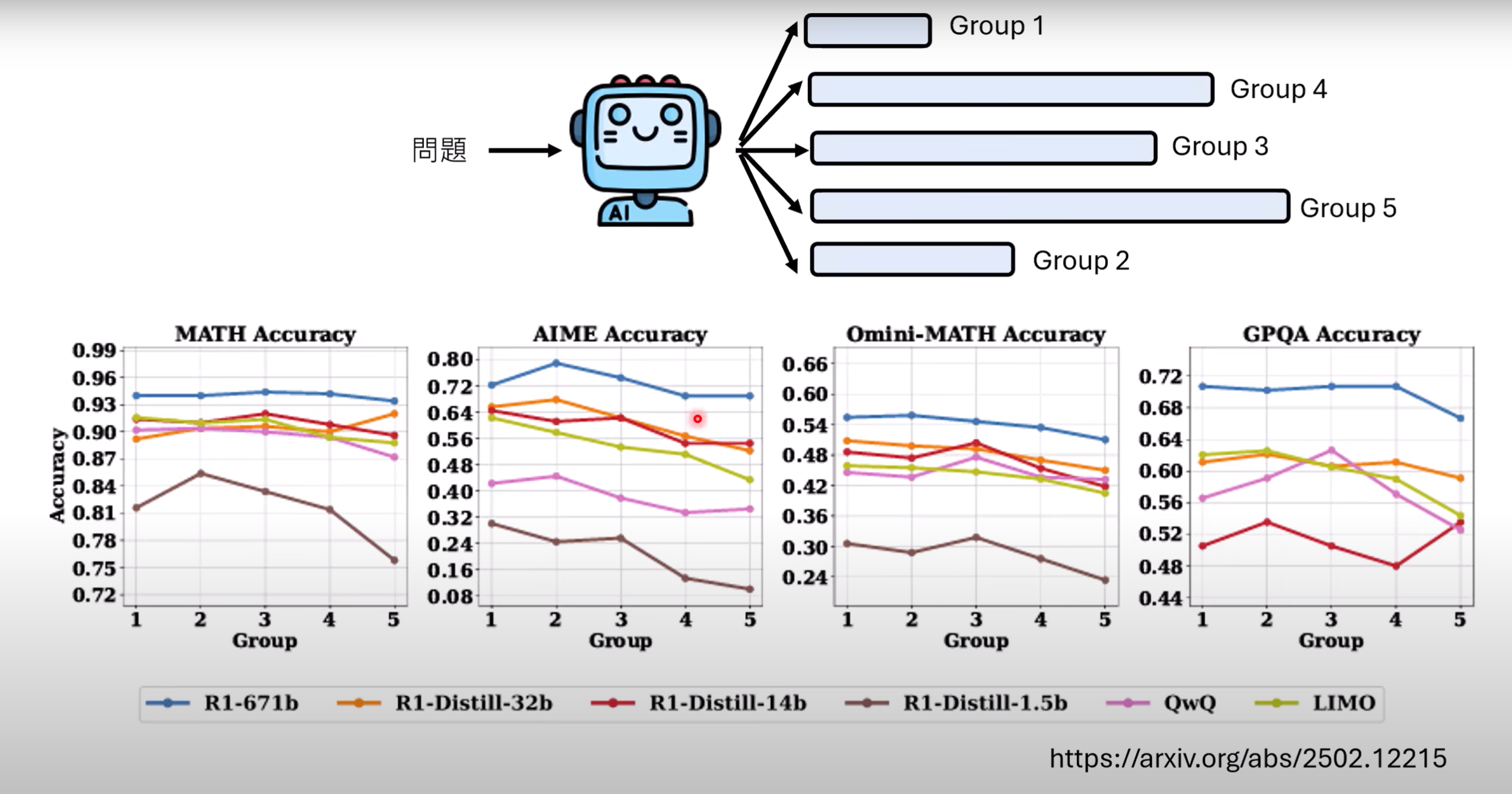
- 依据问题长度,将问题分为5组,将问题交给具有推理能力的语言模型,如图所示,越长的问题,回答长度也越长,但答案的正确率却没有因此变高. 因此,模型“想太多”不是一件好事,会耗费额外算力.
- 区别于让模型直接给出答案(Stander)和让模型给出Chain-of-Tought,Chain-of-Draft让模型逐步思考,但通过限制输出上限让其输出类似草稿. 实验证明,CoD大多情况能比直接输出答案正确率更高.

可以通过控制sample数目或者缩小beam search范围、缩小展开的树状结构等方法简化工作流程.
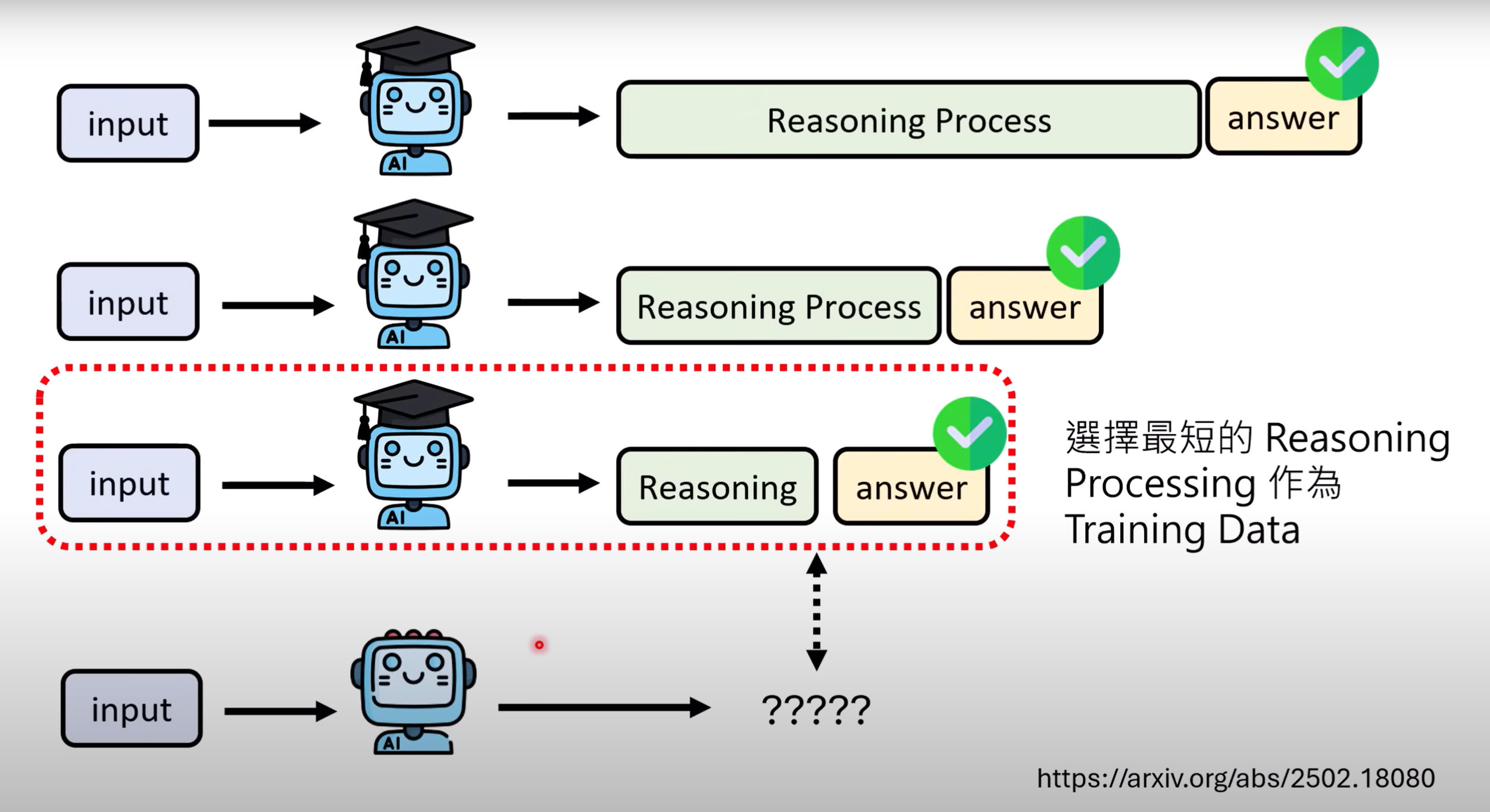
- 将同一个问题问具备推理能力的教师模型多次,在回答正确的情况下选取最短的reasoning process作为训练资料.
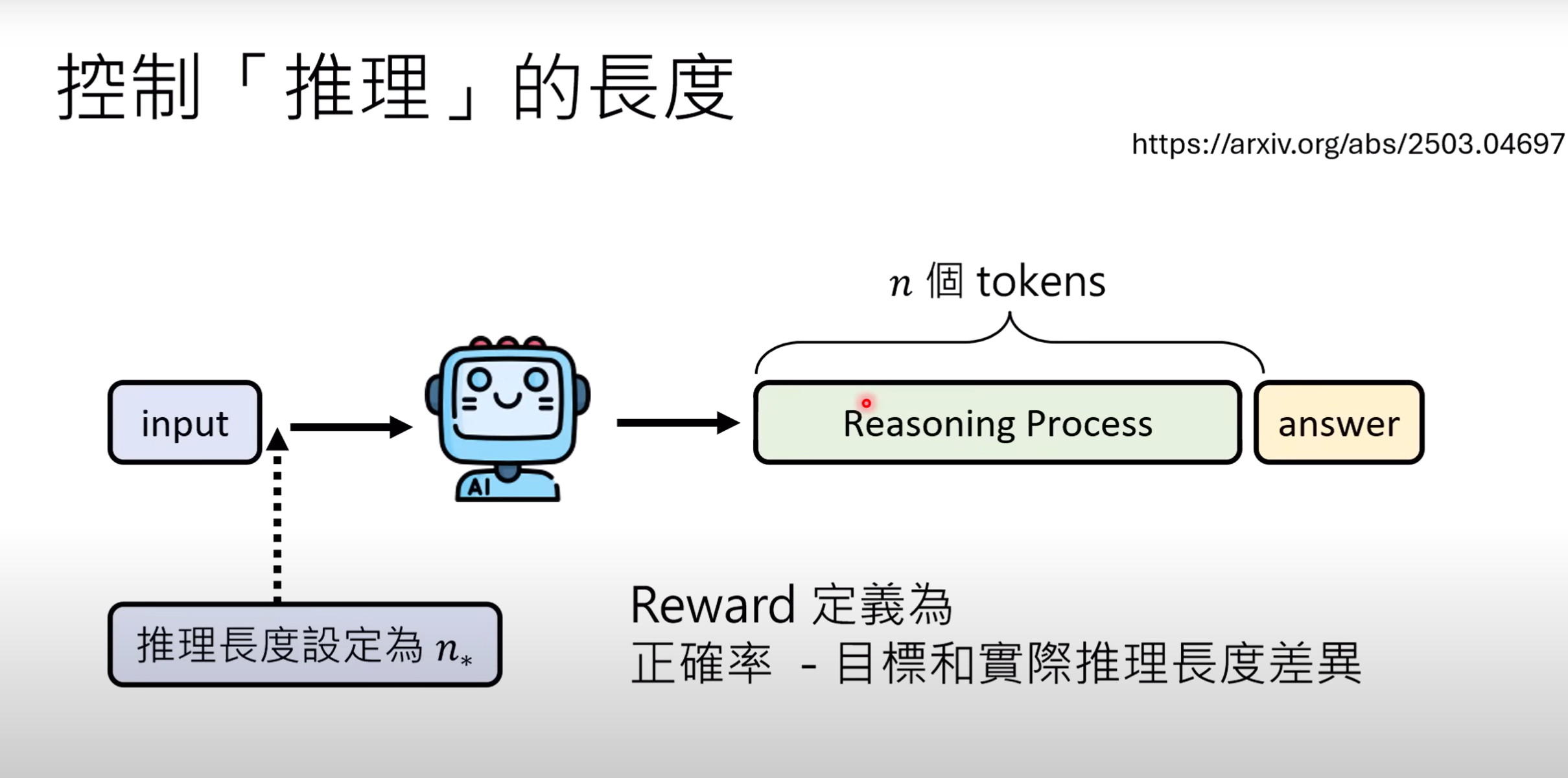
- 在RL的训练过程中,模型只关注答案的正确而不关注reasoning process,可能输出超长的推理过程,那如何控制推理长度呢?一种看法是把长度上限纳入RL的reward中,但某些复杂的问题本身便需要较长的推理长度,定绝对的标准过于死板.可以采用相对的标准,即让模型输出多个答案,取长度平均值,只有低于平均值的答案才能得到正向的reward.
- GSM8K是简单数学问题的资料集,如图论文中将问题中的与解题无关的symbol(如姓名,关系,变量值等)给修改后,多数模型表现出来的正确率均有下降.


- ARC-AGI(
Abstraction and Reasoning Corpus for Artificial General Intelligence)是一种通过抽象题目(如图中找图形规律)来衡量模型推理能力的基准测试集,能有效规避模型“记忆”的问题,真正考验模型习得的推理能力

- Chatbot Arena是一个模型评估平台,其使用Elo Score评比机制:即每个模型$M_K$都有一个战力分数$\beta_K$,模型两两对战时,模型i应该模型j的胜率$E_{i,j}$会取决于战力差距及模型实力外因素$\beta_0$(如图的sigmoid fuction),且实力外因素有时能起到决定性影响
